
“受盡苦難而不厭,此乃修羅之路”
本文技術含量過低,請謹慎觀看
????之前用R語言的Rcurl包做過爬蟲,給自己的第一感覺是比較費勁,看著看著發際線就愈加亮眼,最后果斷丟之。不過好的是和python爬取原理基本一致,且聽說python擁有大量網頁解析庫,結合MongoDB等存儲數據庫,爬蟲效率大大調高,所以按捺不住心中之寂寞,故爬之。
????在學習了幾天基礎知識后,今天就做了第一次python爬蟲嘗試,目標是大多數菜鳥入門必爬的貓眼電影Top榜單數據。可能大家爬得多了,貓眼的反爬機制在大伙的錘煉下漸漸成熟,我知道的一些方法比如使用代理、偽造headers或者是用selenium驅動瀏覽器都進不去。查了一些資料,目前只發現了使用登錄網站后的cookies才能進去,只是這樣貓眼會知道是你小子在爬它。
????好的,下面進入正題:
1. 網頁分析
??? Top100榜單,每一頁顯示10個,不同網頁的規律是網址末尾offset = 0,10,20,30……90。查看源碼發現每部電影都是在一個dd標簽里。
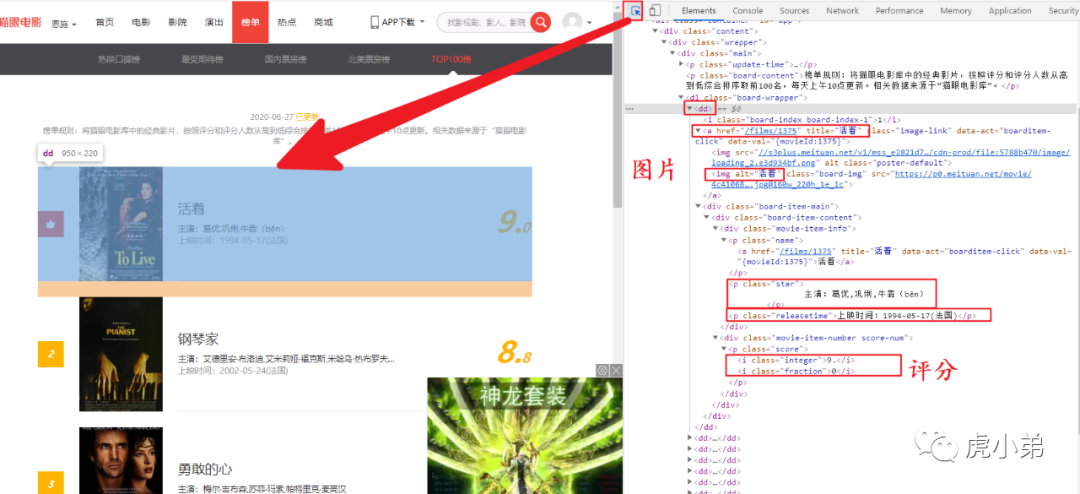
2. 請求單頁內容
import requestsfrom requests.exceptions import RequestException #異常處理import re #正則表達式import json #將字典轉為字符串from multiprocessing import Pool #從multiprocessing引入進程池def get_one_page(url):try: headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}????????cookies?=?{……}#此處復制自己的cookies????????response?=?requests.get(url,headers=headers,cookies=cookies)if response.status_code == 200: #狀態碼為200表示請求成功return response.text #獲取源碼return Noneexcept RequestException: #這里我們只定義了父類異常,你也可以再詳細一點return None3.?解析html
本例用正則表達式的方法:def parse_one_page(html): #解析html代碼 pattern = re.compile('.*?board-index.*?>(\d+).*?src="(.*?)".*?name">+'.*?>(.*?)(.*?)(.*?).*?integer">(.*?)'+'.*?fraction">(.*?).*?',re.S) items = re.findall(pattern,html)#print(items) #此時以列表形式存儲,每個元素是一個元組for item in items: #變為好看的字典形式yield{ #變成一個生成器,并且理解為一個return'index': item[0],'image': item[1],'title': item[2],'actor': item[3].strip()[3:],#去掉換行符,且不要“主演:”'time': item[4].strip()[5:], #去掉換行符,且從第5個位置輸出'score': item[5]+item[6] #評分是將兩個部分拼接 }def write_to_file(content): #content是一個字典的形式with open("result.txt",'a',encoding= 'utf-8') as f: #'a'表示往后追加 f.write(json.dumps(content, ensure_ascii=False)+'\n') #json.dumps將其轉為字符串的形式,字典的中括號也會成為字符串 f.close()def main(offset): url = "http://maoyan.com/board/4?offset="+str(offset) html = get_one_page(url) #獲取源碼#print(html) #打印源碼for item in parse_one_page(html):#print(item) #輸出10個字典 write_to_file(item) #寫入文件if __name__ == "__main__": #這個__main__和上面定義的main函數沒有關系 #for i in range(10): # main(i*10) #map(main,[i*10 for i in range(10)]) #不理解為什么這句沒有得到結果 pool = Pool() pool.map(main, [i*10 for i in range(10)])
Top100電影數據

)




![angularjs 元素重復指定次數_[LeetCode] 442. 數組中重復的數據](http://pic.xiahunao.cn/angularjs 元素重復指定次數_[LeetCode] 442. 數組中重復的數據)








類的繼承示例)



