一、概述
WMDA是58自主開發的用戶行為分析產品,同時也是一款支持無埋點的數據采集產品,只需要在第一次使用的時候加載一段SDK代碼,即可采集全量、實時的PC、M、APP三端以及小程序的用戶行為數據。同時,為了滿足用戶個性化的數據采集需求,在無埋點之上,WMDA又提供了手動埋點的數據采集方式。
WMDA支持的統計、分析功能主要包括:
- “概覽”和“實時”模塊用來監控網站的流量情況;
- “圈選”定義重要的指標;
- “單圖”和“看板”可以統計不同維度、時間下指標的頁面訪問量和用戶量等數據;
- “漏斗”和“智能路徑”用于分析不同指標下的轉化率;
- “留存”可以基于不同維度、分群來考察網站的用戶流失率,分析用戶的忠誠度;
- “用戶細查”和“用戶分群”用于分析所關心條件下的用戶群體以及相關的用戶行為明細。
以上簡單的介紹了WMDA功能模塊,接下來側重于WMDA數據端的架構以及相關大數據技術棧的實踐。
二、架構設計
在架構上,WMDA遵循標準的數據分析模型,將整體的架構分成數據采集、數據傳輸、數據建模/存儲、數據統計/分析和數據可視化五個部分。架構如下圖所示:
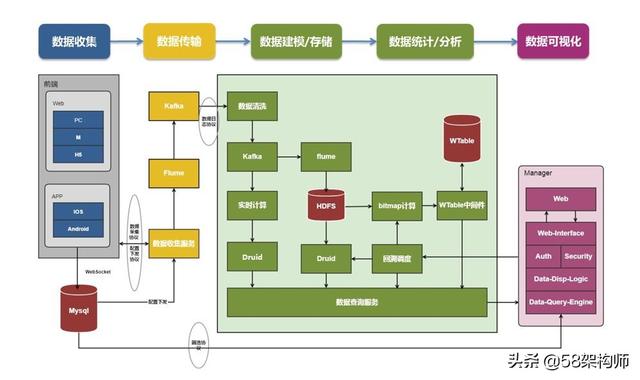
數據采集:58的業務方覆蓋PC、M、APP三端以及小程序。WMDA在數據收集階段為PC、M、H5、提供SDK完成數據采集,在APP端提供IOS SDK和Android SDK完成數據采集,小程序也有相應的SDK來完成數據采集。
數據傳輸:主要包括數據收集服務完成前端上報數據的信息補全、臟數據過濾、設備標識等,最后將數據格式化之后落地存儲,通過Flume收集到Kafka中,完成實時總線和離線總線的拆分。
數據建模/存儲:后端收集上來的數據經過ETL的清洗,將上報的數據格式化之后保存在HDFS上,供后續分析使用。同時Kafka分發一份數據到Spark Streaming中,進行實時數據分析。
數據統計/分析:除了Spark Streaming的實時分析外,落地到HDFS上的數據在Kettle的調度下,由OLAP子系統、Bitmap子系統、分群計算子系統、智能路徑計算子系統完成單圖、漏斗、留存、分群、智能路徑的最終計算。
三、實時分析系統
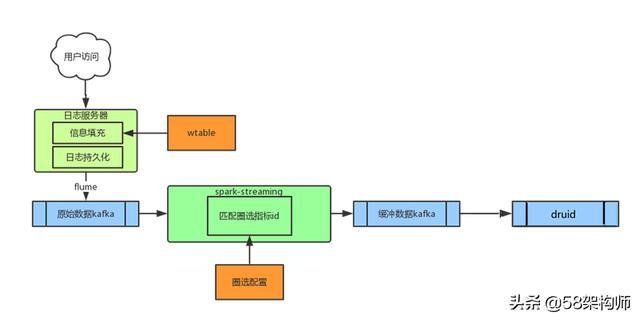
實時分析系統用于解決用戶監控網站、APP實時流量需求,采用SparkStreaming+Druid來實現。實時ETL程序中設置5s為Spark Streaming處理批次間隔,同時將圈選配置信息在實時ETL程序中定義為廣播變量,完成指標id的實時匹配,最后將數據通過緩沖kafka攝入到Druid中。
四、離線分析系統
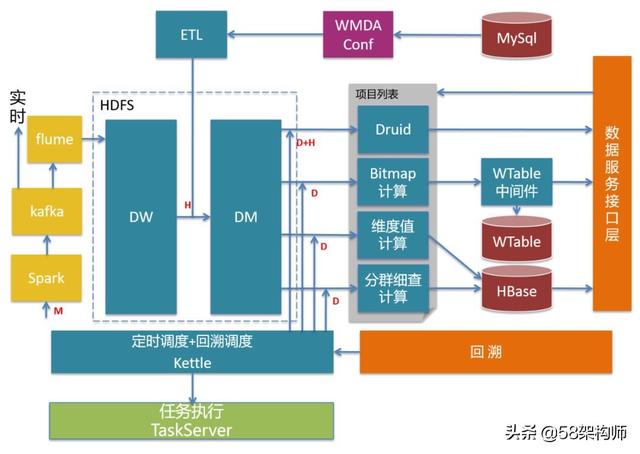
離線分析系統主要完成單圖、漏斗、留存、智能路徑、分群等數據分析工作,是WMDA的核心組成,也是數據建模/存儲,數據統計/分析的具體實踐。
基礎數倉:使用HDFS作為存儲系統,DW+DM+DA是標準的數據中臺角度的數倉分層,同時基于基礎事件模型(Event)搭建基礎數倉。
Hive:完成基礎數倉的核心ETL。
Spark+ETL:完成數據圈選規則匹配、臟數據的過濾和標準日志格式化。
離線計算集群:包括OLAP系統、Bitmap計算系統、分群計算系統、智能路徑計算系統,主要完成單圖、漏斗、留存、分群、智能路徑相關計算工作。
Kettle:負責離線計算集群的調度。
TaskServer:任務執行系統,負責執行由Kettle調度的Hive sql任務、MapReduce任務。
數據服務接口層+回溯接口層:供可視化服務獲取數據和指標變更回溯任務的觸發。
離線計算邏輯復雜,保證系統容錯性尤為關鍵,WMDA離線和實時數據系統都遵循Lambda架構,保證了系統較好的容錯特性。
4.1 基于Kettle的任務調度系統
Kettle是基于java開源的ETL工具集,可以在windows、Linux、Unix上運行,數據抽取高效穩定。通過可視化界面設計ETL流程,無需代碼去實現。在Kettle中,有兩種基本的腳本文件job和transformation,job是完成整個工作流的控制,transformation完成針對數據的基礎轉換。在job下的start模塊,有一個定時功能,可以每日、每周等方式實現對ETL任務的定時調度。
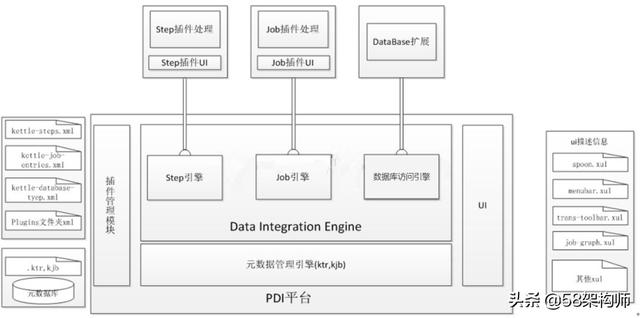
Kettle體系結構分為Kettle平臺、各類插件,其中Kettle平臺是整個系統的基礎,包括UI、插件管理、元數據管理和數據集成引擎。UI顯示Spoon這個核心組件的界面,通過xul實現菜單欄、工具欄的定制化,顯示插件界面接口元素。元數據管理引擎kjb、ktr以及一些元數據信息,插件通過該引擎獲取基本信息。插件管理引擎主要負責插件的注冊。數據集成引擎負責調用插件,并返回相應信息。
Kettle是眾多“可供插入的地方”(擴展點)和“可插入的東西”(擴展)共同組成的集合體。在Kettle中不管是以后的擴展還是系統集成的功能,本質上都是插件,管理的方式和運行機制是一致的。系統集成的功能也均是實現了對應的擴展接口,只是插接的方式略有不同。
Kettle的擴展點包括step插件、job entry插件、Database插件、Partioner插件、debugging插件等。
在Kettle中一個job代表ETL控制流中的一項邏輯任務。Job會按照連線的方式順序執行,每個job產生一個執行結果,作為其他分支上job的條件。同時數據會從一個entry組件傳遞到另一個entry組件,并在entry組件中進行相應的處理。
在Kettle負責調度各個子計算系統ETL任務的同時,TaskServer負責任務的執行,這樣使得任務的調度與任務的執行完全分離,方便任務的管理以及任務執行的靈活性。在Kettle中集成TaskSever相關的組件,需要關注Kettle中的兩個接口:JobEntryInterface和JobEntryDialogInterface。JobEntryInterface是Job Entry插件的主要實現接口,主要的功能如下:
- 保存Job Entry設置
實現類使用私有變量保存設置的參數,通過get、set方法獲取和設置。Dialog實現類會通過這些方法設置界面上的參數。同時,需要提供一個深度拷貝的方法,在保存的參數被修改時進行調用。
- 序列化插件
- 輸出信息提供
一個Job Entry支持三種類型的輸出:true、false和無條件。這三種情況不是所有的Job Entry都會同時支持,例如dummy job entry僅支持true和false。通過JobEntryInterface接口的evaluates()方法可以設置一個Job Entry的輸出結果是否支持true和false,isUnconditional()方法則是設置是否支持無條件執行。
- 執行任務
JobEntryDialogInterface接口負責構建和打開參數設置對話框。
4.2 基于TaskServer的任務執行系統
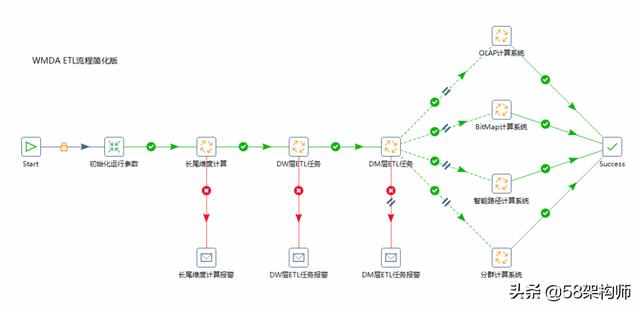
TaskServer是一個高可用的、可擴展性強的分布式任務執行系統。整體架構采用Master-Slave的設計模式,支持橫向擴展,兼備資源隔離、服務容災等功能,為線上任務的運行提供可靠的執行環境。WMDA各個子計算系統中的Hive sql和MapReduce都在TaskServer上執行,極大的確保WMDA離線任務的穩定性。
TaskServer主要包括三個部分:JobTracker集群、TaskTracker集群和Zookeeper集群。
- JobTracker:負責任務接受、資源計算和任務分配。
- TaskTracker:負責任務執行和保持心跳。
- TaskQueue:任務隊列。
- Zookeeper:協同調度。
在JobTracker中主要是資源的計算和任務分發,一個任務被提交之后會由JobTracker中的任務分發器(Dispatcher)發給對應的事件處理器(EventHadler),事件處理器完成之后會將任務相關的元數據信息寫入到Zookeeper中。TaskTracker監聽并拉取Zookeeper中新增的任務信息,抽象成TaskRunner放到線程池中運行,同時TaskTracker中任務調度器(TaskScheduler)跟JobTracker保持心跳用來更新機器信息。如果JobTracker監聽到某一個TaskTracker宕機會重新進行任務分配,由其他的TaskTracker來執行。資源的隔離方面,TaskTracker中采用硬性資源劃分機制和分時資源擴容機制。硬性資源是指資源被某種方式劃分之后,就只會接受這一類任務。在TaskServer中就為WMDA的任務劃分出來了WMDA Tier,只服務于WMDA提交的任務。分時資源擴容是指可以按照不同時間段來分擔其他Tier的任務。比如,在9點到10點是WMDA任務量的高峰,劃分的WMDA Tier不足以滿足當前任務所需要的計算資源,此時利用分時資源擴容機制從Share Tier中擴容一些Tier來滿足當前任務對計算資源的需求。
4.3 Druid在OLAP計算系統的實踐
WMDA中主要涉及OLAP場景模塊有概覽、單圖、即席圈選7日數據預覽、熱圖、維度閱覽以及用戶行為統計。OLAP引擎在選擇上嘗試過kylin和Druid。Kylin采用預計算,因為數據已經提前計算好,所以在前端查詢展示的時候相對較快。但是,因為WMDA支持多個維度任意組合,所以采用Kylin需要根據不同組合情況進行計算,這就使得隨著維度的增加,計算量增大。Druid則需要根據查詢條件即時計算,查詢相比Kylin慢,但是優化后基本在1秒以內。WMDA最終基于Druid實現OLAP模塊,其包括的角色有:
- Real-Time Nodes:負責實時數據處理;
- Historical Nodes:負責加載非實時窗口內滿足加載規則的所有歷史數據Segment;
- Coordinator Nodes:負責Druid集群中Segment的管理與發布,包括加載新Segment,丟棄不符合規則的Segment,管理Segment副本以及Segment負載均衡;
- Broker Nodes:整個集群的查詢入口,提供查詢路由和結果組裝;
- Indexing Service:負責“生產”Segment的高可用、分布式、Master/Slave架構服務。
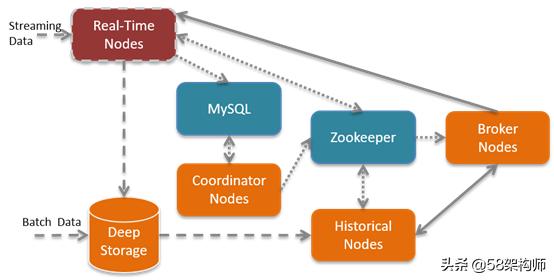
Druid將數據的索引節點劃分為HistoricalNodes和Real-Time Nodes,切割了歷史數據的加載與實時流數據處理,因為二者都需要占用大量內存與CPU;另一方面,劃分Coordinator Nodes和Broker Nodes,切割了查詢需求與數據如何在集群內分布的需求,確保用戶的查詢請求不會影響數據在集群內的分布情況。
在時間窗口內的數據會停留在Real-Time Nodes內存中,而時間窗口外的數據會組織成Segment存儲到Deep Storage中;批量數據經過Indexing Service也會被組織成Segment存儲到Deep Storage中,WMDA使用HDFS作為Druid的Deep Storage,同時Segment的元信息都會被注冊到元信息庫中,Coordinator Nodes會定期(默認為1分鐘)去同步元信息庫,感知新生成的Segment,并通知在線的Historical Node去加載Segment,Zookeeper也會更新整個集群內部數據分布拓撲圖。
當用戶需要查詢信息時,會將請求提交給Broker Nodes,BrokerNodes會請求Zookeeper獲取集群內數據分布拓撲圖,從而知曉請求應該發給哪些Historical Nodes以及Real-Time Nodes,匯總各節點的返回數據并將最終結果返回給用戶。
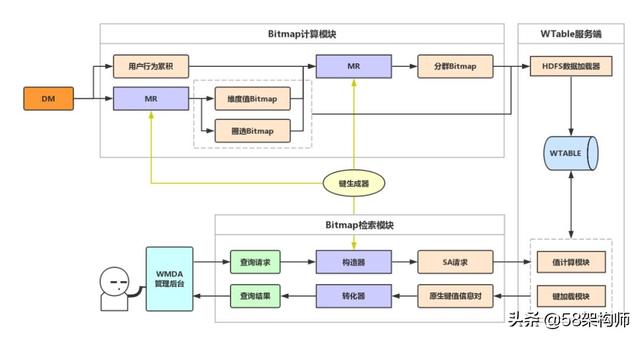
4.4 Bitmap計算系統在WMDA中的實踐
Bitmap是漏斗、留存和分群數據分析中,用來較快計算滿足某些條件下用戶數量的數據結構。Bitmap計算系統分為Bitmap計算模塊和Bitmap檢索模塊,Bitmap計算模塊通過MapReduce從基礎日志中計算出指標Bitmap、維度Bitmap和分群Bitmap,并提交至WTable中。Bitmap檢索模塊則是通過BitMapEngine查詢出符合查詢條件的用戶包。
五、總結
本文主要闡述了WMDA數據端的架構設計,主要從數據采集、數據計算、數據應用、調度系統等方面逐一進行了介紹。當然,大數據處理相關的架構以及技術選型并不是本文介紹的這一個方向,好的架構應該是根據具體的業務來設計的,而且是隨著業務的拓展不斷演變的。
歡迎大家關注“58架構師”微信公眾號,定期分享云計算、AI、區塊鏈、大數據、搜索、推薦、存儲、中間件、移動、前端、運維等方面的前沿技術和實踐經驗。
方法與示例)

方法和示例)

方法與示例)

方法與示例)




方法)

方法以及JavaScript中的示例)

方法與示例)


方法及示例)
