KL 散度的使用場景
KL散度( Kullback–Leibler divergence),又稱相對熵,是描述兩個概率分布 P 和 Q 差異的一種方法
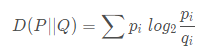
torch.nn.functional.kl_div(input, target, size_average=None, reduce=None, reduction='mean')
torch.nn.KLDivLoss(input, target, size_average=None, reduce=None, reduction='mean')
第一個參數傳入的是一個對數概率矩陣,第二個參數傳入的是概率矩陣。并且因為kl散度具有不對稱性,存在一個指導和被指導的關系,因此這連個矩陣輸入的順序需要確定一下。如果現在想用Y指導X,第一個參數要傳X,第二個要傳Y。就是被指導的放在前面,然后求相應的概率和對數概率就可以了。
所以,一隨機初始化一個tensor為例,對于第一個輸入,我們需要先對這個tensor進行softmax(確保各維度和為1),然后再取log;對于第二個輸入,我們需要對這個tensor進行softmax。
import torch
import torch.nn.functional as Fa = torch.tensor([[0,0,1.1,2,0,10,0],[0,0,1,2,0,10,0]])
log_a =F.log_softmax(a)b = torch.tensor([[0,0,1.1,2,0,7,0],[0,0,1,2,0,10,0]])
softmax_b =F.softmax(b,dim=-1)kl_mean = F.kl_div(log_a, softmax_b, reduction='mean')
print(kl_mean)





,torch.cuda.device_count(),torch.cuda.get_device_name(0))





)

)
)
時間單位(ms μs ns ps)長度單位(dm cm mm μm nm pm fm am zm ym))



