深入理解equals和hashCode關系和區別
- 直入主題:
- 區別:
- 1.他們判斷對象相同的方式不一樣:
- 2.他們判斷對象是否相等的準確率不一樣:
- 改寫equals時總是要改寫hashcode
- 分享一波:程序員賺外快-必看的巔峰干貨
為什么要說equals和hashCode這兩個東西,一來是因為有不少小伙伴面試時被問過這個東西,二來則是因為如果了解了這兩個東西的原理,那么實際的開發過程中,對效率和容錯率上還是能幫上很大的忙!
直入主題:
很多人把他們放在一起比較,那我們首先要想到的是,他們肯定有大致相同的作用,和一些細小的區別。
先說說他們相同的作用:equals和hashCode方法都是用來判斷兩個對象的值是否相等,請記住這里說的相等僅僅說的是兩個對象的值,和他們的引用無關
區別:
1.他們判斷對象相同的方式不一樣:
2.他們判斷對象是否相等的準確率不一樣:
為啥這樣說,因為hashCode有極小概率會判斷錯,而equals的判斷結果是百分百正確的
相信看到這里已經有朋友有疑問了,既然hashCode方法不能準確判斷,那我們為什么還要用它?哈哈哈,因為我們無法忍受丟棄他的另一個優點,就是效率高,接著往下看,我們慢慢捋一捋。
先說上面的第一點:判斷對象的相等的方式不一樣
1.equals:重寫的equals方法,比如String 的equals方法,如圖:

他最終的目的循環判斷兩個對象的每一個字符是否相等,所有字符全部對應相等,那他們的值肯定也就相等了,這是equals的判斷方法
hashCode的判斷方法:hashCode是通過用hash算法來計算具體對象實例,得到斌返回一個hashcode值。通過比較hashcode值是否相等來判斷兩個對象是否相等,
相信大家看到這里是已經有點懵逼了,別急,接下來具體講講他的原理:
以java.lang.Object來理解,JVM每new一個Object,它都會將這個Object丟到一個Hash哈希表中去,這樣的話,下次做Object的比較或者取這個對象的時候,它會根據對象的hashcode再從Hash表中取這個對象。這樣做的目的是提高取對象的效率。具體過程是這樣:
- new Object(),JVM根據這個對象的Hashcode值,放入到對應的Hash表對應的Key上,如果不同的對象確產生了相同的hash值,也就是發生了Hash key相同導致沖突的情況,那么就在這個Hash key的地方產生一個鏈表,將所有產生相同hashcode的對象放到這個單鏈表上去,串在一起。
- 比較兩個對象的時候,首先根據他們的hashcode去hash表中找他的對象,當兩個對象的hashcode相同,那么就是說他們這兩個對象放在Hash表中的同一個key上,那么他們一定在這個key上的鏈表上。那么此時就只能根據Object的equal方法來比較這個對象是否equal。當兩個對象的hashcode不同的話,肯定他們不能equal.
可能經過上面理論的講一下大家都迷糊了,我也看了之后也是似懂非懂的。下面我舉個例子詳細說明下。
list是可以重復的,set是不可以重復的。那么set存儲數據的時候是怎樣判斷存進的數據是否已經存在。使用equals()方法呢,還是hashcode()方法。
假如用equals(),那么存儲一個元素就要跟已存在的所有元素比較一遍,比如已存入100個元素,那么存101個元素的時候,就要調用equals方法100次。
但如果用hashcode()方法的話,他就利用了hash算法來存儲數據的。
這樣的話每存一個數據就調用一次hashcode()方法,得到一個hashcode值及存入的位置。如果該位置不存在數據那么就直接存入,否則調用一次equals()方法,不相同則存,相同不存。這樣下來整個存儲下來不需要調用幾次equals方法,雖然多了幾次hashcode方法,但相對于前面來講效率高了不少。
上面開始的時候我著重說了重寫的equals方法,為什么要重寫呢?
因為Object的equal方法默認是兩個對象的引用的比較,意思就是指向同一內存,地址則相等,否則不相等;如果你現在需要利用對象里面的值來判斷是否相等,則重載equal方法。
說道這個地方我相信很多人會有疑問,相信大家都被String對象的equals()方法和"= ="糾結過一段時間,當時我們知道String對象中equals方法是判斷值的,而= =是地址判斷。
那照這么說equals怎么會是地址的比較呢?
那是因為實際上JDK中,String、Math等封裝類都對Object中的equals()方法進行了重寫。
我們先看看Object中equals方法的源碼:
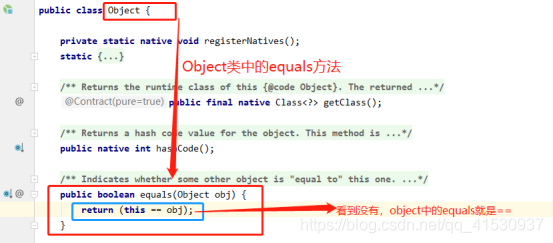
我們都知道所有的對象都擁有標識(內存地址)和狀態(數據),同時“==”比較兩個對象的的內存地址,所以說使用Object的equals()方法是比較兩個對象的內存地址是否相等,即若object1.equals(object2)為true,則表示equals1和equals2實際上是引用同一個對象。雖然有時候Object的equals()方法可以滿足我們一些基本的要求,但是我們必須要清楚我們很大部分時間都是進行兩個對象的比較,這個時候Object的equals()方法就不可以了,所以才會有String這些類對equals方法的改寫,依次類推Double、Integer、Math。。。。等等這些類都是重寫了equals()方法的,從而進行的是內容的比較。希望大家不要搞混了。
改寫equals時總是要改寫hashcode
java.lnag.Object中對hashCode的約定:
- 在一個應用程序執行期間,如果一個對象的equals方法做比較所用到的信息沒有被修改的話,則對該對象調用hashCode方法多次,它必須始終如一地返回同一個整數。
- 如果兩個對象根據equals(Object o)方法是相等的,則調用這兩個對象中任一對象的hashCode方法必須產生相同的整數結果。
- 如果兩個對象根據equals(Object o)方法是不相等的,則調用這兩個對象中任一個對象的hashCode方法,不要求產生不同的整數結果。但如果能不同,則可能提高散列表的性能。
根據上一個問題,實際上我們已經能很簡單的解釋這一點了,比如改寫String中的equals為基于內容上的比較而不是內存地址的話,那么雖然equals相等,但并不代表內存地址相等,由hashcode方法的定義可知內存地址不同,沒改寫的hashcode值也可能不同。所以違背了第二條約定。
又如new一個對象,再new一個內容相等的對象,調用equals方法返回的true,但他們的hashcode值不同,將兩個對象存入HashSet中,會使得其中包含兩個相等的對象,因為是先檢索hashcode值,不等的情況下才會去比較equals方法的。
原創文章,轉載請標明出處







:版本庫中添加文件、版本回退)







...)



