2019獨角獸企業重金招聘Python工程師標準>>> 
PostgreSQL從9.6版本開始加入并行查詢,并在PostgreSQL10和PostgreSQL11分別做了大量加強工作。下面從:
- 何時啟用并行查詢功能
- 并行查詢是如何工作的
- worker進程數量越多,查詢性能越高嗎
?三個方面簡單介紹下并行查詢的機制。
--------------------------------------------------------------------------------
何時啟用并行查詢功能
? ? 是否啟用并行查詢實際上有諸多因素決定。總的來說,有以下兩個方面:
- ? ?并行查詢開關等參數
????????在PostgreSQL系統中,并行查詢的開關是max_parallel_workers_per_gather,它所表示的是單個Gather節點所能開啟的最大worker進程數量。當設置為0時,是?禁用并行查詢,即沒有可提供的并行查詢的worker進程;該參數的默認值是2,即每個Gather節點最多可以有2個worker進程。需要注意的是,postgresql.conf文件中還有一個名為force_parallel_mode的參數(看參數名感覺像是并行查詢的開關參數),其實它表示是否強制開啟并行查詢,多用于測試為目的。如果設置為on,則無論何時都會進行并行查詢(實際上,這時并不見得會帶來查詢效率的提高,后面會有介紹),其默認值為off,這時系統會根據具體成本考慮是否啟用并行查詢。
????? ? 在并行查詢中,每個worker進程都會承擔部分的查詢工作。除了上面說的max_parallel_workers_per_gather參數外,系統還有一個參數max_parallel_workers,它決定系統所支持的最大的worker進程的數量,所以max_parallel_workers_per_gather的設定必須參考max_parallel_workers的值。當然,它們都得受限于max_worker_process(系統允許后臺開啟worker進程的最大數量)參數。
- ? ?并行查詢成本考慮
????? ? 當參數決定可以進行并行查詢后,實際上是否可以進行并行查詢,還得進行一些成本上的考慮。因為并行查詢除了能帶來并行查詢上的效率外,還會有一些成本的消耗,比如并行帶來的數據分片,進程間的通信以及并發控制所帶來的的系統的開銷等。當數據量足夠大時,并行查詢帶來的效率可以抵消這些成本考慮;但是數據量比較小時,并行查詢可能不會帶來效率的提升,反而會降低了原有的性能。而對于并行帶來的成本,系統需要進行計算其代價,然后決定是否啟用并行查詢。
????? ? 在配置文件中,有專門對并行查詢成本的設置:
parallel_tuple_cost = 0.1 # 后天進程傳遞tuple的代價parallel_setup_cost = 1000.0 # worker進程的啟動成本min_parallel_table_scan_size = 8MB # 并行查詢規定表的最小數據量min_parallel_index_scan_size = 512kB # 并行查詢規定的索引的最小數據量????? ? 系統就是依托上面的參數進行計算并行查詢的成本。這些參數基本上采用默認值就好,當然除非有特殊要求或特殊環境。
并行查詢是如何工作
? ? 以普通查詢為例,下面看一下簡單查詢的示例:
highgo=# explain analyze select * from test where n = 9999;QUERY PLAN
------------------------------------------------------------------------------------------------------------------------Gather (cost=1000.00..11822.39 rows=3984 width=36) (actual time=2.014..196.880 rows=1 loops=1)Workers Planned: 2Workers Launched: 2-> Parallel Seq Scan on test (cost=0.00..10423.99 rows=1660 width=36) (actual time=76.604..141.282 rows=0 loops=3)Filter: (n = 9999)Rows Removed by Filter: 333333Planning time: 0.044 msExecution time: 196.904 ms
(8 行記錄)
通過EXPLAIN可以查看并行查詢的執行計劃。當用戶輸入一個查詢語句時,查詢分析,查詢重寫以及查詢規劃都和原來一樣,只有到執行計劃時,才開始真正進入并行查詢環節。上面執行計劃中,Gather節點只是執行計劃的一個子節點,屬于執行計劃的一部分,當查詢執行走到Gather節點時,會話進程會申請一定數量的worker進程(根據配置參數,以及成本確定)來進行并行查詢過程。在這些worker進程中,有一個充當leader worker的角色,負責收集匯總各個worker進程查詢的結果。該leader worker進程也會根據查詢的數據量大小承擔部分的并行查詢部分。執行過程如下圖所示:
?
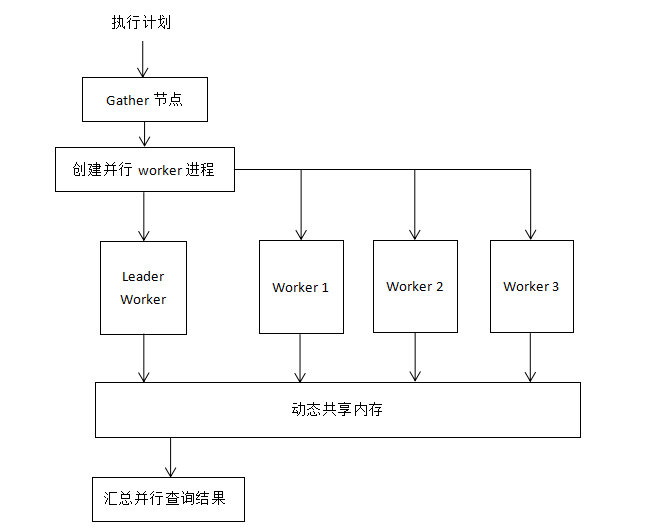
????? ? Leader worker進程和其他worker進程通過動態共享內存進行通信。其他worker進程(包括leader worker進程)把分擔查詢的結果存儲到共享內存中,然后由leader worker進程進行匯總整個查詢的結果。所以需要注意的是,由于并行查詢需要使用了動態共享內存,所以dynamic_shared_memory_type參數需要設置為none以外的值。
?
worker進程數量越多,查詢性能越高嗎
前面也提到,并不是所有的查詢都能適用于并行查詢。因為考慮到系統的開銷以及進程占用資源的情況,也并不是開啟的worker數量越多,查詢效率越高。下面以對同一個表做同樣的查詢,然后開啟不同的worker數量來測試一下。
- 開啟 1 個worker 進程
highgo=# explain analyze select * from test where n = 4000000;QUERY PLAN ----------------------------------------------------------------------------------------------Gather (cost=1000.00..59888.81 rows=1 width=4) (actual time=244.328..301.458 rows=1 loops=1)Workers Planned: 1Workers Launched: 1-> Parallel Seq Scan on test (cost=0.00..58888.71 rows=1 width=4) (actual time=268.845..297.372 rows=0 loops=2)Filter: (n = 4000000)Rows Removed by Filter: 2500000Planning time: 0.119 msExecution time: 302.026 ms
(8 rows)- 開啟 2 個worker 進程
highgo=# explain analyze select * from test where n = 4000000;QUERY PLAN ----------------------------------------------------------------------------------------------Gather (cost=1000.00..49165.77 rows=1 width=4) (actual time=218.212..218.287 rows=1 loops=1)Workers Planned: 2Workers Launched: 2-> Parallel Seq Scan on test (cost=0.00..48165.67 rows=1 width=4) (actual time=200.619..213.684 rows=0 loops=3)Filter: (n = 4000000)Rows Removed by Filter: 1666666Planning time: 0.117 msExecution time: 219.005 ms- 開啟 4 個worker 進程
????????設置4個worker,但是實際上基于成本考慮只啟用了3個。????
highgo=# explain analyze select * from test where n = 4000000;QUERY PLAN ---------------------------------------------------------------------------------------------Gather (cost=1000.00..43285.39 rows=1 width=4) (actual time=190.967..191.017 rows=1 loops=1)Workers Planned: 3Workers Launched: 3-> Parallel Seq Scan on test (cost=0.00..42285.29 rows=1 width=4) (actual time=174.275..182.767 rows=0 loops=4)Filter: (n = 4000000)Rows Removed by Filter: 1250000Planning time: 0.119 msExecution time: 191.817 ms
(8 rows)?
- 通過create table test(n int) with (parallel_workers = 4);強制啟動4個worker進程測試。
highgo=# explain analyze select * from test where n = 4000000;QUERY PLAN ----------------------------------------------------------------------------------------------Gather (cost=1000.00..38749.10 rows=1 width=4) (actual time=181.145..181.315 rows=1 loops=1)Workers Planned: 4Workers Launched: 4-> Parallel Seq Scan on test (cost=0.00..37749.00 rows=1 width=4) (actual time=163.565..169.837 rows=0 loops=5)Filter: (n = 4000000)Rows Removed by Filter: 1000000Planning time: 0.050 msExecution time: 185.391 ms對比查詢結果:
| 1 worker 進程 | 2 worker 進程 | 3 worker 進程 | 4 worker 進程 |
| 302.026 ms | 219.005 ms | 191.817 ms | 185.391 ms |
可以看出,查詢效率并沒有隨worker數量線性增加;在啟用3個worker進程 和 4個worker進程進行并行查詢時,查詢效率基本一致了。所以并不是開啟的worker數量越多,查詢效率越高,這個也是系統有成本考慮在內。
?
?






的掛載)
![[深度概念]·K-Fold 交叉驗證 (Cross-Validation)的理解與應用](http://pic.xiahunao.cn/[深度概念]·K-Fold 交叉驗證 (Cross-Validation)的理解與應用)









期末練習題)

