
作者? 泊浮目 · 沃趣科技高級研發工程師
出品 ?沃趣科技

1. 前言
當我們向zk發出一個數據更新請求時,這個請求的處理流程是什么樣的?zk又是使用了什么共識算法來保證一致性呢?帶著這些問題,我們進入今天的正文。
2. 設計模式:責任鏈模式(Chain of Responsibility)
在分析源碼之前,必須先和大家簡單的科普一下責任鏈模式,因為這和本文的內容密切相關。簡單的說:責任鏈模式將多個對象組成一條指責鏈,然后按照它們在職責鏈的順序一個個地找出到底誰來負責處理。
那它的好處是什么呢?即松耦合發出請求者和處理者之間的關系:處理者們可以自由的推卸“請求”直到找到相應的處理者。如果處理者收到了不屬于自己所需處理的請求時,只需轉發下去即可,不需要編寫額外的邏輯處理。
3. 請求邏輯追蹤
我們先從ZooKeeperServer這個類入手,查看其實現類。我們需要關心的(常見的)zk服務器角色如下:
LeaderZooKeeperServer
FollowerZooKeeperServer
ObserverZooKeeperServer
3.1 實現鳥瞰
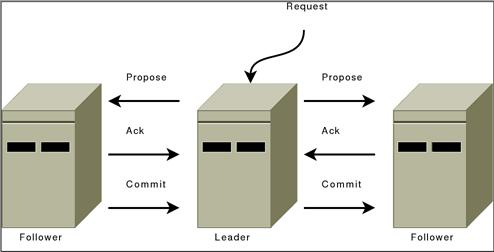
3.1.1 LeaderZooKeeperServer
代碼的入口在LeaderZooKeeperServer.setupRequestProcessors,為了閱讀體驗,筆者在這里會先以視圖的方式呈現邏輯組織。而喜歡閱讀源碼的同學可以閱讀3.2里的實現詳解。
|-- LeaderRequestProcessor
\-- processRequest //檢查會話是否失效
|-- PrepRequestProcessor
\-- processRequest //參數校驗和根據需求創建事務
|-- ProposalRequestProcessor
\-- processRequest // 發起proposal
\-- //事務型請求
\-- SyncRequestProcessor
\-- processRequest // 將請求記錄到事務日志中,如果有需要的話則觸發快照
\-- AckRequestProcessor
\-- processRequest // 確認事務日志收集完成,對于Proposal的投票器進行ack反饋
\-- CommitProcessor
\-- processRequest // 等待集群內Proposal投票直到可被提交
\-- ToBeAppliedRequestProcessor
\-- processRequest // 存儲已經被CommitProcessor處理過的可提交的Proposal——直到FinalRequestProcessor處理完后,才會將其移除
\-- FinalRequestProcessor
\-- processRequest // 回復請求,并改變內存數據庫的狀態
\-- //非事務型請求
\-- CommitProcessor
\-- processRequest // skip,只處理非事務型請求
\-- ToBeAppliedRequestProcessor
\-- processRequest // skip,配合CommitProcessor一起工作
\-- FinalRequestProcessor
\-- processRequest // 回復請求,并改變內存數據庫的狀態3.1.2 FollowerZooKeeperServer
//處理 client的請求
|-- FollowerRequestProcessor
\-- processRequest //事務的話調用CommitProcessor,并發送給leader;不然直接到FinalProcessor
|-- CommitProcessor
\-- processRequest // 等待集群內Proposal投票直到可被提交
|-- FinalProcessor
\-- processRequest // 回復請求,并改變內存數據庫的狀態
//專門用來處理 leader發起的proposal
|-- SyncRequestProcessor
| \-- processRequest // 將請求記錄到事務日志中,如果有需要的話則觸發快照
|-- SendAckRequestProcessor
\-- processRequest // ack給proposal發起者,表示自身完成了日志的記錄3.1.3 ObserverZooKeeperServer
//處理 client的請求
|-- ObserverRequestProcessor
\-- processRequest //和FollowerRequestProcessor代碼幾乎一模一樣:事務的話調用CommitProcessor,并發送給leader;不然直接到FinalProcessor
|-- CommitProcessor
\-- processRequest // 等待集群內Proposal投票直到可被提交
|-- FinalProcessor
\-- processRequest // 回復請求,并改變內存數據庫的狀態3.2 實現詳解
下面的源碼分析基于
3.5.7版本。
3.2.1 LeaderZooKeeperServer
@Override
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader());
commitProcessor = new CommitProcessor(toBeAppliedProcessor,
Long.toString(getServerId()), false,
getZooKeeperServerListener());
commitProcessor.start();
ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this,
commitProcessor);
proposalProcessor.initialize();
prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor);
prepRequestProcessor.start();
firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor);
setupContainerManager();
}
3.2.2 LeaderRequestProcessor
@Override
public void processRequest(Request request)throws RequestProcessorException {
// Check if this is a local session and we are trying to create
// an ephemeral node, in which case we upgrade the session
Request upgradeRequest = null;
try {
upgradeRequest = lzks.checkUpgradeSession(request);
} catch (KeeperException ke) {
if (request.getHdr() != null) {
LOG.debug("Updating header");
request.getHdr().setType(OpCode.error);
request.setTxn(new ErrorTxn(ke.code().intValue()));
}
request.setException(ke);
LOG.info("Error creating upgrade request " + ke.getMessage());
} catch (IOException ie) {
LOG.error("Unexpected error in upgrade", ie);
}
if (upgradeRequest != null) {
nextProcessor.processRequest(upgradeRequest);
}
nextProcessor.processRequest(request);
}
這段邏輯很清楚。因需要檢查會話是否過期,去創建一個臨時節點。如果失敗那么就拋出異常。
3.2.3 PrepRequestProcessor
該類有1000多行代碼,故此會挑出較為典型的代碼進行剖析。在此之前,我們先看注釋:
This request processor is generally at the start of a RequestProcessor change. It sets up any transactions associated with requests that change the state of the system. It counts on ZooKeeperServer to update outstandingRequests, so that it can take into account transactions that are in the queue to be applied when generating a transaction.
簡單來說,它一般位于請求處理鏈的頭部,它會設置事務型請求(改變系統狀態的請求)。
OpCode.create2
對于創建型請求邏輯大致為:
case OpCode.create2:
CreateRequest create2Request = new CreateRequest();
pRequest2Txn(request.type, zks.getNextZxid(), request, create2Request, true);
break;
跳往pRequest2Txn。
protected void pRequest2Txn(int type, long zxid, Request request,
Record record, boolean deserialize)throws KeeperException, IOException, RequestProcessorException{
request.setHdr(new TxnHeader(request.sessionId, request.cxid, zxid,
Time.currentWallTime(), type));
switch (type) {
case OpCode.create:
case OpCode.create2:
case OpCode.createTTL:
case OpCode.createContainer: {
pRequest2TxnCreate(type, request, record, deserialize);
break;
}
//....多余代碼不再展示
跳往pRequest2TxnCreate:
private void pRequest2TxnCreate(int type, Request request, Record record, boolean deserialize) throws IOException, KeeperException {
if (deserialize) {
ByteBufferInputStream.byteBuffer2Record(request.request, record);
}
int flags;
String path;
List acl;byte[] data;long ttl;if (type == OpCode.createTTL) {
CreateTTLRequest createTtlRequest = (CreateTTLRequest)record;
flags = createTtlRequest.getFlags();
path = createTtlRequest.getPath();
acl = createTtlRequest.getAcl();
data = createTtlRequest.getData();
ttl = createTtlRequest.getTtl();
} else {
CreateRequest createRequest = (CreateRequest)record;
flags = createRequest.getFlags();
path = createRequest.getPath();
acl = createRequest.getAcl();
data = createRequest.getData();
ttl = -1;
}
CreateMode createMode = CreateMode.fromFlag(flags);
validateCreateRequest(path, createMode, request, ttl);
String parentPath = validatePathForCreate(path, request.sessionId);
List listACL = fixupACL(path, request.authInfo, acl);
ChangeRecord parentRecord = getRecordForPath(parentPath);
checkACL(zks, parentRecord.acl, ZooDefs.Perms.CREATE, request.authInfo);int parentCVersion = parentRecord.stat.getCversion();if (createMode.isSequential()) {
path = path + String.format(Locale.ENGLISH, "%010d", parentCVersion);
}
validatePath(path, request.sessionId);try {if (getRecordForPath(path) != null) {throw new KeeperException.NodeExistsException(path);
}
} catch (KeeperException.NoNodeException e) {// ignore this one
}boolean ephemeralParent = EphemeralType.get(parentRecord.stat.getEphemeralOwner()) == EphemeralType.NORMAL;if (ephemeralParent) {throw new KeeperException.NoChildrenForEphemeralsException(path);
}int newCversion = parentRecord.stat.getCversion()+1;if (type == OpCode.createContainer) {
request.setTxn(new CreateContainerTxn(path, data, listACL, newCversion));
} else if (type == OpCode.createTTL) {
request.setTxn(new CreateTTLTxn(path, data, listACL, newCversion, ttl));
} else {
request.setTxn(new CreateTxn(path, data, listACL, createMode.isEphemeral(),
newCversion));
}
StatPersisted s = new StatPersisted();if (createMode.isEphemeral()) {
s.setEphemeralOwner(request.sessionId);
}
parentRecord = parentRecord.duplicate(request.getHdr().getZxid());
parentRecord.childCount++;
parentRecord.stat.setCversion(newCversion);
addChangeRecord(parentRecord);
addChangeRecord(new ChangeRecord(request.getHdr().getZxid(), path, s, 0, listACL));
}大致可以總結下邏輯:
組裝請求
校驗請求是否合理:未定義的請求、參數不合理
檢查上級路徑是否存在
檢查ACL
檢查路徑是否合法
將請求裝入
outstandingChanges隊列發送至下一個Processor
OpCode.multi
事務型請求:
case OpCode.multi:
MultiTransactionRecord multiRequest = new MultiTransactionRecord();
try {
ByteBufferInputStream.byteBuffer2Record(request.request, multiRequest);
} catch(IOException e) {
request.setHdr(new TxnHeader(request.sessionId, request.cxid, zks.getNextZxid(),
Time.currentWallTime(), OpCode.multi));
throw e;
}
List txns = new ArrayList();//Each op in a multi-op must have the same zxid!long zxid = zks.getNextZxid();
KeeperException ke = null;//Store off current pending change records in case we need to rollback
Map pendingChanges = getPendingChanges(multiRequest);for(Op op: multiRequest) {
Record subrequest = op.toRequestRecord();int type;
Record txn;/* If we've already failed one of the ops, don't bother
* trying the rest as we know it's going to fail and it
* would be confusing in the logfiles.
*/if (ke != null) {
type = OpCode.error;
txn = new ErrorTxn(Code.RUNTIMEINCONSISTENCY.intValue());
}/* Prep the request and convert to a Txn */else {try {
pRequest2Txn(op.getType(), zxid, request, subrequest, false);
type = request.getHdr().getType();
txn = request.getTxn();
} catch (KeeperException e) {
ke = e;
type = OpCode.error;
txn = new ErrorTxn(e.code().intValue());if (e.code().intValue() > Code.APIERROR.intValue()) {
LOG.info("Got user-level KeeperException when processing {} aborting" +" remaining multi ops. Error Path:{} Error:{}",
request.toString(), e.getPath(), e.getMessage());
}
request.setException(e);/* Rollback change records from failed multi-op */
rollbackPendingChanges(zxid, pendingChanges);
}
}//FIXME: I don't want to have to serialize it here and then// immediately deserialize in next processor. But I'm// not sure how else to get the txn stored into our list.
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(baos);
txn.serialize(boa, "request") ;
ByteBuffer bb = ByteBuffer.wrap(baos.toByteArray());
txns.add(new Txn(type, bb.array()));
}
request.setHdr(new TxnHeader(request.sessionId, request.cxid, zxid,
Time.currentWallTime(), request.type));
request.setTxn(new MultiTxn(txns));break;代碼雖然看起來很惡心,但是邏輯倒是挺簡單的:
遍歷所有請求,一個個組裝成起來(要通過一系列的校驗:請求合理、上級路徑存在、ACL、路徑合法),如果中間一直沒有異常,則組裝成一個請求,里面封裝了事務的記錄。不然則變成一個標記為錯誤的請求,并回滾掉當前作用域里的記錄(一個Map)。無論如何,請求都會被發送至下一個Processor。
OpCode.sync
//All the rest don't need to create a Txn - just verify session
case OpCode.sync:
zks.sessionTracker.checkSession(request.sessionId,
request.getOwner());
break;
非事務型請求,校驗一下session就可以發送至下一個Processor了。
3.2.4 ProposalRequestProcessor
對于事務請求會發起Proposal,并發送給CommitProcessor。而且ProposalRequestProcessor還會將事務請求交付給SyncRequestProcessor。
public void processRequest(Request request) throws RequestProcessorException {
// LOG.warn("Ack>>> cxid = " + request.cxid + " type = " +
// request.type + " id = " + request.sessionId);
// request.addRQRec(">prop");
/* In the following IF-THEN-ELSE block, we process syncs on the leader.
* If the sync is coming from a follower, then the follower
* handler adds it to syncHandler. Otherwise, if it is a client of
* the leader that issued the sync command, then syncHandler won't
* contain the handler. In this case, we add it to syncHandler, and
* call processRequest on the next processor.
*/
if (request instanceof LearnerSyncRequest){
zks.getLeader().processSync((LearnerSyncRequest)request);
} else {
nextProcessor.processRequest(request);
if (request.getHdr() != null) {
// We need to sync and get consensus on any transactions
try {
zks.getLeader().propose(request);
} catch (XidRolloverException e) {
throw new RequestProcessorException(e.getMessage(), e);
}
syncProcessor.processRequest(request);
}
}
}
接著看propose:
/**
* create a proposal and send it out to all the members
*
* @param request
* @return the proposal that is queued to send to all the members
*/
public Proposal propose(Request request) throws XidRolloverException {
/**
* Address the rollover issue. All lower 32bits set indicate a new leader
* election. Force a re-election instead. See ZOOKEEPER-1277
*/
if ((request.zxid & 0xffffffffL) == 0xffffffffL) {
String msg =
"zxid lower 32 bits have rolled over, forcing re-election, and therefore new epoch start";
shutdown(msg);
throw new XidRolloverException(msg);
}
byte[] data = SerializeUtils.serializeRequest(request);
proposalStats.setLastBufferSize(data.length);
QuorumPacket pp = new QuorumPacket(Leader.PROPOSAL, request.zxid, data, null);
Proposal p = new Proposal();
p.packet = pp;
p.request = request;
synchronized(this) {
p.addQuorumVerifier(self.getQuorumVerifier());
if (request.getHdr().getType() == OpCode.reconfig){
self.setLastSeenQuorumVerifier(request.qv, true);
}
if (self.getQuorumVerifier().getVersion() p.addQuorumVerifier(self.getLastSeenQuorumVerifier());
}
if (LOG.isDebugEnabled()) {
LOG.debug("Proposing:: " + request);
}
lastProposed = p.packet.getZxid();
outstandingProposals.put(lastProposed, p);
sendPacket(pp);
}
return p;
}
這次提交的記錄是一個QuorumPacket,其實現了Record接口。指定了type為PROPOSAL。我們看一下注釋:
/**
* This message type is sent by a leader to propose a mutation.
*/
public final static int PROPOSAL = 2;
很顯然,這個只有Leader才可以發起的一種變化型請求。再簡單描述下邏輯:
放到
outstandingProposals的Map里組裝成發送的Packet
將Proposal傳遞給下一個Processor
3.2.5 CommitProcessor
顧名思義,事務提交器。只關心事務請求——等待集群內Proposal投票直到可被提交。有了CommitProcessor,每個服務器都可以很好的對事務進行順序處理。
該部分的代碼實在簡陋,故不占篇幅來分析。讀者朋友知道上述信息后,也可以理解整個請求鏈是怎樣的。
3.2.6 SyncRequestProcessor
邏輯非常的簡單,將請求記錄到事務日志中,并嘗試觸發快照。
public void processRequest(Request request) {
// request.addRQRec(">sync");
queuedRequests.add(request);
}
//線程的核心方法,會對queuedRequests這個隊列進行操作
@Override
public void run() {
try {
int logCount = 0;
// we do this in an attempt to ensure that not all of the servers
// in the ensemble take a snapshot at the same time
int randRoll = r.nextInt(snapCount/2);
while (true) {
Request si = null;
if (toFlush.isEmpty()) {
si = queuedRequests.take();
} else {
si = queuedRequests.poll();
if (si == null) {
flush(toFlush);
continue;
}
}
if (si == requestOfDeath) {
break;
}
if (si != null) {
// track the number of records written to the log
if (zks.getZKDatabase().append(si)) {
logCount++;
if (logCount > (snapCount / 2 + randRoll)) {
randRoll = r.nextInt(snapCount/2);
// roll the log
zks.getZKDatabase().rollLog();
// take a snapshot
if (snapInProcess != null && snapInProcess.isAlive()) {
LOG.warn("Too busy to snap, skipping");
} else {
snapInProcess = new ZooKeeperThread("Snapshot Thread") {
public void run() {
try {
zks.takeSnapshot();
} catch(Exception e) {
LOG.warn("Unexpected exception", e);
}
}
};
snapInProcess.start();
}
logCount = 0;
}
} else if (toFlush.isEmpty()) {
// optimization for read heavy workloads
// iff this is a read, and there are no pending
// flushes (writes), then just pass this to the next
// processor
if (nextProcessor != null) {
nextProcessor.processRequest(si);
if (nextProcessor instanceof Flushable) {
((Flushable)nextProcessor).flush();
}
}
continue;
}
toFlush.add(si);
if (toFlush.size() > 1000) {
flush(toFlush);
}
}
}
} catch (Throwable t) {
handleException(this.getName(), t);
} finally{
running = false;
}
LOG.info("SyncRequestProcessor exited!");
}
3.2.7 ToBeAppliedRequestProcessor
該處理器的核心為一個toBeApplied隊列,專門用來存儲那些已經被CommitProcessor處理過的可提交的Proposal——直到FinalRequestProcessor處理完后,才會將其移除。
/*
* (non-Javadoc)
*
* @see org.apache.zookeeper.server.RequestProcessor#processRequest(org.apache.zookeeper.server.Request)
*/
public void processRequest(Request request) throws RequestProcessorException {
next.processRequest(request);
// The only requests that should be on toBeApplied are write
// requests, for which we will have a hdr. We can't simply use
// request.zxid here because that is set on read requests to equal
// the zxid of the last write op.
if (request.getHdr() != null) {
long zxid = request.getHdr().getZxid();
Iterator iter = leader.toBeApplied.iterator();if (iter.hasNext()) {
Proposal p = iter.next();if (p.request != null && p.request.zxid == zxid) {
iter.remove();return;
}
}
LOG.error("Committed request not found on toBeApplied: "
+ request);
}
}3.2.8 FinalRequestProcessor
篇幅原因,在這里簡單的描述下邏輯:既然是最后一個處理器,那么需要回復相應的請求,并負責事務請求的生效——改變內存數據庫的狀態。
3.2.9 FollowerZooKeeperServer
先看一下其組裝Processors的代碼:
@Override
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor,
Long.toString(getServerId()), true, getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new FollowerRequestProcessor(this, commitProcessor);
((FollowerRequestProcessor) firstProcessor).start();
syncProcessor = new SyncRequestProcessor(this,
new SendAckRequestProcessor((Learner)getFollower()));
syncProcessor.start();
}
可以看到,這里又兩對兒請求鏈:
FollowerRequestProcessor -> CommitProcessor -> FinalProcessor
SyncRequestProcessor -> SendAckRequestProcessor
那么請求來的時候,是哪個Processor來handle呢?這邊可以大致跟蹤一下:
firstProcessor(即FollowerRequestProcessor),是主要handle流程,由父類
ZooKeeperServer來調度,handle 請求syncProcessor(即SyncRequestProcessor)從
logRequest的入口進來。該類的由Learner調度進來,handle leader的請求。
看到這里有人就要問了,這明明是個Observer,怎么從Learner進來的呢?這就得看簽名了:
/**
* This class is the superclass of two of the three main actors in a ZK
* ensemble: Followers and Observers. Both Followers and Observers share
* a good deal of code which is moved into Peer to avoid duplication.
*/
public class Learner {
為了避免重復代碼,就把一些共同的代碼抽取上來了。
3.2.10 FollowerRequestProcessor
Follower的正常處理器,會判斷是不是事務,是事務就發送給Leader,不然自己處理。
FollowerRequestProcessor.run
@Override
public void run() {
try {
while (!finished) {
Request request = queuedRequests.take();
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, ZooTrace.CLIENT_REQUEST_TRACE_MASK,
'F', request, "");
}
if (request == Request.requestOfDeath) {
break;
}
// We want to queue the request to be processed before we submit
// the request to the leader so that we are ready to receive
// the response
nextProcessor.processRequest(request);
// We now ship the request to the leader. As with all
// other quorum operations, sync also follows this code
// path, but different from others, we need to keep track
// of the sync operations this follower has pending, so we
// add it to pendingSyncs.
switch (request.type) {
case OpCode.sync:
zks.pendingSyncs.add(request);
zks.getFollower().request(request);
break;
case OpCode.create:
case OpCode.create2:
case OpCode.createTTL:
case OpCode.createContainer:
case OpCode.delete:
case OpCode.deleteContainer:
case OpCode.setData:
case OpCode.reconfig:
case OpCode.setACL:
case OpCode.multi:
case OpCode.check:
zks.getFollower().request(request);
break;
case OpCode.createSession:
case OpCode.closeSession:
// Don't forward local sessions to the leader.
if (!request.isLocalSession()) {
zks.getFollower().request(request);
}
break;
}
}
} catch (Exception e) {
handleException(this.getName(), e);
}
LOG.info("FollowerRequestProcessor exited loop!");
}
而交付請求到CommitProcessor的邏輯很迷,事務型消息應該提交到leader,所以不需要這么一個processor——該Processor在前文也說過,用于等待集群內Proposal投票直到可被提交。
3.2.11 SendAckRequestProcessor
public void processRequest(Request si) {
if(si.type != OpCode.sync){
QuorumPacket qp = new QuorumPacket(Leader.ACK, si.getHdr().getZxid(), null,
null);
try {
learner.writePacket(qp, false);
} catch (IOException e) {
LOG.warn("Closing connection to leader, exception during packet send", e);
try {
if (!learner.sock.isClosed()) {
learner.sock.close();
}
} catch (IOException e1) {
// Nothing to do, we are shutting things down, so an exception here is irrelevant
LOG.debug("Ignoring error closing the connection", e1);
}
}
}
}
邏輯非常的簡單,用于反饋ACK成功,表示自身完成了事務日志的記錄。
3.2.12 ObserverZooKeeperServer
/**
* Set up the request processors for an Observer:
* firstProcesor->commitProcessor->finalProcessor
*/
@Override
protected void setupRequestProcessors() {
// We might consider changing the processor behaviour of
// Observers to, for example, remove the disk sync requirements.
// Currently, they behave almost exactly the same as followers.
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor,
Long.toString(getServerId()), true,
getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new ObserverRequestProcessor(this, commitProcessor);
((ObserverRequestProcessor) firstProcessor).start();
/*
* Observer should write to disk, so that the it won't request
* too old txn from the leader which may lead to getting an entire
* snapshot.
*
* However, this may degrade performance as it has to write to disk
* and do periodic snapshot which may double the memory requirements
*/
if (syncRequestProcessorEnabled) {
syncProcessor = new SyncRequestProcessor(this, null);
syncProcessor.start();
}
}
邏輯很清晰(大概是因為3.3.0后加入的代碼吧),正常的請求鏈為:
ObserverRequestProcessor
CommitProcessor
FinalProcessor
如果syncRequestProcessorEnabled開啟的情況下(缺省為開),這意味著Observer也會去記錄事務日志以及做快照,這會給下降一定的性能,以及更多的內存要求。
然后再看下ObserverRequestProcessor,簡直和FollowerRequestProcessor如出一轍,有追求的工程師都會想辦法復用代碼。
@Override
public void run() {
try {
while (!finished) {
Request request = queuedRequests.take();
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, ZooTrace.CLIENT_REQUEST_TRACE_MASK,
'F', request, "");
}
if (request == Request.requestOfDeath) {
break;
}
// We want to queue the request to be processed before we submit
// the request to the leader so that we are ready to receive
// the response
nextProcessor.processRequest(request);
// We now ship the request to the leader. As with all
// other quorum operations, sync also follows this code
// path, but different from others, we need to keep track
// of the sync operations this Observer has pending, so we
// add it to pendingSyncs.
switch (request.type) {
case OpCode.sync:
zks.pendingSyncs.add(request);
zks.getObserver().request(request);
break;
case OpCode.create:
case OpCode.create2:
case OpCode.createTTL:
case OpCode.createContainer:
case OpCode.delete:
case OpCode.deleteContainer:
case OpCode.setData:
case OpCode.reconfig:
case OpCode.setACL:
case OpCode.multi:
case OpCode.check:
zks.getObserver().request(request);
break;
case OpCode.createSession:
case OpCode.closeSession:
// Don't forward local sessions to the leader.
if (!request.isLocalSession()) {
zks.getObserver().request(request);
}
break;
}
}
} catch (Exception e) {
handleException(this.getName(), e);
}
LOG.info("ObserverRequestProcessor exited loop!");
}
以上,就是源碼分析部分,基于3.5.7版本。
4. 分布式事務:ZK如何進行事務處理
之前和大家過了一下源碼,相信各位對ZK請求處理流程有了一定的了解。接下來,讓我們理一理事務請求的過程。從Leader的ProposalRequestProcessor開始,大致會分為三個階段,即:
Sync
Proposal
Commit
4.1 Sync
主要由ProposalRequestProcessor來做,通知參與proposql的機器(Leader和Follower)都要記錄事務日志。
4.2 Proposal
每個事務請求都要超過半數的投票認可(Leader + Follower)。
Leader檢查服務端的ZXID可用,可用的話發起Proposal。不可用則拋出XidRolloverException。(見org.apache.zookeeper.server.quorum.Leader.propose)
根據請求頭、事務體以及ZXID生成Proposal(見org.apache.zookeeper.server.quorum.Leader.propose)
廣播給所有Follower服務器(見org.apache.zookeeper.server.quorum.Leader.sendPacket)
相關成員記錄日志,并ACK給Leader服務器——直到超過半數,或者超時(見org.apache.zookeeper.server.quorum.Leader.processAck)。
將請求丟入
toBeApplied隊列中。(見org.apache.zookeeper.server.quorum.Leader.tryToCommit)廣播Commit,發給Follower的為
COMMIT,而Observer的為Inform。這使它們提交該Proposal。(見org.apache.zookeeper.server.quorum.Leader.commit && inform)
直到這里,算是完成了SyncRequestProcessor -> AckRequestProcessor。
4.3 Commit
接下來講CommitProcessor -> ToBeAppliedRequestProcessor -> FinalRequestProcessor的過程。
請求到CommitPrcocessor后是放入一個隊列里,由線程一個個取出來。當取出來是事務請求時,那么就會設置一個pending對象到投票結束。這樣保證了事務的順序性,也可以讓CommitPrcocessor方便的直到集群中是否有進行中的事務。
投票通過,喚醒commit流程。提交請求至
committedRequests這個隊列中,然后一個個發送至ToBeAppliedRequestProcessor里去。ToBeAppliedRequestProcessor會等待FinalRequestProcessor處理完成后,從
toBeApplied隊列中移除這個Proposal。FinalRequestProcessor會先去校驗隊列中最新的一個請求是否zxid小于等于當前的請求:
是的話則移除該請求。這種情況說明最新應用的事務比當前事務更早完成共識,當前事務請求無效,但是會被記錄到commitedLog中。
等于是正常現象,因為這個對列是在
PrepRequestProcessor時添加的。接著就是應用到內存數據庫了,該內存數據庫實例會維護一個默認上限為500的committedLog——存放最近成功的Proposal,便于快速同步。
如果在該步驟服務器宕機,則會在機器拉起時通過proposal階段的預寫日志進行數據訂正,并通過PlayBackListener同時將其轉換成proposal,并保存到committedLog中,便于同步。
5. 小結
綜合全文,我們可以發現ZK對于事務的處理方式有點像是二階段提交(two-phase commit)。其實這就是ZAB算法,在下一篇文章里,我們會詳細介紹其實現,并介紹它的另一個用途——分布式選舉。
相關鏈接
MySQL 一個讓你懷疑人生的hang死現象
MySQL權限表損壞導致無法啟動
K8S服務暴露: HAProxy在RDS場景下的妙用
深入淺出Zookeeper(三):Watch實現剖析
深入淺出Zookeeper(二):會話管理
深入淺出Zookeeper(一):存儲技術
組復制系統變量 | 全方位認識 MySQL 8.0 Group Replication
組復制升級 | 全方位認識 MySQL 8.0 Group Replication
組復制性能 | 全方位認識 MySQL 8.0 Group Replication
組復制安全 | 全方位認識 MySQL 8.0 Group Replication
組復制常規操作-使用xtrabackup備份恢復或添加組成員 | 全方位認識MySQL8.0 Group Replication
組復制常規操作-網絡分區&混合使用IPV6與IPV4 | 全方位認識 MySQL 8.0 Group Replication
組復制常規操作-分布式恢復 | 全方位認識 MySQL 8.0 Group Replication
組復制常規操作-事務一致性保證 | 全方位認識 MySQL 8.0 Group Replication
組復制常規操作-在線配置組 | 全方位認識 MySQL 8.0 Group Replication
再述mysqldump時域問題
揭秘 MySQL 主從環境中大事務的傳奇事跡
MySQL 執行DDL語句 hang住了怎么辦?
手把手教你認識OPTIMIZER_TRACE
MySQL行級別并行復制能并行應用多少個binlog group?
binlog server還是不可靠嗎?
MySQL binlog基于時間點恢復數據失敗是什么鬼?
MySQL高可用工具Orchestrator系列六:Orchestrator/raft一致性集群
MySQL高可用工具Orchestrator系列五:raft多節點模式安裝
MySQL高可用工具Orchestrator系列四:拓撲恢復
MySQL高可用工具Orchestrator系列三:探測機制
select into outfile問題一則
開源監控系統Prometheus的前世今生
prometheus監控多個MySQL實例
prometheus配置MySQL郵件報警
MySQL問題兩則
Kubernetes?scheduler學習筆記
直方圖系列1
執行計劃-12:基數反饋
執行計劃-11:真實數據
執行計劃-10:猜想
執行計劃-9:多倍操作
執行計劃-8:成本、時間等
大數據量刪除的思考(四)
大數據量刪除的思考(三)
日志信息記錄表|全方位認識 mysql 系統庫
復制信息記錄表|全方位認識 mysql 系統庫
時區信息記錄表|全方位認識 mysql 系統庫
Oracle RAC Cache Fusion系列十八:Oracle RAC Statisticsand Wait Events
Oracle RAC Cache Fusion 系列十七:Oracle RAC DRM
Oracle RAC CacheFusion 系列十六:Oracle RAC CurrentBlock Server

更多干貨,歡迎來撩~




)









下MySQL源碼安裝)




