
類似SVM,決策樹也是非常多功能的機器學習算法,可以分類,回歸,甚至可以完成多輸出的任務,能夠擬合復雜的數據集(比如第二章的房價預測例子,雖然是過擬合了=。=)
決策樹也是很多集成學習的組件,比如隨機森林和梯度提升樹等等
決策樹的訓練和可視化
還是以熟悉的iris數據集為例:
首先訓練一個決策樹模型,然后做一些可視化,使用export_graphviz()方法,通過生成一個叫做iris_tree.dot。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)from sklearn.tree import export_graphviz
export_graphviz(tree_clf,out_file=image_path("iris_tree.dot"),feature_names=iris.feature_names[2:],class_names=iris.target_names,rounded=True,filled=True)可以利用graphviz package(http://www.graphviz.org/) 中的dot命令行,將.dot文件轉換成 PDF 或 PNG 等多種數據格式。
$ dot -Tpng iris_tree.dot -o iris_tree.png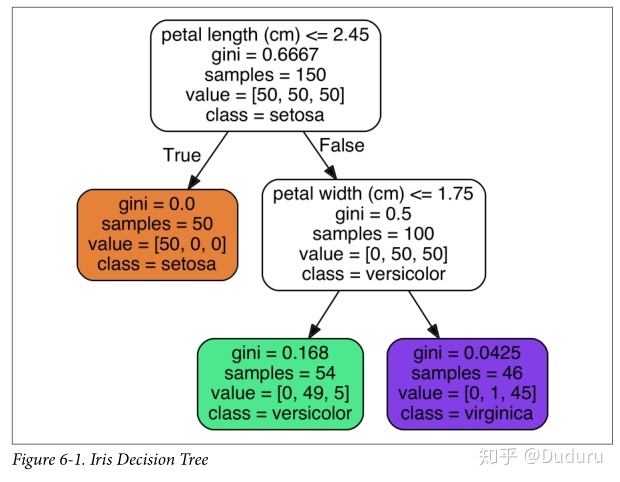
我們將從這個圖開始,簡單分析決策樹是怎么樣工作的
從根節點出發,首先要判斷花瓣長度是否小于 2.45 厘米,如果小于移動到左子節點,會判斷這個花是Iris-Setosa。如果大于2.45cm,會移動到右子節點,判斷寬度是否小于等于1.75cm
,如果是的,會到它的左子節點,判斷為versicolor,否則到右子節點,判斷為,virginica。
過程是非常清晰簡單的
決策樹的眾多特性之一就是, 它不需要太多的數據預處理, 尤其是不需要進行特征的縮放或者歸一化。
圖中還有一些屬性
samples屬性統計出它應用于多少個訓練樣本實例。如,開始有150組例子value屬性告訴你這個節點對于每一個類別的樣例有多少個。如:右下角的節點中包含 0 個 Iris-Setosa,1 個 Iris-Versicolor 和 45 個 Iris-Virginica。Gini屬性用于測量它的純度:如果一個節點包含的所有訓練樣例全都是同一類別的,我們就說這個節點是純的(Gini=0)。基尼不純度的公式在下面,具體的用處我們稍后再說。

Sklearn 用的是 CART 算法, CART 算法僅產生二叉樹(是或否)。然而,像 ID3 這樣的算法可以產生超過兩個子節點的決策樹模型。
下面的圖展示了決策邊界,第一次的邊界是在length=2.45,左面是純的,不用再分了。右面是不純的,再在width=1.75做了分割,如果樹高可以為3的話,會繼續分割下去(如虛線)
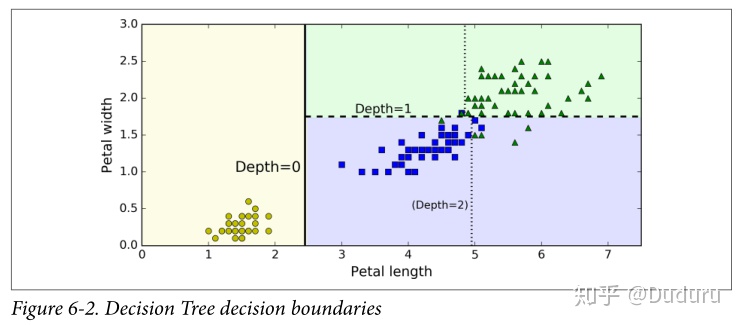
從圖中可以看出,決策樹是典型的白盒模型,可以提供清楚的分類依據。分類具有很強的可解釋性
另外,決策樹可以很容易的給出分類的概率
比如你發現了一個花瓣長 5 厘米,寬 1.5 厘米的花朵,對應上圖6-1的綠色那一塊
Iris-Setosa 為 0%(0/54),Iris-Versicolor 為 90.7%(49/54),Iris-Virginica 為 9.3%(5/54)
測試結果完全符合預期
>>> tree_clf.predict_proba([[5, 1.5]])
array([[ 0. , 0.90740741, 0.09259259]])
>>> tree_clf.predict([[5, 1.5]])
array([1])CART樹算法
SkLearn 用分裂回歸樹(Classification And Regression Tree, CART)算法訓練決策樹
原理非常簡單
每次分裂都要找到特征k和閾值tk(比如特征=寬度,閾值=2.45),CART會尋找一個分裂方法,讓分裂后兩邊的基尼不純度按照節點數量加權盡可能的小,損失函數為

然后遞歸的,對于子集,子集的子集,按照同樣的方法進行分裂
可以看出,每次分割是貪心算法,不能保證這是全局上最好的解。這是因為找到最優樹是一個 NP 完全問題,需要超出多項式的復雜度,我們需要找一個合理的(而不是最佳的)方案
CART停止的條件是達到預定的最大深度之后將會停止分裂(由max_depth超參數決定)
,或者是它找不到可以繼續降低不純度的分裂方法的時候(所有節點都是同一個類了)。幾個其他超參數(之后介紹)控制了其他的停止生長條件。
復雜度計算
建立好決策樹后,預測的速度是非常快的。決策樹是一個近似平衡的樹,大概只需要O(logm)的復雜度(m樣本數),因此是非常快的。
但是訓練上因為要比較多種的分裂可能,有了O(nmlogm)的復雜度。過程是比較慢的。對于小型的數據集(少于幾千),可以用預排序來加速(presort = True)但是大數據反而會降低速度。
基尼不純度/信息熵
通常,算法使用 Gini 不純度來進行檢測, 但是你也可以設置為"entropy"來使用熵不純度進行檢測。
熵的概念是源于熱力學中分子混亂程度的概念,當分子井然有序的時候,熵值接近于 0。后來推廣到信息論中,當所有信息相同的時候熵被定義為零。
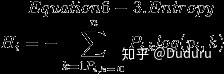
在機器學習中,熵經常被用作不純度的衡量方式,當一個集合內只包含一類實例時, 我們稱為數據集的熵為 0。 熵的減少通常稱為信息增益。
通常來說Gini不純度和信息熵的結果是類似的,基尼指數計算稍微快一點,所以這是一個很好的默認值。但是,也有的時候它們會產生不同的樹,基尼指數會趨于在樹的分支中將最多的類隔離出來,而熵指數趨向于產生略微平衡一些的決策樹模型。
正則化
決策樹不對數據做任何的假設,如果任由決策樹無限制的擬合數據,必然會造成嚴重的過擬合。
這樣的模型稱為非參數模型,沒有參數數量的限制,可以自由的去擬合數據。線性回歸等這類有參數的模型,自由度受到一定的限制,本身就有一些抵御過擬合的能力(也增加了欠擬合的風險)
除了限制樹的高度可以顯著的限制模型過擬合,SKlearn還有一些其他的正則化相關的超參數:
min_samples_split(節點在被分裂之前必須具有的最小樣本數)min_samples_leaf(葉節點必須具有的最小樣本數)min_weight_fraction_leaf(和min_samples_leaf相同,但表示為加權總數的一小部分實例)max_leaf_nodes(葉節點的最大數量)max_features(在每個節點被評估是否分裂的時候,具有的最大特征數量)
增加min_開頭的超參數或者減小max開頭的超參數會讓模型更正則化
還有一些其他的決策樹算法采用后剪枝形式,先生成足夠大的樹,再刪去一些不必要的節點
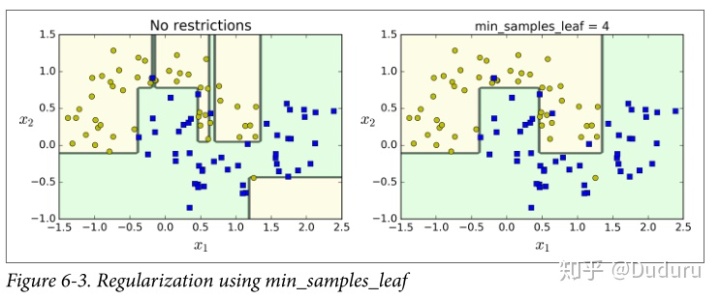
下圖展示了正則化對決策邊界的影響,左面顯然是過擬合了。
回歸
決策樹也可以處理回歸的問題
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)得到了一棵這樣的樹
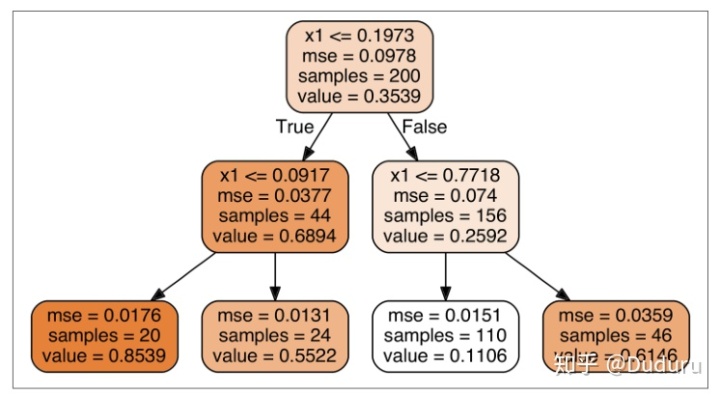
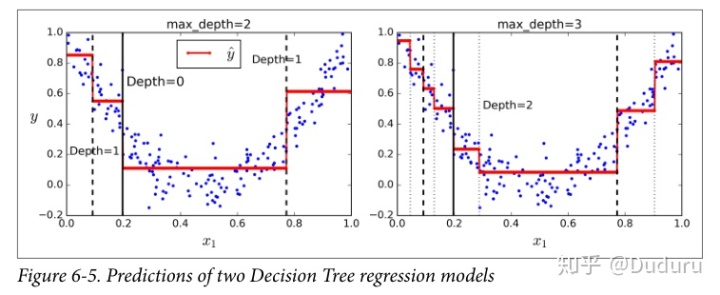
可以看出,和分類相比,區別在于,不再最小化不純度了,而是最小化MSE

直觀的看,每一個子集的紅線代表了value值,即這個子集的平均
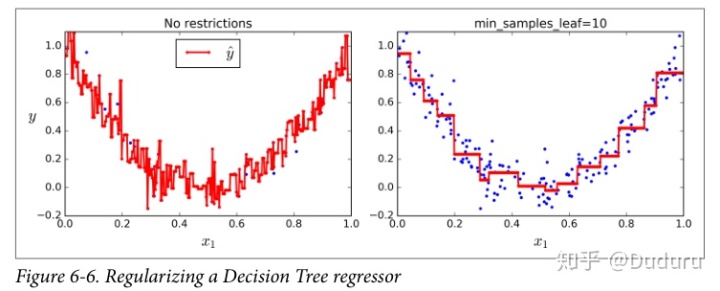
同樣,正則化可以帶來幫助
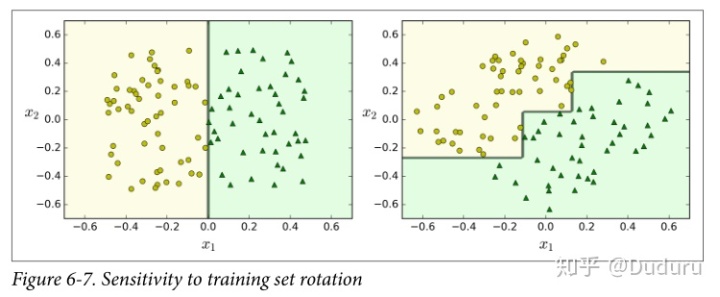
不穩定性
決策樹是一類非常強大的模型,但是也有一些局限性
首先,決策樹的決策邊界和坐標軸是垂直的,這樣的性質導致對數據的旋轉很敏感,如圖,左右兩個雖然都可以分割開,但是右面的泛化顯然不如左邊好(可以用PCA來解決這樣的問題,見第八章)
其次,決策樹對一些數據的微小變化可能非常敏感,一點點的區別可能導致決策邊界截然不同的,而且,SKlearn中許多方法都有偶然性,除非設置了隨機種子,這也會帶來許多不穩定性。下一章中將會看到,隨機森林可以通過多棵樹的平均預測值限制這種不穩定性








方法(帶示例))









)
