
點擊藍字關注我
前面用了一篇文章詳細的介紹了集群HDFS文件系統的搭建,HDFS文件系統只是一個用于存儲數據的系統,它主要是用來服務于大數據計算框架,例如MapReduce、Spark,本文就接著上一篇文章來詳細介紹一下Spark集群的搭建及Spark的運行原理、運行模式。
—▼—
Spark集群環境搭建

如果已經理解了前文Hadoop集群環境的搭建,那么學習Spark集群環境的搭建會容易很多,因為Hadoop和Spark不僅安裝包目錄結構非常相似,在配置方面也十分接近。均是在master節點上進行所有配置,然后打包復制到每個slave節點,然后啟動集群Spark即可,下面就來詳細介紹一下Spark集群環境的搭建。
下載安裝
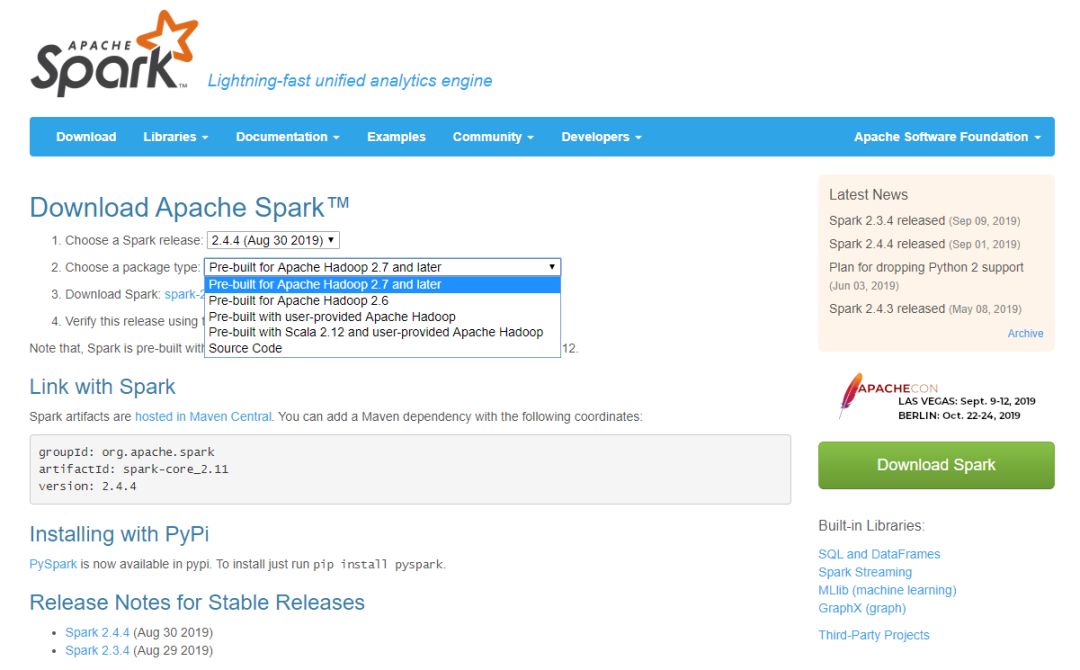
進入Spark的下載目錄,
https://spark.apache.org/downloads.html
可以看到Spark分多個版本,有基于Hadoop構建好的,有沒基于Hadoop構建的,有基于Hadoop2.6之前版本構建的,也有基于Hadoop2.7以后版本構建的,由于前面講解Hadoop集群環境搭建時采用的是Hadoop 3.2.1,因此,而且本文需要使用HDFS依賴Hadoop,因此需要下載Pre-built for Apache Hadoop 2.7 and later,
把spark-2.4.4-bin-hadoop2.7.tgz文件下載到home路徑下,然后解壓到指定目錄,
$?tar?-zxvf?~/spark-2.4.4-bin-hadoop2.7.tgz?-C?/usr/local/
然后進入目錄并像Hadoop那樣,修改Spark目錄的擁有者,
$?cd?/usr/local$?sudo?mv?./spark-2.4.4-bin-hadoop2.7?./spark$?sudo?chowm?-R?user_name?./spark
配置環境變量
修改bashrc,配置環境變量,把Spark的bin和sbin路徑加入到環境變量,
$?vim?~/.bashrcexport?SPARK_HOME=/usr/local/sparkexport?PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinexport?PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATHexport?PYSPARK_PYTHON=python3
Master節點配置
進入Spark目錄,修改spark-env.sh文件,
$?cd?/usr/local/spark$?vim?./conf/spark-env.sh
在spark-env.sh中添加下面內容,
export?SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop?classpath)export?HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoopexport?SPARK_MASTER_IP=10.110.113.132
SPARK_MASTER_IP指定的是master節點的IP,后面啟動集群Spark時slave節點會注冊到SPARK_MASTER_IP,如果這一項不配置,Spark集群則沒有可使用資源,
修改slaves文件
配置完master節點信息之后需要配置slave節點信息,slave節點的信息配置在slaves文件里,由于Spark目錄下沒有這個文件,因此需要首先從slaves.template拷貝一下,
$?cd?/usr/local/spark/$?cp?./conf/slaves.template?./conf/slaves
然后添加如下內容,
slave0slave0slave1
需要注意的是,slaves文件里配置的是運行作業任務的節點(worker),這樣的話master的節點只作為控制節點,而不作為工作節點,如果需要把master節點的資源也充分利用起來,需要把master節點也加入到slaves文件中。
slave節點配置
首先在master節點上把配制好的目錄進行打包,拷貝到每個slave節點上,
$?cd?/usr/local$?tar?-zcf?~/spar.tar.gz?./spark$?scp?~/spark/tar.gz?slave0:~/$?scp?~/spark/tar.gz?slave1:~/$?scp?~/spark/tar.gz?slave2:~/
然后在每個slave節點上執行下方命令,把文件解壓到相應路徑下,
$?sudo?rm?-rf?/usr/local/spark$?sudo?tar?-zxvf?~/spark.tar.gz?-C?/usr/local$?sudo?chown?-R?user_name?/usr/local/spark
這樣就完成了slave節點的配置。
啟動Spark集群
如果要使用HDFS的話,在啟動Spark集群前需要先啟動Hadoop集群,
$?cd?/usr/local/hadoop/$?./sbin/start-all.sh
然后進入Spark目錄,啟動Spark集群,
$?cd?/usr/local/spark$?./sbin/start-all.sh
需要說明一下,前面配置Hadoop集群是提到,需要配置ssh免密登陸,對于Spark也是同樣的道理,如果不配置ssh免密登陸的話,執行./sbin/start-all.sh會提示輸入密碼。
除了使用./sbin/start-all.sh啟動Spark集群外,還可以分開啟動,先啟動master節點,然后啟動slave節點,
$?./sbin/start-master.sh$?./sbin/start-slaves.sh
如果前面沒有完成Master節點配置指定master節點IP,那么執行./sbin/start-slaves.sh時則無法注冊master節點的IP,這樣集群計算資源則無法使用。除了配置spark-env.sh指定master節點IP外,還可以通過下面方式指定注冊的master節點IP,
$?./sbin/start-slave.sh?10.110.113.132
然后分別在master節點和slave節點執行下面命令會看到分別多出一個Master進程和Worker進程。
Spark基本使用
運行原理
如果使用過tensorflow的話,應該對Spark的使用很容易理解,Spark的計算過程和tensorflow有相似之處。
回憶一下,我們在使用tensorflow時需要首先構造一個計算圖,然后實例化一個session,然后用session.run來啟動圖運算。
其實Spark也是這樣,RDD(彈性分布式數據集)是Spark中最重要的概念之一,它提供了一個共享內存模型。Saprk的執行過程中主要包括兩個動作:轉換與行動。其中轉換操作就如同tensorflow中的構造計算圖的過程,在這個過程中Spark構造一個有向無環圖(DAG),但是不進行運算,輸入為RDD輸出則是一個不同的RDD,當執行行動操作時就如同tensorflow中的session.run,開始執行運算。
Spark中有很多轉換操作,例如,
groupByKey
reduceByKey
sortByKey
map
filter
join
……
行動操作包括,
count
collect
first
foreach
reduce
take
……
運行模式
Spark中通過master url來執行Spark的運行模式,Spark的運行模式包括本地運行、集群運行、yarn集群等,關于Spark master url的指定不同運行模式的含義如下,
| URL值 | 運行模式 |
|---|---|
| local | 使用1個線程本地化運行 |
| local[K] | 使用K個線程本地化運行 |
| local[*] | 使用邏輯CPU個數數量的線程來本地化運行 |
| spark://HOST:PORT | 指定集群模式運行Spark |
| yarn-cluster | 集群模式連接YARN集群 |
| yarn-client | 客戶端模式連接YARN集群 |
| mesos://HOST:PORT | 連接到指定的Mesos集群 |
示例
下面就以一個簡單的示例把前面Hadoop和Spark串聯在一起,講解一下HDFS+Spark的使用方法。上傳數據到HDFS新建一個hello_world.txt的本地文件,并在文件中添加3行hello world,然后上傳至HDFS,$?cd?/usr/local/hadoop/$?./bin/hdfs?dfs?-mkdir?-p?/usr/hadoop$?touch?hello_world.txt$?echo?-e?"hello?world?\nhello?world?\nhello?world"?>>?hello_world.txt$?./bin/hdfs?dfs?-put?./hello_world.txt?/usr/hadoopspark.py的Python文件,$?vim?spark.pyfrom?pyspark?import?SparkConffrom?pyspark?import?SparkContextconf?=?SparkConf().setAppName("FirstProject").setMaster("local[*]")sc?=?SparkContext.getOrCreate(conf)rdd?=?sc.textFile("hdfs:///master:9000/usr/hadoop/hello_world.txt")rdd.map(lambda?line:?line).foreach(print)$?python?spark.pyhello?worldhello?worldhello?world▲
END
 有趣的靈魂在等你
有趣的靈魂在等你 長按掃碼可關注?
相關文章效率工具 | 推薦一款提高Python編程效率的神器實用工具 | 推薦5款值得安裝的Windows工具學習資源 | 推薦2份Github熱門校招面試匯總資料文章好看就點這里


:版本庫中添加文件、版本回退)







...)








