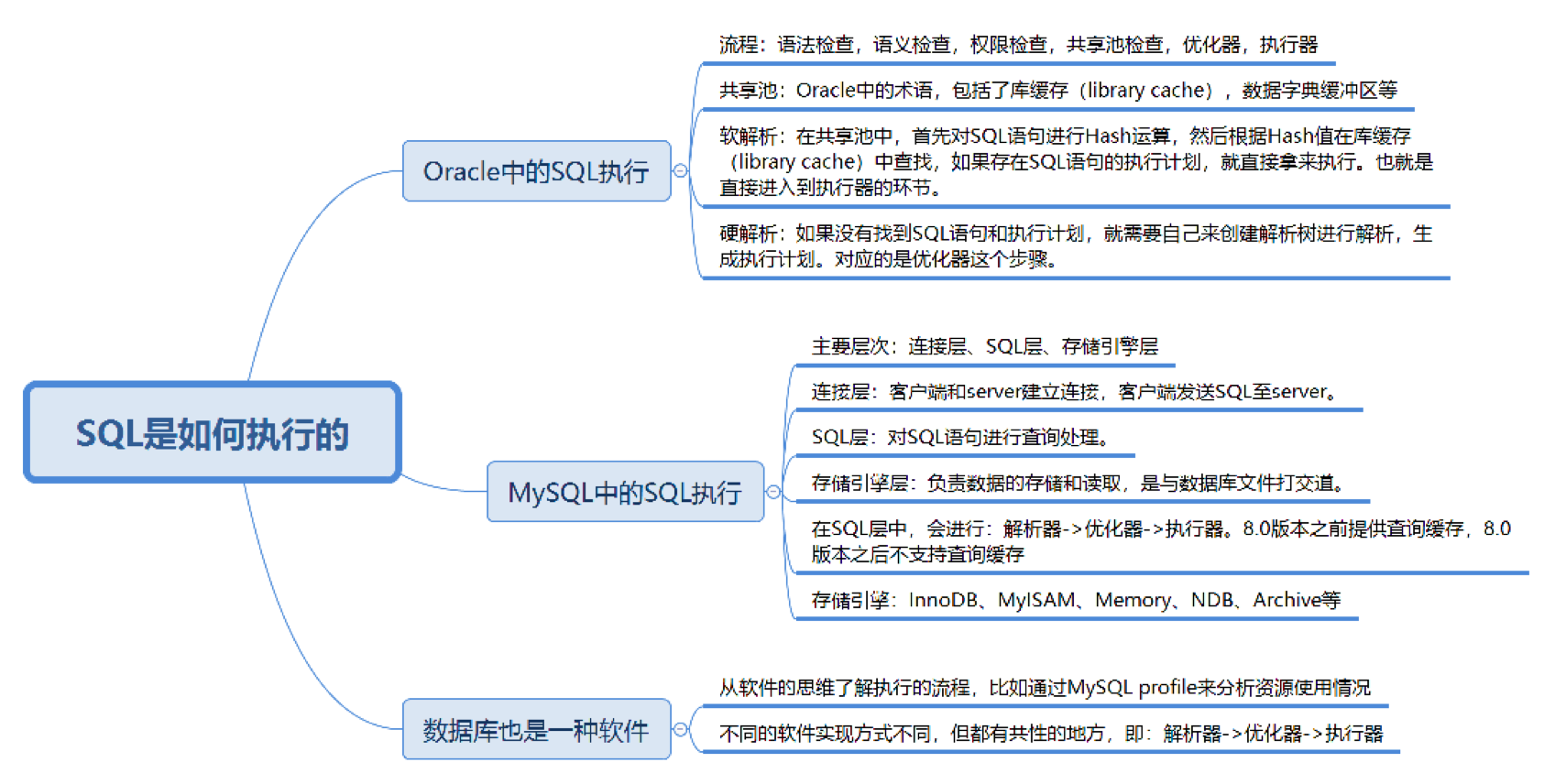
MySQL中的SQL是如何執行的
MySQL是典型的C/S架構,也就是Client/Server架構,服務器端程序使用的mysqld.整體的MySQL流程如下圖所示:
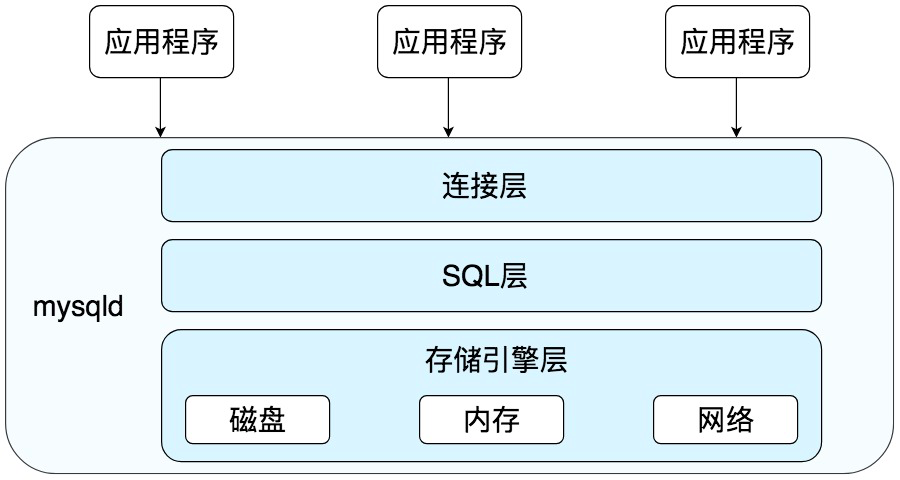
MySQL是有三層組成:
連接層: 負責客戶端與服務器端建立連接,客戶端發送SQL至服務端;
SQL層: 對SQL語句進行查詢處理;
存儲引擎層: 與數據庫文件打交道,負責數據的存儲和讀取.
其中,SQL層與數據庫文件的存儲方式無關,我們來看下SQL層的架構:
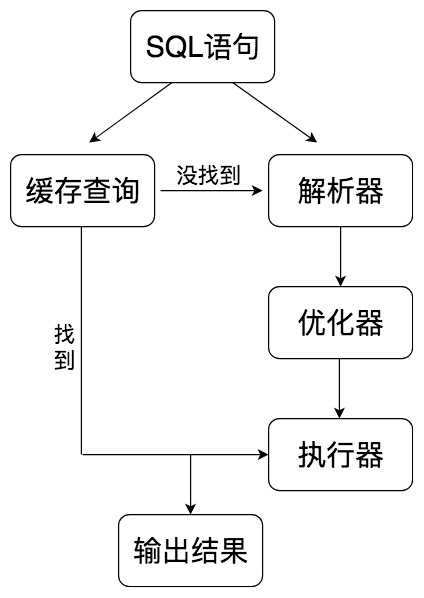
查詢緩存: Server如果在查詢緩存中發現了這條SQL語句,就會直接將結果返回給客戶端;如果沒有,就進入到解析器階段.格外注意的是,因為查詢緩存往往效率不高,所以在MySQL8.0之后就拋棄了緩存.
解析器: 在解析器中對SQL語句進行語法分析和語義分析.
優化器: 在優化器中會確定SQL語句的執行路徑,比如說是根據全表檢索,還是根據索引來檢索等.
執行器: 在執行前需要判斷用戶是否具備權限,如果具備權限就執行SQL查詢并返回結果.在MySQL8.0以下的版本,如果設置了查詢緩存,這時會將查詢結果進行緩存.
SQL語句在MySQL中的流程是: SQL語句 -> 緩存查詢 -> 解析器 -> 優化器 -> 執行器.
說說存儲引擎,MySQL的存儲引擎采用了插件的方式,每個存儲引擎都面向一種特定的數據庫應用環境.同事MySQL還允許開發人員設置自己的存儲引擎.下面列舉常見的存儲引擎:
InnoDB存儲引擎: 是MySQL5.5.8版本之后默認的存儲引擎,最大的特點是支持事務、行級鎖定、外鍵約束等.
MyISAM存儲引擎: 在MySQL5.5.8版本之前是默認的存儲引擎,不支持事務,也不支持外鍵,最大的特點是速度快,占用資源少.
Memory存儲引擎: 使用系統內存作為存儲介質,以便得到更快的響應速度.不過如果mysqld進程崩潰,則會導致所有的數據丟失,因此只有當數據是臨時數據的情況下才會使用Memory引擎.
NDB存儲引擎: 也叫做NDB Cluster存儲引擎,主要用于MySQL cluster分布式集群環境,類似于Oracle的RAC集群.
Archive存儲引擎: 有很好的壓縮機制,用于文件歸檔,在請求寫入時會進行壓縮,所以經常用來做倉庫.
注意,數據庫的設計在于表的設計,所以MySQL中每個表的設計都可以采用不同的存儲引擎,可以根據實際情況的數據處理需要來選擇存儲引擎,這個是MySQL強大的地方.
數據庫管理系統也是一種軟件
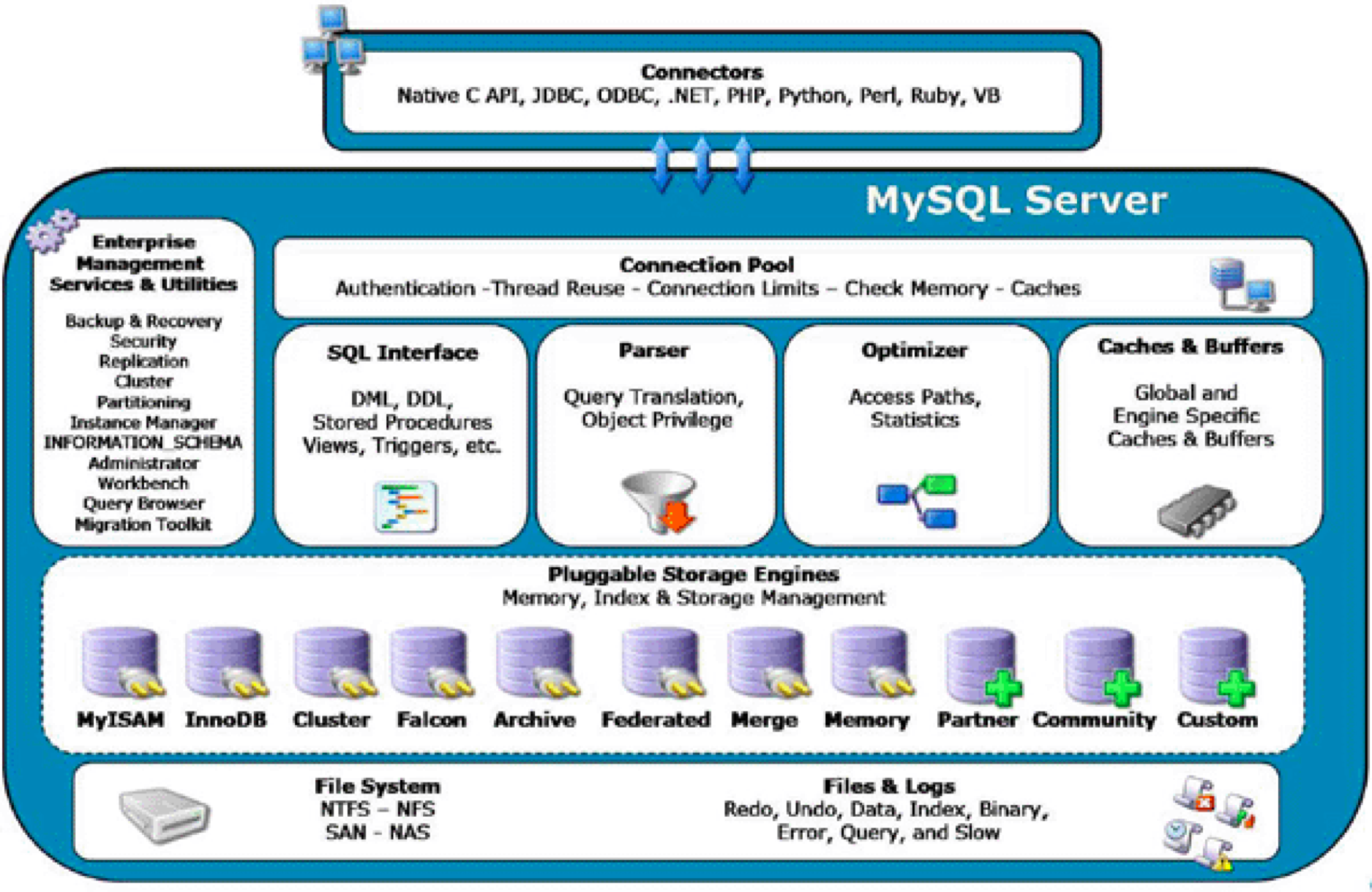
完成的MySQL結構圖如下:
profiling的使用,開啟profiling可以讓MySQL收集在SQL執行時所使用的資源情況,命令如下
select @@profiliong;
返回結果如果是0表示關閉,如果是1表示打開.可以使用 set profiling = 1;將profiling打開.
接下來可以執行sql語句,然后使用 show profiles來查詢當前會話產生的所有peofiles.

前面會有query_id,可以使用show profile;獲取上次查詢執行的時間,或者使用show profile for query id;查詢指定的query id執行的時間.
當然還有oracle的執行過程,這個暫時不研究.

函數與示例)







【轉】)




函數與C ++中的示例)
函數與C ++中的示例)


方法)
