Kafka_04_Topic和日志
- Topic/Partition
- Topic
- Partition
- 日志存儲
- 存儲格式
- 日志清理
- 刪除
- 壓縮
Topic/Partition
Topic/Partition: Kafka中消息管理的基礎單位
- Topic和Partition并不實際存在(僅邏輯上的概念)
如: Topic和Partition關系
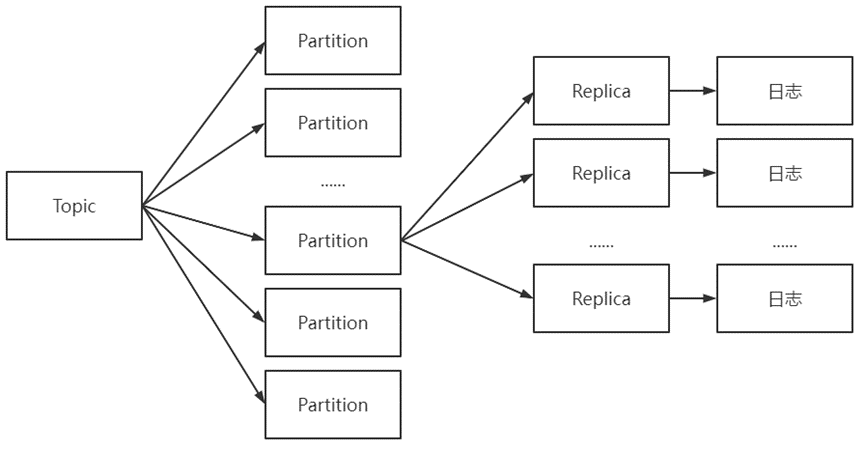
// 每個日志文件可對應多個日志分段, 其還可分為索引、日志存儲和快照等
Topic
Topic(主題): Kafka中消息歸類單位
- Topic管理本質: 管理Topic對應的日志存儲(文件)
- 日志存儲隨機分步于各個Broker以提搞Topic容災性
- 日志存儲數量 = Partition數量 * Replica數量
- 存儲文件格式:
Topic名-Partition名-序列號
// 可通過Kafka自帶kafka-topics.sh腳本完成Topic相關管理
Topic名稱組成: 大小寫字母、數字、點號、連接線、下劃線
- Topic名稱必須含有點號或下劃線(metrics命名時會將前者替換為后者)
- 不建議使用雙下劃線作為前綴(其常為內部Topic格式)
- 創建Topic的本質(交由控制器異步完成)
// ZooKeeper的/brokers/topics/和/config/topics/下創建子節點并寫入Partition分配方案和配置信息
管理Topic須知:
- 創建Topic時Broker需統一是否配置機架信息, 否則會創建失敗
- Topic創建后僅能增加Partition數量(Partition不能被刪除)
- Partition數量變化會影響Key的計算(影響消息順序)
Partition
Partition(分區): 組成Topic的單位(實際存儲消息)
- Partition可有多個副本(leader和follower), 每個副本對應個日志文件
- leader提供讀寫服務, follower副本僅和leader進行數據同步
- leader恢復后重新加入, 則只能為新的follower
優先副本: AR集合中首個副本
- 理想情況下優先副本應是Partition的leader
- Kafka會確保所有Topic的優先副本在集群中均勻分布
- Partition平衡: 通過選舉策略使優先副本選舉為leader副本
// 優先副本選舉的元數據存儲于ZooKeeper的/admin/preferred_replica_election
Partition重分配: Partition重新進行合理的分配
- 當Partition所處的Broker節點下線, Kafka不會自動進行故障轉移
- Kafka集群中增加新Broker節點時, 該節僅能分配到新創建的Partition
- 本質:部分Partition增加新副本, 并從剩余Partition的副本中拷貝數據
- Partition重復配過程中需保證有足夠的空間(完成后自動刪除原有數據)
// 建議分為多個小批次執行Partition重分配, 并重啟預下線的Broker
Partition數量與吞吐量關系:: 限定范圍內增加Partition數量可增加吞吐量
- 若無休止增加Partition數量, 超出限定范圍后吞吐量反而下降
- Partition數量有上限(過多會導致Kafka進程崩潰)
- Partition也是最小的并行操作單位
日志存儲
日志(Log): Partition對應的物理存儲
- 日志以目錄方式存儲多個LogSegment
- 日志的目錄命名格式:
Topic名稱-Partition名稱 - 數據均以追加方式寫入日志, 且以特定順序進行追加
如: 日志存儲關系
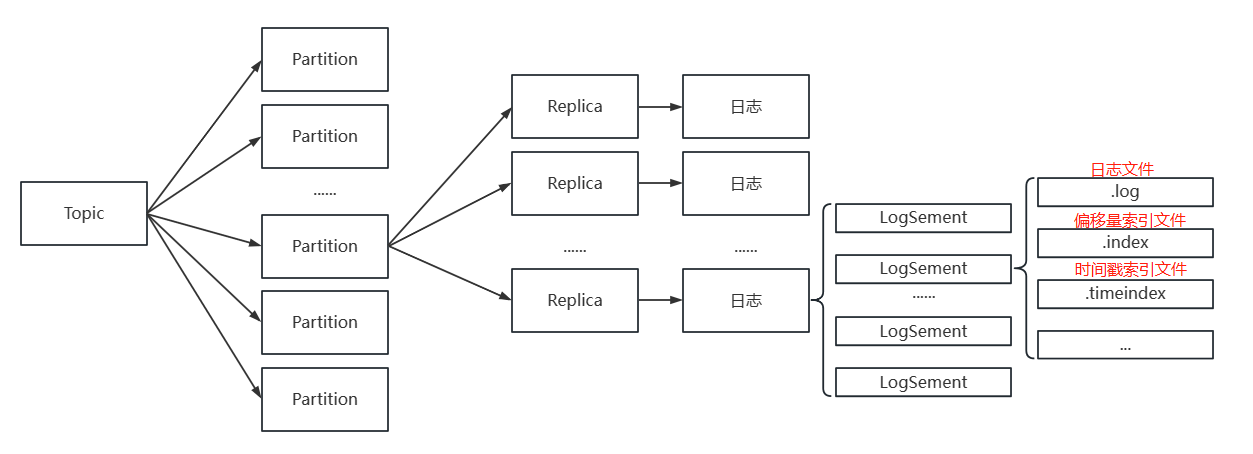
// LogSegment還包含.deleted、.cleaned、.swap等后綴文件
LogSegment(日志分段): 組成日志的基礎單位
- 每個LogSement必須有個日志文件和兩個索引文件
- 日志的最后個LogSegment才可執行寫入, 其他僅存儲數據
- BaseOffset(基準偏移量): 每個LogSegment中首個消息的偏移量
- 文件均以BaseOffset格式進行命名(固定為20位數字, 用0填充多余位)
// BaseOffset是64位長整型數據, 其可得知前個LogSegment的數據量
日志索引: 稀疏索引實現消息的快速檢索
- 稀疏索引達到指定大小后才建立索引(不保證Record均有對應的索引項)
- 稀疏索引通過
MappedByteBuffer將索引文件映射到內層中 - 通過二分定位小于指定偏移量的最大偏移量
- 各索引均嚴格單調遞增
存儲格式
存儲格式: 日志存儲在硬盤的格式
- 日志的存儲格式決定其占用空間大小和檢索速率
- 日志的存儲格式演進為3個版本: v0(0.10.0)、v1(0.11.0)、v2
如: 日志存儲格式
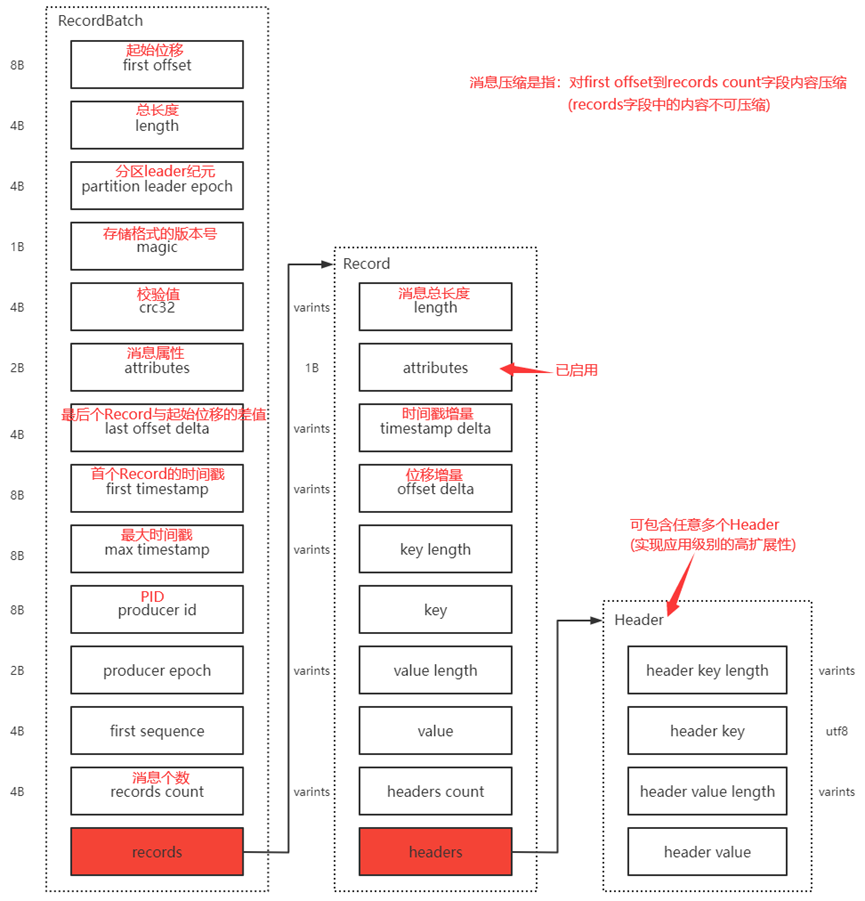
// Varints(變長整型): 使用任意多個字節序列化記錄整數(特定范圍減少空間)
消息壓縮: 將RecordBatch壓縮成單個Record
- 壓縮生成的消息記為外層消息(反者為內層消息)
- 外層消息的key為null, 而value為內層消息(偏移量查找)
- 內層消息的偏移量均從0開始(使用時Broker會進行轉換計算)
如: 外層消息和內層消息的偏移量
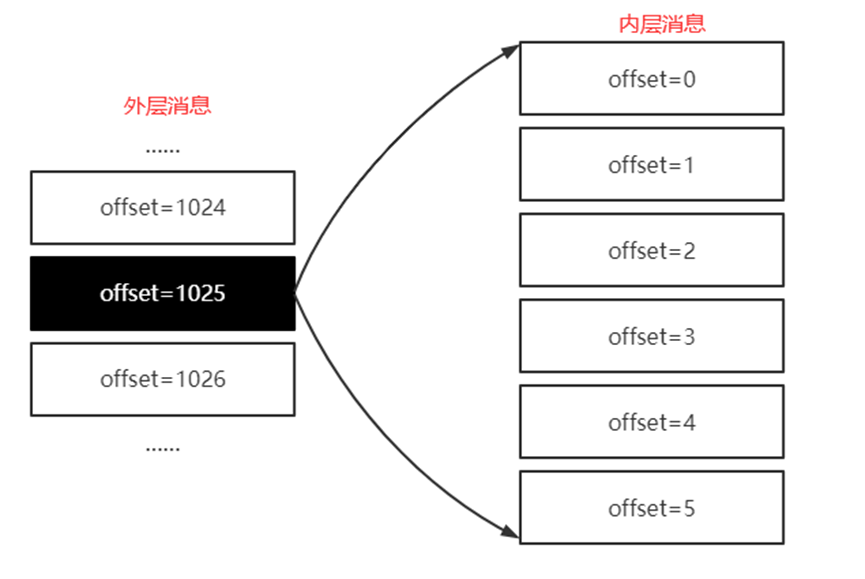
// 外層消息存儲的是內層消息中最后條消息的絕對位移(相對于Partition而言)
日志清理
日志清理: Kafka對日志的維護
- 日志清理策略分為: 刪除、壓縮
- 日志清理的粒度最細可為Topic級別
- 可同時指定刪除和壓縮為日志清理的策略
刪除
刪除(Delete): 刪除不符合特定條件的LogSegment
- 刪除依據分為: 時間、文件大小、日志的起始偏移量
- Broker啟動時會同時啟動個線程周期性檢測并刪除特定LogSegment
- 刪除線程會基于依據選擇出可被刪除的LogSegment(deletableSegment)
日志刪除的大致流程:
- 從日志對象中所維護的LogSegment跳躍表中移除待刪除的LogSegment
- 將所有待刪除的文件添加
.deleted后綴(包括索引文件) - 統一交由延遲刪除線程處理(默認1m)
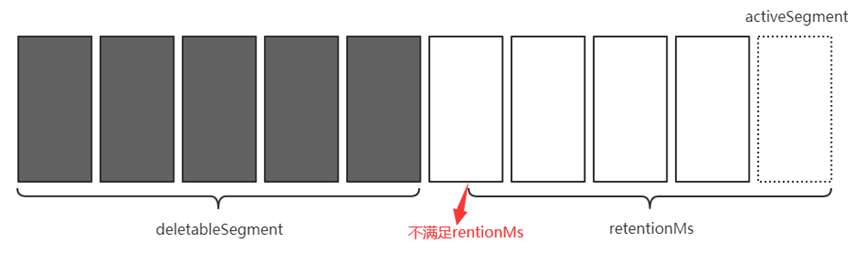
基于時間刪除: 每個LogSegment擁有過期時間
- 根據LogSegment的最大時間戳(最后條消息)
- 若最后條消息的時間戳字段小于0, 則根據最近修改時間
- 若所有LogSegment均滿足刪除條件, 則在刪除前創建activeSegment
如: 基于時間的日志刪除(只要最大時間戳未過期就不會被刪除)
基于文件大小: 每個LogSegment的限定大小
- 基于文件大小又可分為:日志大小、LogSegment大小
- 若基于日志大小, 則超出限定時默認從頭開始刪除LogSegment
如:基于大小的日志刪除

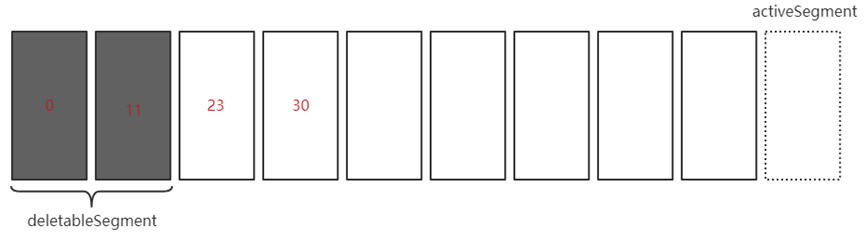
基于日志的起始偏移量: 下個LogSegment的BaseOffset是否小/等于起始偏移量
- 刪除線程會逐個遍歷LogSegment以判斷BaseOffset是否滿足
- 日志起始偏移量常為首個LogSegment的BaseOffset
如: 基于日志的起始偏移量(假設起始偏移量為25)
壓縮
壓縮(Compact): 將具有相同Key的消息僅保留最后個版本的Value
- 壓縮后生成新的LogSegment, 消息的物理位置不會改變
- 壓縮后的偏移量不再連續(不影響日志的檢索)
- 壓縮前后的消息可分為: clean和dirty
- activeLogSegment不參與壓縮
如:日志壓縮時其構成部分

// 日志的cleaner-offset-checkpoint文件記錄每個Partition的已清理偏移量
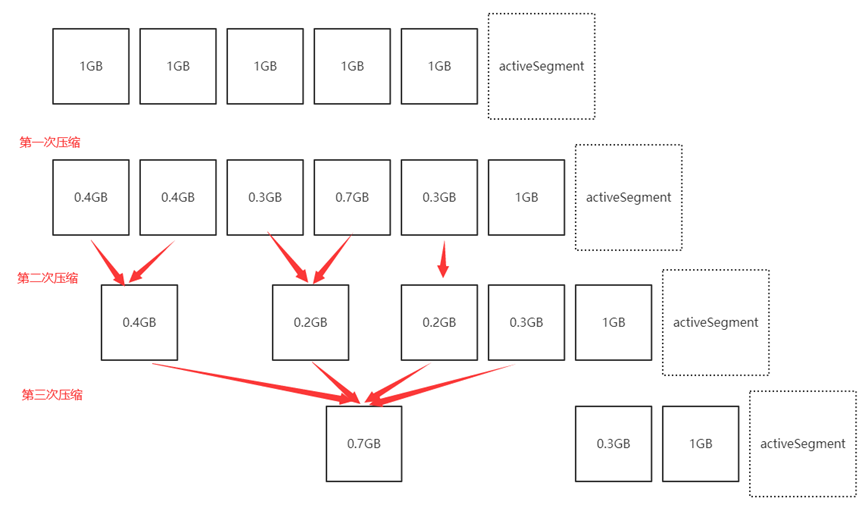
日志壓縮時大致流程:
- 日志的污濁率觸發壓縮操作
- 壓縮線程遍歷兩次日志(獲取Key和判斷)
- 對于壓縮LogSegment的進行分組(防止過多小文件)
- 將LogSegment組中需保留消息存儲于
.clean后綴的臨時文件 - 對日志進行壓縮, 在壓縮完成后將
.clean臨時文件后綴改為.swap - 刪除被壓縮的LogSegment, 并將
.swap后綴去除(變為可用LogSegment)
// LogSegment組的大小不可超過LogSegment的限定大小
如: 多次壓縮的日志文件
// ActiveSegment(活躍的日志分段): 可執行寫入操作的LogSegment

》)
)










——哈希表+區間)
)



