來自公眾號:優達學城Udacity
作者:Kerry Parker
編譯:歐剃
作為數據科學家的第一個任務,就是做網頁爬取。那時候,我對使用代碼從網站上獲取數據這項技術完全一無所知,它偏偏又是最有邏輯性并且最容易獲得的數據來源。在幾次嘗試之后,網頁爬取對我來說就幾乎是種本能行為了。如今,它更成為了我幾乎每天都要用到的少數幾個技術之一。
在今天的文章中,我將會用幾個簡單的例子,向大家展示如何爬取一個網站——比如從?Fast Track?上獲取 2018 年 100 強企業的信息。用腳本將獲取信息的過程自動化,不但能節省手動整理的時間,還能將所有企業數據整理在一個結構化的文件里,方便進一步分析查詢。
太長不看版:如果你只是想要一個最基本的 Python 爬蟲程序的示例代碼,本文中所用到的全部代碼都放在?GitHub?(https://github.com/kaparker/tutorials/blob/master/pythonscraper/websitescrapefasttrack.py),歡迎自取。
準備工作
每一次打算用 Python 搞點什么的時候,你問的第一個問題應該是:“我需要用到什么庫”。
網頁爬取方面,有好幾個不同的庫可以用,包括:
Beautiful Soup
Requests
Scrapy
Selenium
今天我們打算用 Beautiful Soup 庫。你只需要用?pip(Python包管理工具)就能很方便地將它裝到電腦上:

安裝完畢之后,我們就可以開始啦!
檢查網頁
為了明確要抓取網頁中的什么元素,你需要先檢查一下網頁的結構。
以?Tech Track 100強企業(https://link.zhihu.com/?target=http%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)?這個頁面為例,你在表格上點右鍵,選擇“檢查”。在彈出的“開發者工具”中,我們就能看到頁面中的每個元素,以及其中包含的內容。
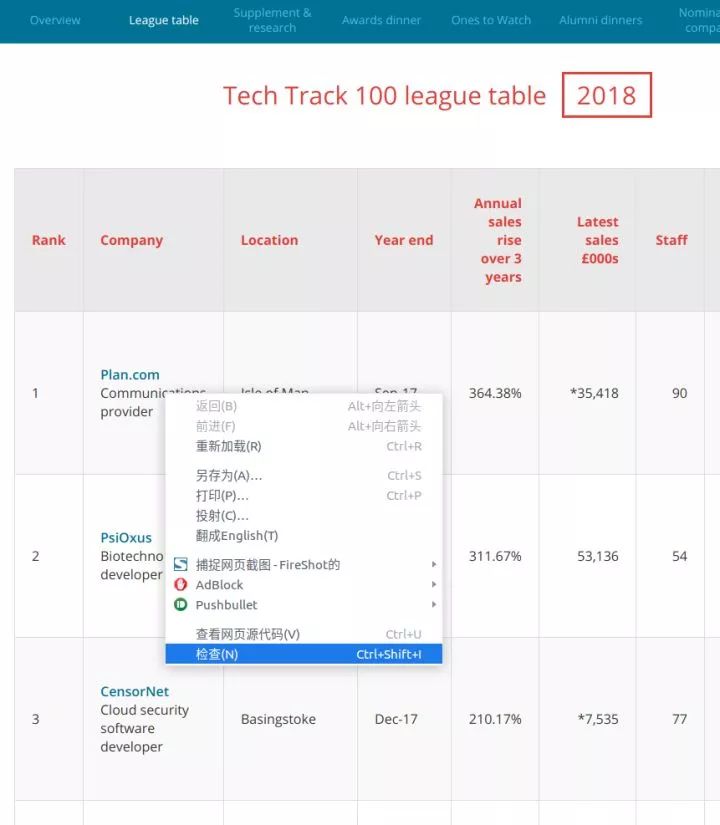
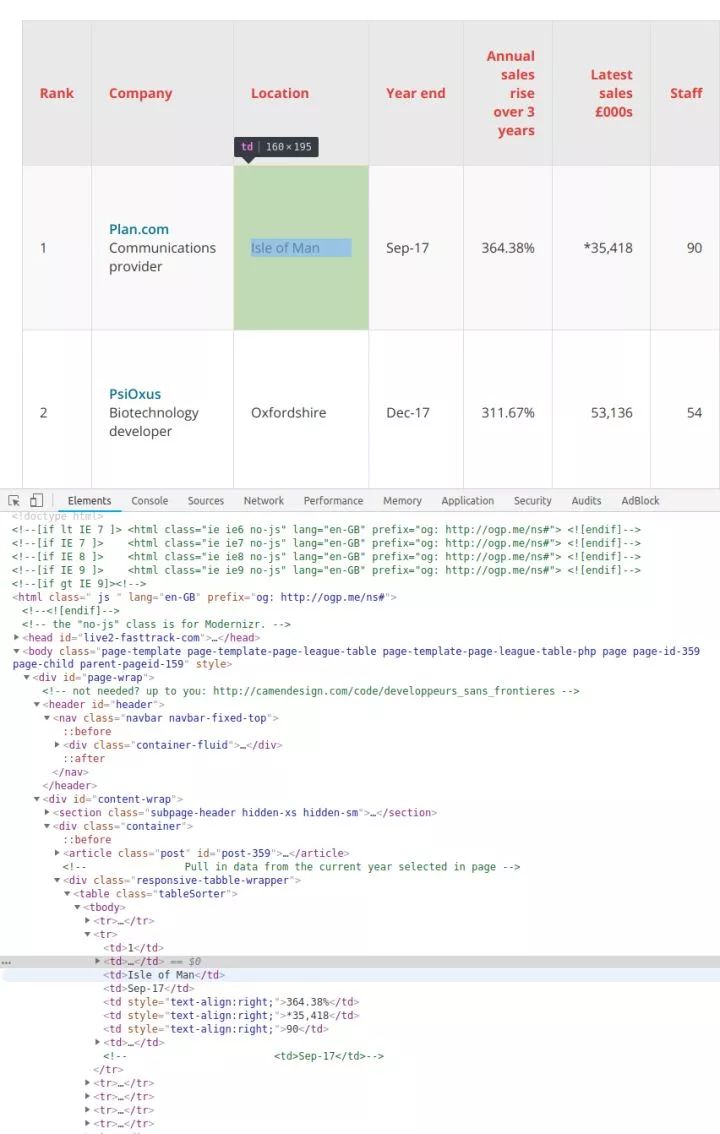
右鍵點擊你想要查看的網頁元素,選擇“檢查”,就能看到具體的 HTML 元素內容
既然數據都保存在表格里,那么只需要簡單的幾行代碼就能直接獲取到完整信息。如果你希望自己練習爬網頁內容,這就是一個挺不錯的范例。但請記住,實際情況往往不會這么簡單。
這個例子里,所有的100個結果都包含在同一個頁面中,還被??標簽分隔成行。但實際抓取過程中,許多數據往往分布在多個不同的頁面上,你需要調整每頁顯示的結果總數,或者遍歷所有的頁面,才能抓取到完整的數據。
在表格頁面上,你可以看到一個包含了所有100條數據的表格,右鍵點擊它,選擇“檢查”,你就能很容易地看到這個 HTML 表格的結構。包含內容的表格本體是在這樣的標簽里:

每一行都是在一個??標簽里,也就是我們不需要太復雜的代碼,只需要一個循環,就能讀取到所有的表格數據,并保存到文件里。
附注:你還可以通過檢查當前頁面是否發送了 HTTP GET 請求,并獲取這個請求的返回值,來獲取顯示在頁面上的信息。因為 HTTP GET 請求經常能返回已經結構化的數據,比如 JSON 或者 XML 格式的數據,方便后續處理。你可以在開發者工具里點擊 Network 分類(有必要的話可以僅查看其中的 XHR 標簽的內容)。這時你可以刷新一下頁面,于是所有在頁面上載入的請求和返回的內容都會在 Network 中列出。此外,你還可以用某種 REST 客戶端(比如?Insomnia)來發起請求,并輸出返回值。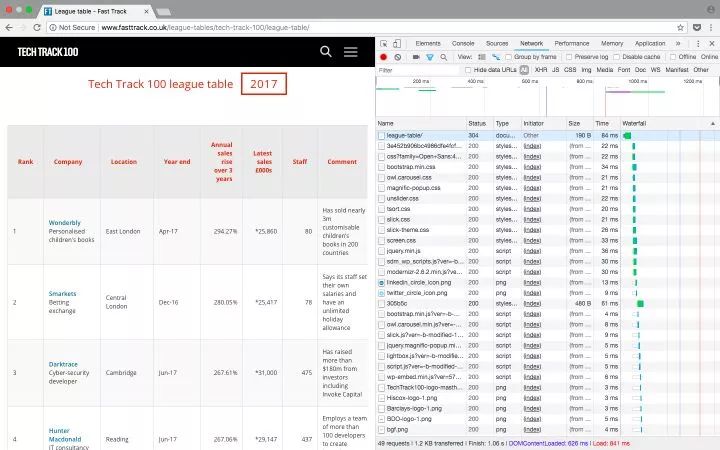
刷新頁面后,Network 標簽頁的內容更新了用 Beautiful Soup 庫處理網頁的 HTML 內容
在熟悉了網頁的結構,了解了需要抓取的內容之后,我們終于要拿起代碼開工啦~
首先要做的是導入代碼中需要用到的各種模塊。上面我們已經提到過?BeautifulSoup,這個模塊可以幫我們處理 HTML 結構。接下來要導入的模塊還有?urllib,它負責連接到目標地址,并獲取網頁內容。最后,我們需要能把數據寫入 CSV 文件,保存在本地硬盤上的功能,所以我們要導入?csv庫。當然這不是唯一的選擇,如果你想要把數據保存成 json 文件,那相應的就需要導入?json?庫。

下一步我們需要準備好需要爬取的目標網址。正如上面討論過的,這個網頁上已經包含了所有我們需要的內容,所以我們只需要把完整的網址復制下來,賦值給變量就行了:

接下來,我們就可以用?urllib?連上這個URL,把內容保存在?page?變量里,然后用 BeautifulSoup 來處理頁面,把處理結果存在?soup?變量里:
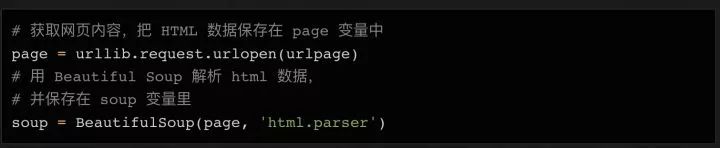
這時候,你可以試著把?soup?變量打印出來,看看里面已經處理過的 html 數據長什么樣:

如果變量內容是空的,或者返回了什么錯誤信息,則說明可能沒有正確獲取到網頁數據。你也許需要用一些錯誤捕獲代碼,配合?urllib.error?(https://docs.python.org/3/library/urllib.error.html)模塊,來發現可能存在的問題。
查找 HTML 元素
查找 HTML 元素既然所有的內容都在表格里(
?標簽),我們可以在?soup?對象里搜索需要的表格,然后再用?find_all?方法,遍歷表格中的每一行數據。如果你試著打印出所有的行,那應該會有 101 行 —— 100 行內容,加上一行表頭。

看看打印出來的內容,如果沒問題的話,我們就可以用一個循環來獲取所有數據啦。
如果你打印出 soup 對象的前 2 行,你可以看到,每一行的結構是這樣的:
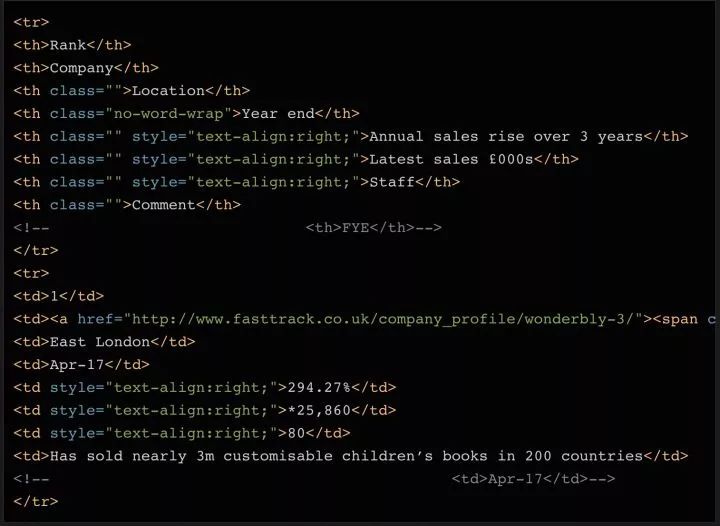
可以看到,表格中總共有 8 列,分別是 Rank(排名)、Company(公司)、Location(地址)、Year End(財年結束)、Annual Sales Rise(年度銷售增長)、Latest Sales(本年度銷售額)、Staff(員工數)和 Comments(備注)。
這些都是我們所需要的數據。
這樣的結構在整個網頁中都保持一致(不過在其他網站上可能就沒這么簡單了!),所以我們可以再次使用?find_all?方法,通過搜索??元素,逐行提取出數據,存儲在變量中,方便之后寫入 csv 或 json 文件。
循環遍歷所有的元素并存儲在變量中
在 Python 里,如果要處理大量數據,還需要寫入文件,那列表對象是很有用的。我們可以先聲明一個空列表,填入最初的表頭(方便以后CSV文件使用),而之后的數據只需要調用列表對象的?append?方法即可。
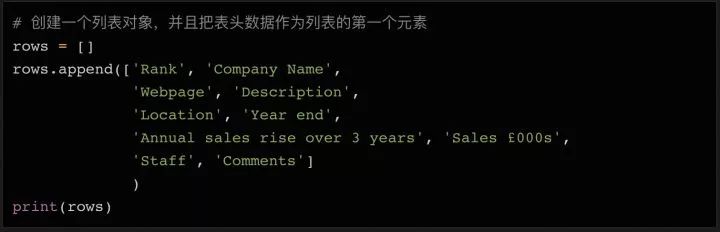
這樣就將打印出我們剛剛加到列表對象?rows?中的第一行表頭。
你可能會注意到,我輸入的表頭中比網頁上的表格多寫了幾個列名,比如?Webpage(網頁)和?Description(描述),請仔細看看上面打印出的 soup 變量數據——第二行第二列的數據里,可不只有公司名字,還有公司的網址和簡單描述。所以我們需要這些額外的列來存儲這些數據。
下一步,我們遍歷所有100行數據,提取內容,并保存到列表中。
循環讀取數據的方法:
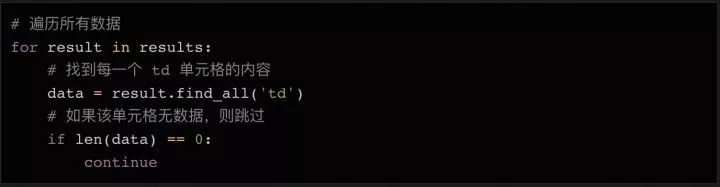
因為數據的第一行是 html 表格的表頭,所以我們可以跳過不用讀取它。因為表頭用的是??標簽,沒有用??標簽,所以我們只要簡單地查詢?標簽內的數據,并且拋棄空值即可。
接著,我們將 data 的內容讀取出來,賦值到變量中:
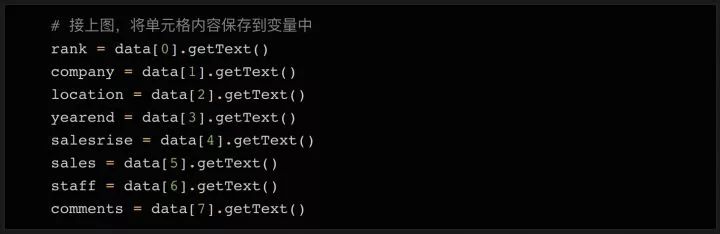
如上面的代碼所示,我們按順序將 8 個列里的內容,存儲到 8 個變量中。當然,有些數據的內容還需有額外的清理,去除多余的字符,導出所需的數據。
數據清理
如果我們打印出?company?變量的內容,就能發現,它不但包含了公司名稱,還包括和描述。如果我們打印出?sales?變量的內容,就能發現它還包括一些備注符號等需要清除的字符。

我們希望把?company?變量的內容分割成公司名稱和描述兩部分。這用幾行代碼就能搞定。再看看對應的 html 代碼,你會發現這個單元格里還有一個??元素,這個元素里只有公司名稱。另外,還有一個??鏈接元素,包含一個指向該公司詳情頁面的鏈接。我們一會也會用到它!
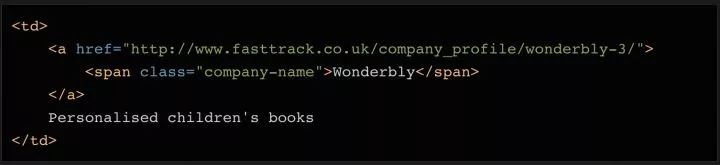
為了區分公司名稱和描述兩個字段,我們再用?find?方法把??元素里的內容讀取出來,然后刪掉或替換?company?變量中的對應內容,這樣變量里就只會留下描述了。
要刪除?sales?變量中的多余字符,我們用一次?strip?方法即可。
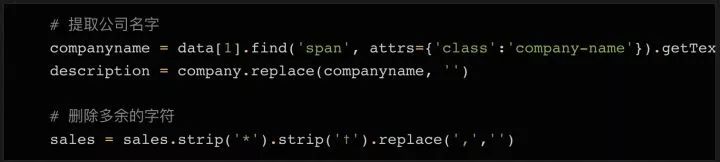
最后我們要保存的是公司網站的鏈接。就像上面說的,第二列中有一個指向該公司詳情頁面的鏈接。每一個公司的詳情頁都有一個表格,大部分情況下,表格里都有一個公司網站的鏈接。
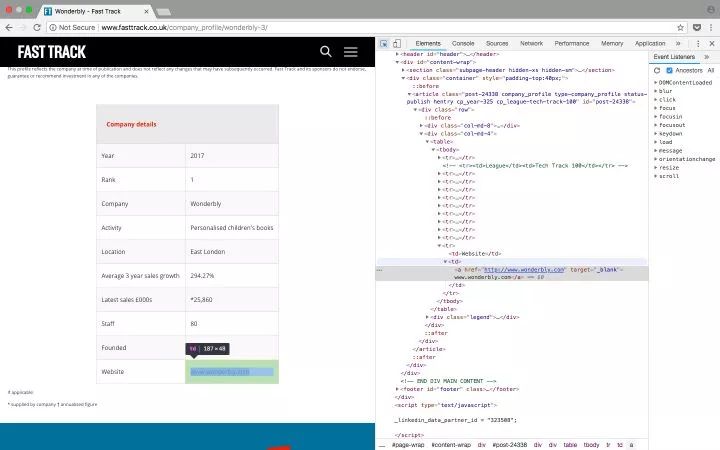
檢查公司詳情頁里,表格中的鏈接
為了抓取每個表格中的網址,并保存到變量里,我們需要執行以下幾個步驟:
在最初的 fast track 網頁上,找到需要訪問的公司詳情頁的鏈接。
發起一個對公司詳情頁鏈接的請求
用 Beautifulsoup 處理一下獲得的 html 數據
找到需要的鏈接元素
正如上面的截圖那樣,看過幾個公司詳情頁之后,你就會發現,公司的網址基本上就在表格的最后一行。所以我們可以在表格的最后一行里找??元素。
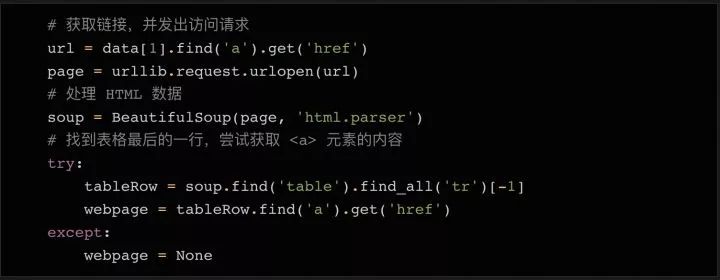
同樣,有可能出現最后一行沒有鏈接的情況。所以我們增加了?try... except?語句,如果沒有發現網址,則將變量設置成?None。當我們把所有需要的數據都存在變量中的以后(還在循環體內部),我們可以把所有變量整合成一個列表,再把這個列表?append?到上面我們初始化的 rows 對象的末尾。
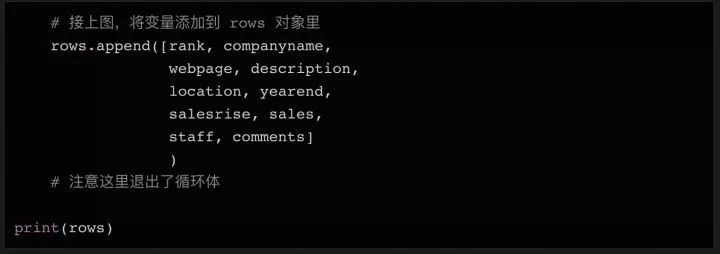
上面代碼的最后,我們在結束循環體之后打印了一下 rows 的內容,這樣你可以在把數據寫入文件前,再檢查一下。
寫入外部文件
最后,我們把上面獲取的數據寫入外部文件,方便之后的分析處理。在 Python 里,我們只需要簡單的幾行代碼,就可以把列表對象保存成文件。
最后,我們把上面獲取的數據寫入外部文件,方便之后的分析處理。在 Python 里,我們只需要簡單的幾行代碼,就可以把列表對象保存成文件。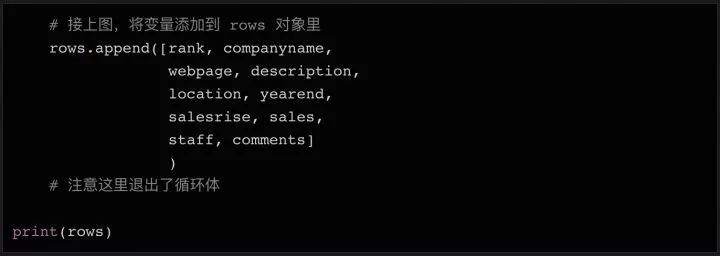
最后我們來運行一下這個 python 代碼,如果一切順利,你就會發現一個包含了 100 行數據的 csv 文件出現在了目錄中,你可以很容易地用 python 讀取和處理它。
總結
這篇簡單的 Python 教程中,我們一共采取了下面幾個步驟,來爬取網頁內容:
連接并獲取一個網頁的內容
用 BeautifulSoup 處理獲得的 html 數據
在 soup 對象里循環搜索需要的 html 元素
進行簡單的數據清理
把數據寫入 csv 文件中
如果有什么沒說清楚的,歡迎大家在下面留言,我會盡可能給大家解答的!
附:?本文全部代碼(https://github.com/kaparker/tutorials/blob/master/pythonscraper/websitescrapefasttrack.py)
祝你的爬蟲之旅有一個美好的開始!
編譯來源:?towardsdatascience.com
●輸入m獲取文章目錄
推薦↓↓↓
人工智能與大數據技術








:drbd的狀態說明)
方法)
方法)



方法)




方法)