來源:AINLPer微信公眾號
編輯: ShuYini
校稿: ShuYini
時間: 2019-8-16
引言
????很多人在使用pytorch的時候都會遇到優化器選擇的問題,今天就給大家介紹對比一下pytorch中常用的四種優化器。SGD、Momentum、RMSProp、Adam。
隨機梯度下降法(SGD)
算法介紹
????對比批量梯度下降法,假設從一批訓練樣本
???其中,
????基本策略可以理解為隨機梯度下降像是一個盲人下山,不用每走一步計算一次梯度,但是他總能下到山底,只不過過程會顯得扭扭曲曲。
算法評價
優點:
????雖然SGD需要走很多步的樣子,但是對梯度的要求很低(計算梯度快)。而對于引入噪聲,大量的理論和實踐工作證明,只要噪聲不是特別大,SGD都能很好地收斂。應用大型數據集時,訓練速度很快。比如每次從百萬數據樣本中,取幾百個數據點,算一個SGD梯度,更新一下模型參數。相比于標準梯度下降法的遍歷全部樣本,每輸入一個樣本更新一次參數,要快得多。
缺點:
????SGD在隨機選擇梯度的同時會引入噪聲,使得權值更新的方向不一定正確。此外,SGD也沒能單獨克服局部最優解的問題。
標準動量優化算法(Momentum)
算法介紹
????使用動量(Momentum)的隨機梯度下降法(SGD),主要思想是引入一個積攢歷史梯度信息動量來加速SGD。從訓練集中取一個大小為n的小批量
其中,
算法的理解
????動量主要解決SGD的兩個問題:一是隨機梯度的方法(引入的噪聲);二是Hessian矩陣病態問題(可以理解為SGD在收斂過程中和正確梯度相比來回擺動比較大的問題)。
????簡單理解:由于當前權值的改變會受到上一次權值改變的影響,類似于小球向下滾動的時候帶上了慣性。這樣可以加快小球向下滾動的速度。
RMSProp算法
算法介紹
????與動量梯度下降一樣,都是消除梯度下降過程中的擺動來加速梯度下降的方法。 梯度更新公式:
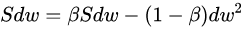
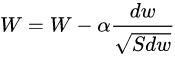
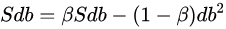
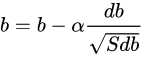
????更新權重的時候,使用除根號的方法,可以使較大的梯度大幅度變小,而較小的梯度小幅度變小,這樣就可以使較大梯度方向上的波動小下來,那么整個梯度下降的過程中擺動就會比較小,就能設置較大的learning-rate,使得學習步子變大,達到加快學習的目的。
????在實際的應用中,權重W或者b往往是很多維度權重集合,就是多維的,在進行除根號操作中,會將其中大的維度的梯度大幅降低,不是說權重W變化趨勢一樣。
????RMSProp算法在經驗上已經被證明是一種有效且實用的深度神經網絡優化算法。目前它是深度學習從業者經常采用的優化方法之一。
Adam算法
算法介紹
????Adam中動量直接并入了梯度一階矩(指數加權)的估計。其次,相比于缺少修正因子導致二階矩估計可能在訓練初期具有很高偏置的RMSProp,Adam包括偏置修正,修正從原點初始化的一階矩(動量項)和(非中心的)二階矩估計。Adam算法策略可以表示為:
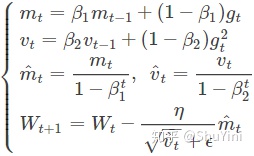
????其中,
算法分析
????該方法和RMSProp很像,除了使用的是平滑版的梯度m,而不是原始梯度dx。推薦參數值eps=1e-8, beta1=0.9, beta2=0.999。在實際操作中,推薦Adam作為默認算法,一般比RMSProp要好一點。
算法比較
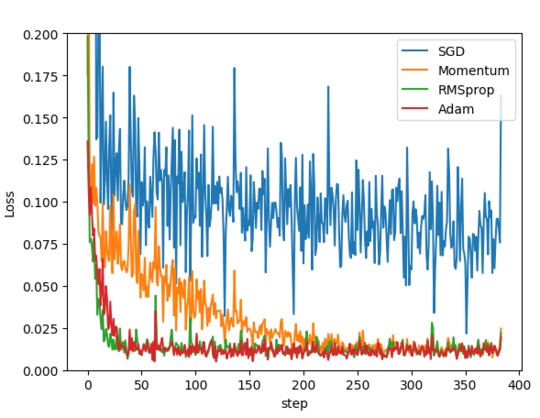
????為了驗證四種算法的性能,在pytorch中的對同一個網絡進行優化,比較四種算法損失函數隨著時間的變化情況。代碼如下:
opt_SGD=torch.optim.SGD(net_SGD.parameters(),lr=LR)
opt_Momentum=torch.optim.SGD(net_Momentum.parameters(),lr=LR,momentum=0.8)
opt_RMSprop=torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR,alpha=0.9)
opt_Adam=torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))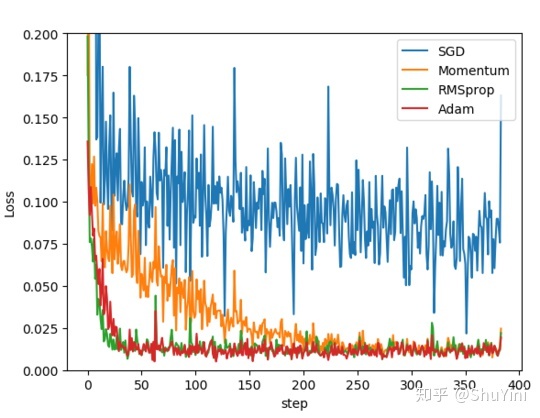
????SGD 是最普通的優化器, 也可以說沒有加速效果, 而 Momentum 是 SGD 的改良版, 它加入了動量原則. 后面的 RMSprop 又是 Momentum 的升級版. 而 Adam 又是 RMSprop 的升級版. 不過從這個結果中我們看到, Adam 的效果似乎比 RMSprop 要差一點. 所以說并不是越先進的優化器, 結果越佳。
參考:
https://blog.csdn.net/weixin_40170902/article/details/80092628
Attention
更多自然語言處理相關知識,還請關注AINLPer公眾號,極品干貨即刻送達。

 從傅里葉級數到傅里葉變換...)


:Mybatis初始化1.3 —— 解析sql片段和sql節點)


:動態節點解析2.1 —— SqlSource和SqlNode)

:動態節點解析2.2 —— SqlSourceBuilder與三種SqlSource)
與valueOf()的區別)

:結果集映射3.1 —— ResultSetBuilder與簡單映射)

:結果集映射3.2 —— 嵌套映射)




:結果集映射3.3 —— 主鍵生成策略)