相似文章推薦:在用戶閱讀某篇文章時,為用戶推薦更多的與在讀文章內容相類似的文章
相關概念:
推薦(Recommended):指介紹好的人或事物,希望被任用或接受。數據挖掘領域,推薦包括相似推薦和協同過濾推薦。
相似推薦(Similar Recommended): 指當用戶表現出對某人或者某物的興趣時,為他推薦與之相類似的人或者物,核心定理:人以群分,物以類聚。
協同過濾推薦(Collaborative Filtering Recommendation):指利用已有用戶群過去的行為或意見,預測當前用戶最可能喜歡哪些東西或對哪些東西感興趣
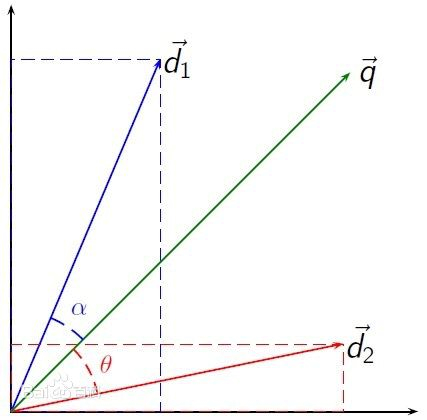
相關文章推薦主要基于余弦相似度的計算原理。
余弦相似度(Cosine Similarity):用向量空間中兩個向量夾角的余弦值作為衡量兩個個體見差異的大小。余弦值越接近1,就表明夾角越接近0度,也就是兩個向量越相似,這個特征叫做余弦相似性。
 ? ? ? ? ??
? ? ? ? ?? 
?
文章的余弦相似度:
素材:文章A、文章B
#對兩篇文章進行分詞,? 得到? [A] 、 [B]? 兩個分詞列表
#根據分詞結果構建分詞語料庫,得到 [C] = [A] | [B]?
#根據語料庫分別統計A、B的詞頻(向量化,需要嚴格按照分詞語料庫單詞的順序)
#計算余弦值
?
具體實現:在構建語料庫/中文分詞/文檔向量化之后
#計算余弦相似度 from sklearn.metrics import pairwise_distances #計算每行之間的距離,得到距離矩陣 distance_matrix = pairwise_distances(textVector,metric='cosine')#排序得到距離第2-6名的矩陣元素 sort = np.argsort(distance_matrix,axis=1)[:,1:6] similar5 = pd.Index(filepath)[sort].values#得到相似度前5的文章路徑數據框 similarDF = pd.DataFrame({'filepath':corpos.filePath,'s1':similar5[:,0],'s2':similar5[:,1],'s3':similar5[:,2],'s4':similar5[:,3],'s5':similar5[:,4],})
?





-總結篇)




)








