
本期一諾sec關注深度學習系統安全問題,推薦一篇來自ICML 2018會議論文Synthesizing Robust Adversarial Examples。論文鏈接http://proceedings.mlr.press/v80/athalye18b.html。
深度模型對于對抗樣本具有高度的脆弱性,這已經是得到大家印證的事實。自從2016年以來,對深度學習模型的對抗樣本攻擊和防護的研究工作越來越多,光掛在Axiv上等待評審或發表的論文不下百篇。研究者中不乏生成對抗網絡(GAN)之父Ian Goodfellow、Dawn Song等機器學習和安全領域的大佬。這篇來自ICML 2018上的工作:“Synthesizing Robust Adversarial Examples”,作者分別是Anish Athalye,Logan Engstrom,Andrew Ilyas和Kevin Kwok,來自MIT和LabSix。
一、論文的引入
所謂對抗樣本,就是對深度學習器產生對抗輸入的樣本:例如對一個圖像,添加一些細小的擾動使得分類器誤分類,但是人肉眼卻不能看出這些擾動,這樣的樣本就是對抗樣本。對抗樣本攻擊就是針對深度學習器生成或者合成靠譜的(誤分類成功率高的)對抗樣本。研究對抗樣本的合成是非常有意義的:一方面找到了對抗樣本就驗證了深度學習器的脆弱性,找到了他的死穴,可以搞些破壞;另一方面為如何防護對抗樣本攻擊提供了攻擊場景和攻擊模型。?論文作者之一Anish Athalye在接受QZ采訪時表示,現在有很多使用機器學習的欺詐檢測系統,如果能故意修改輸入,讓系統無法檢測出欺詐交易,那么就可能造成財務損失。
以圖像分類為例,大部分生成對抗樣本的工作都是直接在已有的圖像上添加噪聲,然后直接送給分類器或者打印出來通過攝像頭送給分類器。有工作證明[1],這樣產生的對抗樣本是不夠魯棒的,也就是說對物理世界分類器的攻擊不管用!原因是什么呢?作者認為,物理世界中的攝像頭是通過多種視角(viewpoint)來采集物體的圖像,并且受到光照、攝像頭本身的噪聲等自然因素的影響,使得很多方法生成的對抗樣本在經過這些影響(相當于小的變換)之后,失去了對抗的屬性。?
針對物理世界深度分類器進行魯棒的對抗樣本攻擊的工作很少,已有的兩個工作也是合成2D的對抗樣本,本質上是通過原始圖像上的仿射變換來“近似”多視角。但是,對物理世界攝像頭看到的3D物體,要想保持合成樣本的對抗屬性,必須經過更復雜的變換:例如3維旋轉。?
針對上述挑戰,該論文提出了一種通用框架,叫變換期望EOT(Expectation Over Transformation),這個框架可以在變換的整個分布上面保持對抗屬性。基于這個框架,該論文專門討論3D對抗樣本的生成方法。最后,作者們真的用3D打印機打印了合成的3D對抗樣本,并成功欺騙了一些深度學習器,證明了這種方式確實靠譜!
二、模型介紹
先來看看原來的對抗樣本合成方式。在深度分類器的白盒假設下(分類器的預測分布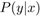 和梯度
和梯度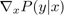 都可以拿到),嘗試利用原始樣本
都可以拿到),嘗試利用原始樣本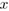 來構造對抗樣本
來構造對抗樣本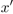 ,可以通過在距離原始圖像為
,可以通過在距離原始圖像為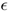 的球上,最大化目標類別
的球上,最大化目標類別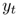 的條件分布的對數似然函數:
的條件分布的對數似然函數:
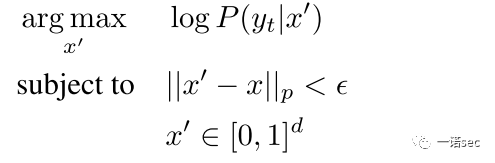
這種方法構造的對抗樣本已經被證實在物理世界的實驗中是失敗的。本文提出的變換期望EOT方法的主要思想是將物理世界的影響考慮到優化過程中去,而不是僅僅考慮樣本。EOT假設變換函數 采樣自一個已知的分布
采樣自一個已知的分布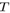 (包括隨機旋轉、平移、加噪等,甚至包括紋理的3D渲染),期望通過變換作用之后,對抗樣本和原始樣本之間的距離的期望仍然比較小。在這個約束下,去最大化對數似然函數的期望,即:
(包括隨機旋轉、平移、加噪等,甚至包括紋理的3D渲染),期望通過變換作用之后,對抗樣本和原始樣本之間的距離的期望仍然比較小。在這個約束下,去最大化對數似然函數的期望,即:
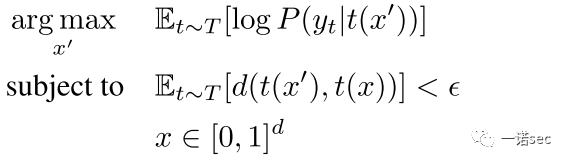
具體優化方法采用的是隨機梯度下降法,在每一次迭代中獨立的采樣變換來近似得到期望值的梯度。
緊接著,作者討論了在EOT框架下合成2D和3D對抗樣本的具體方法。打印一個合成的2D對抗樣本并采集其圖像的過程,等價于一系列隨機變換 ,并且這種變換很容易求導,因此2D場景的問題很容易解決。為了合成3D對抗樣本,論文提取現有3D物體的紋理(色譜)作為,然后選擇一個變換函數
,并且這種變換很容易求導,因此2D場景的問題很容易解決。為了合成3D對抗樣本,論文提取現有3D物體的紋理(色譜)作為,然后選擇一個變換函數 ,最后再渲染這個3D物體。變換函數包括渲染、光照、旋轉、平移以及視角映射等。問題是EOT需要是可微的,當然這中渲染也可以通過
,最后再渲染這個3D物體。變換函數包括渲染、光照、旋轉、平移以及視角映射等。問題是EOT需要是可微的,當然這中渲染也可以通過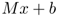 來代替。在優化的過程中采用了LAB顏色空間中的距離來代替歐式距離,同時采用拉格朗日松弛形式,最終的優化目標是:
來代替。在優化的過程中采用了LAB顏色空間中的距離來代替歐式距離,同時采用拉格朗日松弛形式,最終的優化目標是:
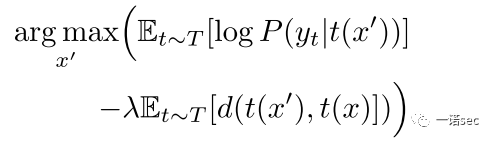
三、實驗和評價
論文分別針對2D和3D對抗樣本合成做了實驗。攻擊的目標是TensorFlow中的深度分類器Inception-V3,該分類器在ImageNet數據集上top-1的精確度是78%。評價指標采用的是對抗度(adversariality)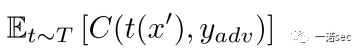 ,即在測試集上生成的對抗樣本有多少成功欺騙了InceptionV3分類器。
,即在測試集上生成的對抗樣本有多少成功欺騙了InceptionV3分類器。

第一個結果是合成2D對抗樣本。我們從上圖可以看到,合成樣本的平均對抗度達到了96.4%,效果還是非常不錯的。例如,下圖中第二行是生成的對應第一行的對抗樣本,成功的讓InceptionV3認為是食蟲鳥,而不是波斯貓。

接下來是3D的情況。下圖可以看到3D對抗樣本也能達到83.4%的平均對抗度,雖然比2D有所下降但還是不錯的。但是這個結果是通過合成的3D對抗樣本,再渲染成2D圖像送給分類器的。

如何說明物理世界的場景中本文提出的方法有效呢?最有意思的亮點來了:作者選取了兩類物體(烏龜和籃球),采用3D打印機分別打印了一些不加噪聲的原始3D物體,以及一部分合成的對抗性的3D物體,然后通過多視角分別提取100張照片送給InceptionV3分類器。結果發現InceptionV3對原始3D物體識別率是100%,但是對對抗樣本攻擊成功的對抗性還是很大的,特別是對烏龜類對抗性達到了82%,具體結果看下表。


(圖中紅色方框都是攻擊成功的情景,InceptionV3將“烏龜”錯誤的分到了“步槍”類。)
四、總結
論文提出了一種通用的對抗樣本合成框架,可以有效的應對虛擬世界到物理世界中各種因素的影響,達到了欺騙物理世界中深度學習分類器的目的。當然,筆者認為論文還是有很多局限性的,論文作者也做了一些討論,例如要想使構造的對抗樣本更魯棒,就需要一個更大的給定變換分布,否則就不太管用了;但是另一方面,定變換分布越大,構造的樣本與原始樣本的差距越大,越難構造出“讓人感覺不到”的對抗樣本。總之,本論文不失為一篇針對物理模型的對抗樣本攻擊的佳作。
參考文獻
[1]?Lu, J., Sibai, H., Fabry, E., and Forsyth, D. No need to worry about adversarial examples in object detection in autonomous vehicles. 2017. URL https://arxiv. org/abs/1707.03501.
請關注公眾號一諾sec,獲取更多資訊!

? ? ? ?一諾sec公眾號由衷歡迎有興趣的朋友積極投稿,展示才華,擴大自己及其團隊的影響力。來稿以網絡安全研究方面的內容為首選,各種科研相關的新聞、信息、評論,甚至文學作品,都非常歡迎。
? ? ? ?歡迎將您的來稿或者建議發送至:
e_novel_security@126.com

)










)






