目錄
1 Hbase簡介
1.1 初識Hbase
1.2 Hbase的特性
2 HDFS專項模塊
2.1 HDFS的基本架構
2.1.1?HDFS各組件的功能:
2.2 HFDFS多種機制
2.2.1 分塊機制
2.2.2 副本機制
2.2.3 容錯機制
2.2.4 讀寫機制
?3 Hbase組件及其功能
?3.1?客戶端
3.2 Zookeeper
3.3 HMaster
3.4 RegionServer
4 Hbase數據模型及Hbase Shell
5 Hbase原理實現
5.1 Region定位
5.1.1 Region
5.1.2 Meta表
5.1.3 Region查找
5.2 Region再細分
5.2.1 Hbase寫數據
?5.2.2 Hbase讀數據
5.2.3 HFile的合并(Minor|Major)
5.3 WAL機制
?5.4 Region拆分
5.5 Region合并
1 Hbase簡介
1.1 初識Hbase
????????Hbase全拼為Hadoop database即分布式存儲數據庫,是一個可以進行隨機訪問的存儲和檢索數據的平臺,用于存儲結構化和半結構化的數據,如果數據量不是非常龐大的情況下,Hbase甚至可以存儲非結構化的數據。Hbase作為Apache基金會Hadoop項目的一部分,使用Java語言實現,將HDFS作為底層文件存儲系統,在此基礎上運行MapReduce分布式批量處理數據,為Hadoop提供海量的數據管理服務。?
? ? ? ? Hbase是典型的NoSQL數據庫,通常被描述為稀疏的、分布式的、持久化的,由行鍵、列鍵和時間戳進行索引的多維有序映射數據庫,主要用來儲存結構化和半結構化的數據。Hbase是Google的Bigtable的開源實現。
1.2 Hbase的特性
🌈容量巨大
🌈列存儲
🌈稀疏性
????????傳統的關型數據庫中,每一行的數據類型都是事先定義好的,會占用固定的內存空間,在此情況下NULL值也會占用一定的存儲空間。而在Hbase中的數據都是以字符串形式存儲,數據為空的情況下列并不占用存儲空間,因為會有部分數據有真實值,部分數據為NULL,故稱為稀疏性。
🌈擴展性強
? ? ? ? Hbase構建在HDFS之上,理所當然的支持分布式表,也繼承了HDFS的可擴展性。Hbase是橫向擴展的,所謂的橫向擴展是指在擴展時不需要提過服務器本身的性能,只需要添加不同的服務器節點到現有的集群即可。Hbase根據Region的大小進行分區,分別存在集群中的不同節點,當添加新節點時,集群自動重新調整,在新的節點啟動Hbase服務器,實現動態擴展。Hbase的擴展是熱擴展,即在不停掉現有服務的情況下進行服務節點的增加和刪除。
🌈高可靠性
? ? ? ? Hbase同時繼承了HDFS的高可靠性,HDFS的多副本機制可以讓它在出現故障時自動恢復,同時Hbase內部也提供了預寫日志(Write-Ahead-Log,WAL)和Replication機制。
2 HDFS專項模塊
????????HDFS即Hadoop Distributed File System(Hadoop分布式文件系統),HDFS是參考Google公司的GFS實現的,不管是HDFS還是GFS計算機節點都會很容易出現硬件故障,HDFS的數據分塊儲存在不同節點,當某個節點出現故障時,HDFS相關組件會快速檢測出節點故障并提供容錯機制完成數據的自動恢復。
2.1 HDFS的基本架構
? ? ? ? 三個組件:NameNode、DataNode、SecondaryNameNode
? ? ? ? 一個架構:主從架構(Master/Slave模式)
? ? ? ? HDFS集群一般由一個NameNode(運行在Master節點)、一個SecondaryNameNode(運行在Master節點)和許多個DataNode(運行在Salve節點)組成。在HDFS中數據是被分塊進行儲存,一個文件可以被分為許多個塊,每個塊被存儲在不同的DataNode上。
????????????????????????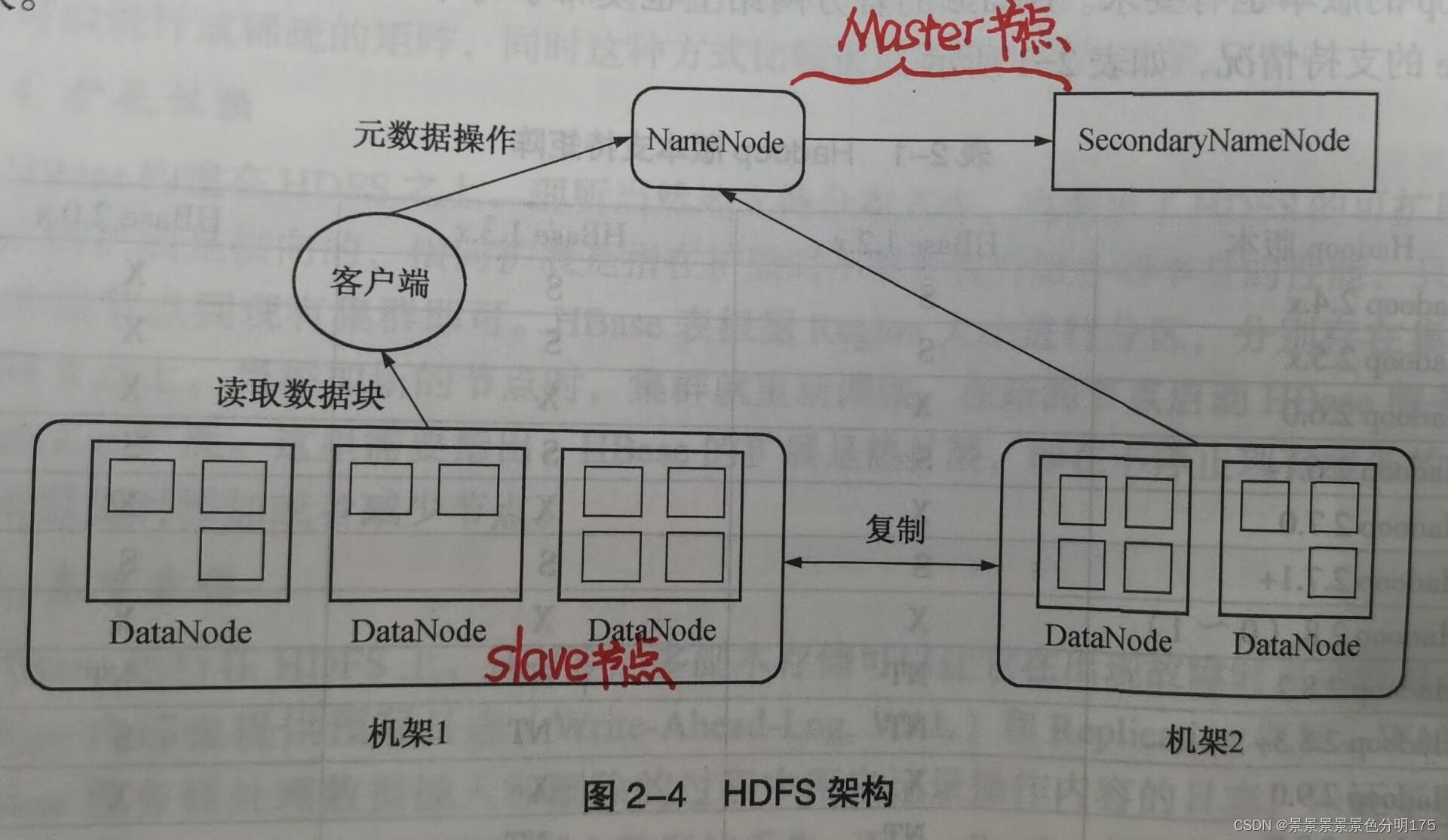
2.1.1?HDFS各組件的功能:
- 🌈NameNode
- 將文件的元數據信息存儲在edits和fsimage文件中(元數據信息記錄了文件系統中的文件名和目錄名,以及它們之間的層級關系,同時也記錄了每個文件目錄的所有者以及權限,甚至還記錄了每個文件是由哪些塊組成)
- 接收客戶端的請求并提供元數據(當客戶端請求讀取文件時,會先從NameNode獲取文件的元數據信息,然后再往元數據中對應的DataNode讀取數據塊)
- 通過心跳機制檢測DataNode的狀態,當出現節點故障時,重新分配失敗的任務。
- 🌈SecondaryNameNode
- 定期合并edits和fsimage文件
? ? ? ? ? edits文件(編輯日志)用來記錄文件的增、刪、改操作信息。
? ? ? ? ? fsimage文件(鏡像文件)用來維護HDFS的文件和文件夾的元數據信息。
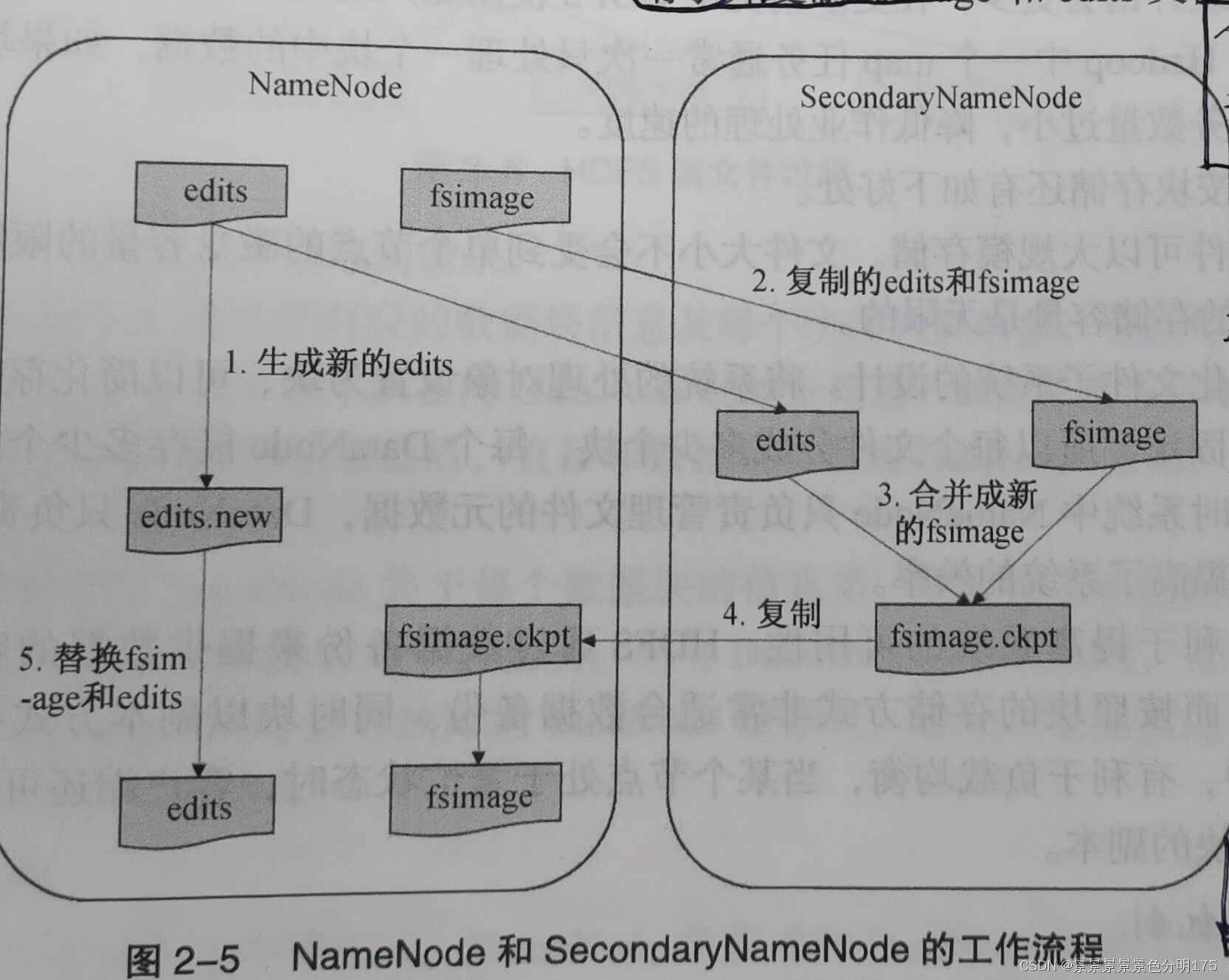
? ? ? ? ? 每次系統啟動時,NameNode會讀取fsimage文件的信息并保存到內從中。在HDFS運行期間,新的操作日志不會立即與fsimage文件進行合并,也不會存到NameNode內存中,而是先寫到edits文件中,當edits文件達到一定的閾值或者間隔一定時間(默認為3600s或者達到64MB)后會觸發SecondaryNameNode工作,這個時間點被稱為checkpoint。具體的合并步驟如下:
???????????????????????? ?
?
- (停用和新記錄)在合并之前SecondaryNameNode通知NameNode停用當前editlog文件,并將新的操作日志寫入到新的editlog.new文件。
- (請求并復制)SecondaryNameNode從NameNode請求并復制fsimage和edits文件。
- (合并)SecondaryNameNode把fsimage和edits文件合并,并重命名為fsimage.ckpt。
- (兩次替換)NameNode從SecondaryNameNode獲取fsimage.ckpt文件,并替換掉fsimage文件,同時用edits.new文件替換舊的edits文件。
- (更新)更新checkpoint的時間。自此,fsimage文件中保存的是上一個checkpoint的元數據信息,而edits文件保存的是從上一個checkpoint開始的操作日志。
- 🌈DataNode
- 存儲數據塊
- 為客戶端提供數據塊的讀寫服務
- 相應NameNode的相關指令(數據塊的增、刪、改等操作)
- 定時發送心跳信息給NameNode
2.2 HFDFS多種機制
2.2.1 分塊機制
在HDFS中數據是被分塊進行儲存,一個文件可以被分為許多個塊,每個塊被存儲在不同的DataNode上。HDFS數據塊大小默認為64MB,而一般磁盤塊的大小為512B。
2.2.2 副本機制
HDFS中數據塊的副本數默認為3個,當然也可以設置更多的副本集。在默認副本集為3的情況下,0.17版本之前,會把第一個副本放在一個機架的一個DataNode上,第二個副本放在這個機架的另一個DataNode上,而第三個副本會放在不同的機架上;0.17版本之后,會把第一個副本放在一個機架的一個DataNode上,第二個副本放在另一個機架的DataNode上,而第三個副本會放在第二個副本的同機架的不同DataNode上。(機架的概念參照上圖2-4)
2.2.3 容錯機制
NameNode出錯:從SecondaryNameNode備份的fsimage文件進行恢復。
DataNode出錯:當出現節點故障時,重新分配失敗的任務。
數據出錯:數據寫入的同時保存總和校驗碼,讀取數據時進行校驗。
2.2.4 讀寫機制
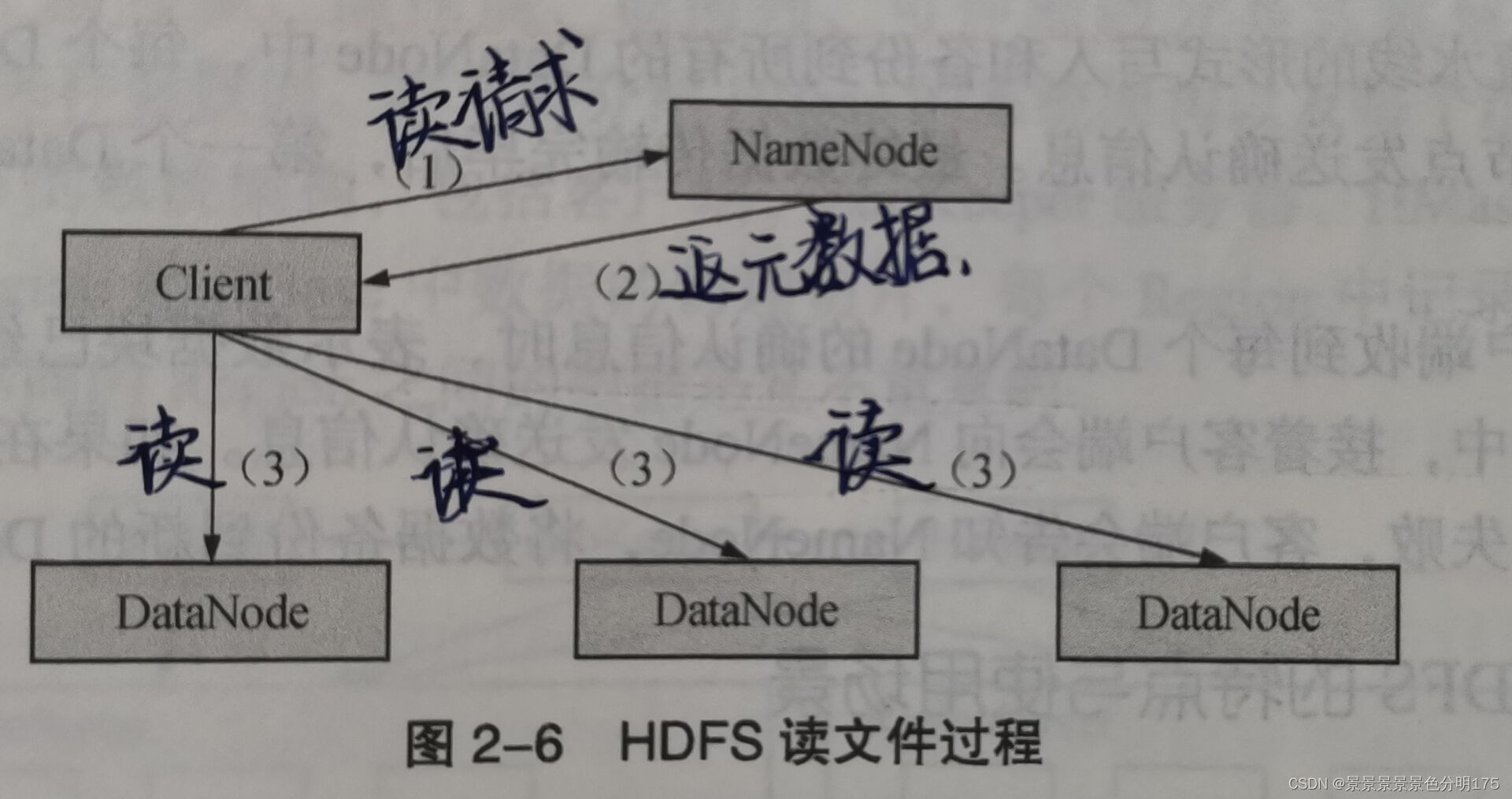
🌈讀文件
- (發送請求)客戶端向NameNode發送讀文件請求
- (得到地址)NameNode返回文件的元數據(文件對應的數據塊信息及各數據塊位置及其副本位置)信息
- (讀取數據)客戶端按照元數據信息與DataNode進行通信,并讀取數據塊。????????
?????????????????????????
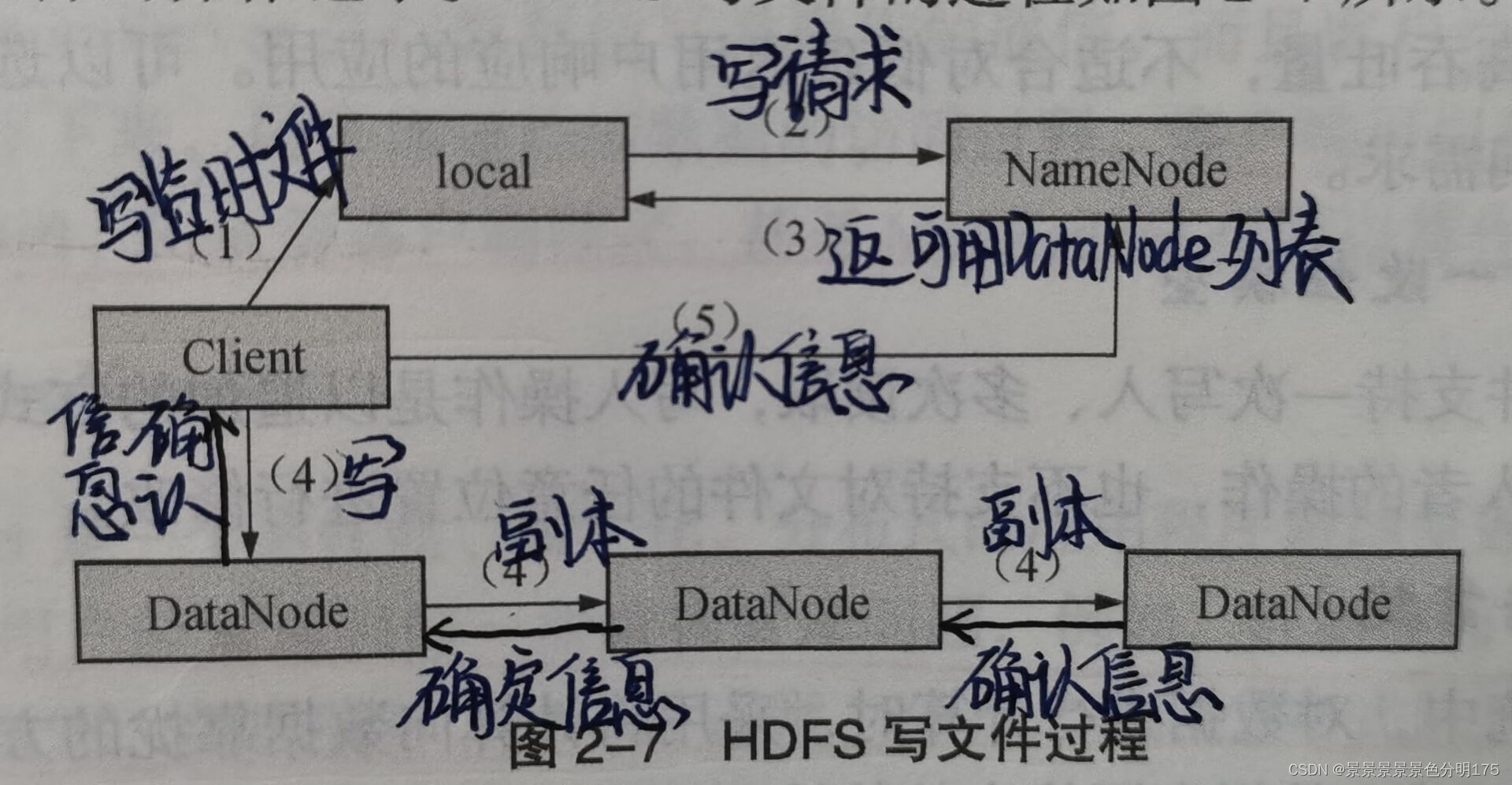
🌈寫文件
- (暫寫數據)先將數據寫入本地的臨時文件
- (發送請求)等臨時文件大小達到系統設置的塊大小時,開始向NameNode發送寫文件請求
- (獲取地址)NameNode檢查集群中每個DataNode的狀態信息,獲取空閑節點并檢查客戶端的權限符合后再創建文件,然后返回數據塊及其對應DataNode的地址列表給客戶端,列表中包括副本的存放地址。
- (寫數據并發送確認信息)客戶端將臨時文件的數據塊寫入列表的第一個DataNode,同時第一個DataNode以副本的形式傳送至第二個DataNode,第二個DataNode以副本的形式傳送至第三個DataNode。每一個DataNode在接收到數據后都會向前一個節點發送確認信息,數據傳輸完成后,第一個DataNode會向客戶端發送確認信息。
- (錯誤處理)客戶端收到確認信息表示數據塊已經永久化的存儲在所有的DataNode中,此時客戶端會向NameNode發送確認信息。一旦上一步的任何一個DataNode存儲失敗未發送確認信息,客戶端就會告知NameNode,將數據備份到新的DataNode中。
????????????????????????
?3 Hbase組件及其功能
?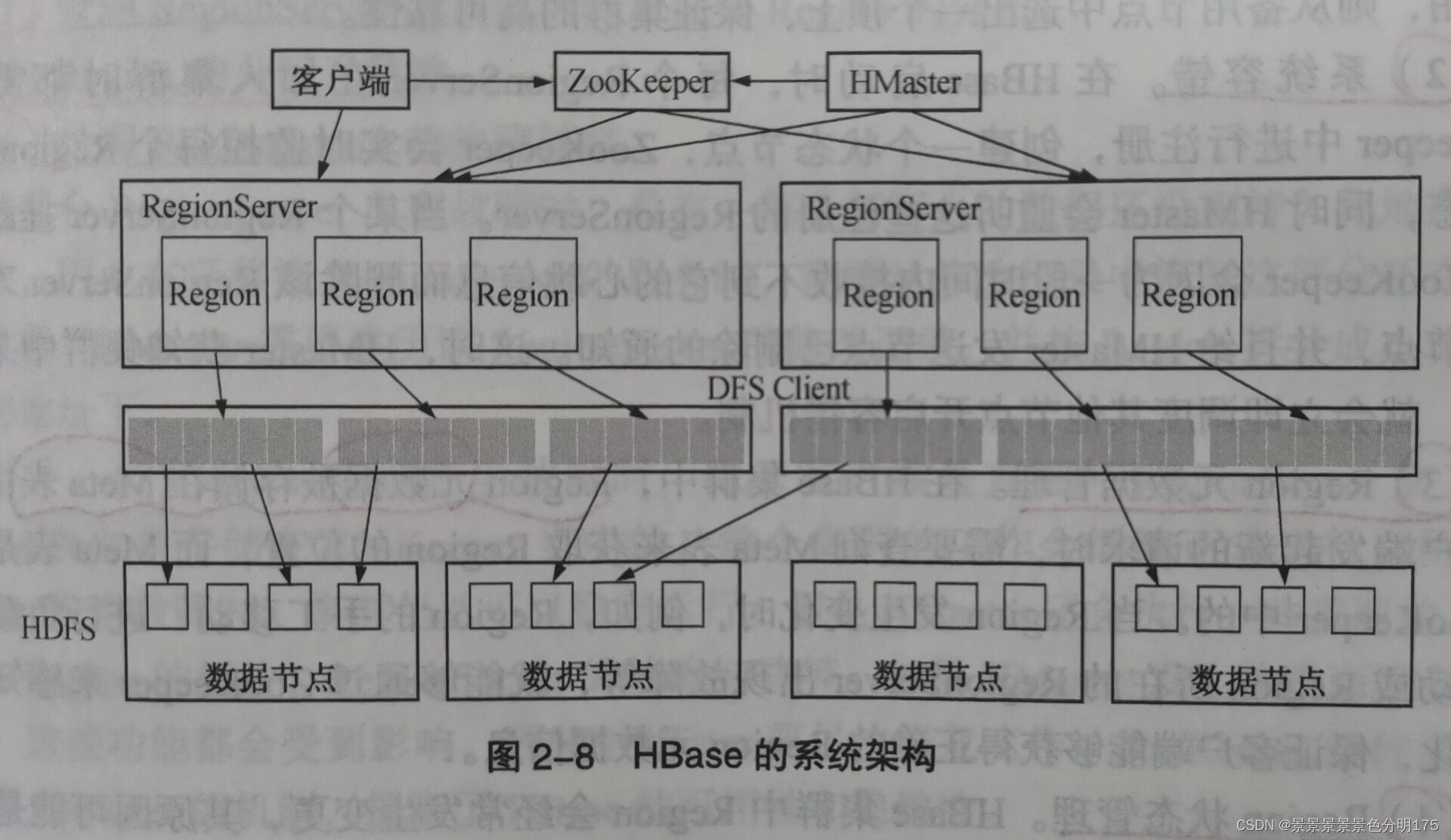
?3.1?客戶端
客戶端包含訪問Hbase的接口,是整個Hbase系統的入口,使用者通過客戶端操作Hbase,客戶端使用Hbase的RPC機制與HMaster和RegionServer進行通信。
3.2 Zookeeper
Zookeeper是一個高性能、集中化、分布式的應用程序協調服務,主要用來解決分布式應用中用戶遇到的數據管理問題。在Hadoop中Zookeeper主要用于實現高可靠性(High Availability,HA),包括HDFS的NameNode和YARN的ResourceManager的HA。以HDFS為例,NameNode作為HDFS的主節點,負責管理文件系統的命名空間以及客戶端對文件的訪問,同時還需要監控整個HDFS中每個DataNode的狀態,實現負載均衡和容錯。為了實現HA需要由多個NameNode并存,一個處于活躍狀態其他則是備用狀態,當處于活躍狀態的NameNode無法正常工作時,處于備用狀態的節點會通過競爭選舉產生新的活躍節點。Zookeeper在Hbase中的功能如下:
- Master選舉
????????與HDFS中的競選機制一樣,Hbase中有多個Master并存,但只有一個HMaster處于活躍狀態,當處于活躍狀態的HMaster無法正常工作時,從其余備用Master中通過選舉出一個新的HMaster,保證集群的高可靠性。
- 系統容錯
? ? ? ? 在Hbase啟動時,每個RegionServer在加入集群時都需要到Zookeeper中進行注冊,創建一個狀態節點,Zookeeper會實時監控每個RegionServer狀態,當某個RegionServer掛掉時,Zookeeper會因為一段時間內沒有接收到其心跳信息而刪除該RegionServer對應的節點,并給HMaster發送節點刪除通知,HMaster得知有RegionServer斷開,會立即開啟RegionServer容錯機制參考博客
- Region元數據管理
? ? ? ? 在Hbase集群中,Region元數據被存儲在Zookeeper中的Meta表里。每次客戶端發起新的請求時,需要先查詢Meta表中的Region的位置,當Region發生任何變更時,就能通過Zookeeper的Mate表來感知這一變化,保證客戶端能夠獲取到正確的Region元數據信息。
- Region狀態管理
? ? ? ? Hbase中的Region會經常發生變更,其原因可能是系統故障、配置修改、Region的分裂及合并。只要Region發生任何變化,就需要使集群中的所有節點都知曉,然而集群中的Region數量會達到十萬級甚至更多,如果交由Hbase處理則負擔過大,所以只能依賴Zookeeper來完成。
- 提供Meta表存儲位置
????????Meta表中存儲的數據庫信息、列族信息、列族存儲位置信息都屬于元數據,而Mate表的位置入口由Zookeeper提供。
3.3 HMaster
- 管理用戶對表的增、刪、改、查操作。HMaster提供了對所有元數據增刪改查的接口,便于用戶與Hbase進行交互。
- 管理RegionServer的負載均衡,調整Region的分布。
- Region的分配與移除。
- 處理RegionServer的故障轉移。
3.4 RegionServer
????????RegionServer主要負責響應用戶的請求,向HDFS讀寫數據,一般在分布式集群中,RegionServer運行在DataNode服務器上,實現數據的本地性。
- 處理分配給它的Region
- 處理客戶DAU你的讀寫請求
- 刷新緩存到HDFS
- 處理Region分片
- 執行壓縮?
4 Hbase數據模型及Hbase Shell
Hbase數據模型及Hbase Shell_扎哇太棗糕的博客-CSDN博客
5 Hbase原理實現
5.1 Region定位
5.1.1 Region
????????在Hbase中,表中的行都是按照RowKey的字典順序進行排序,表在行的方向上被分割成多個Region。每一張表一開始就只有一個Region,隨著數據的不斷插入,Hbase會根據一定的規則將表進行水平拆分最終形成多個Region。Region過多一臺機器無法存儲的下時,可分布式存儲到多臺機器上,HMaster將不同的Region分配到不同的RegionServer上。
????????????????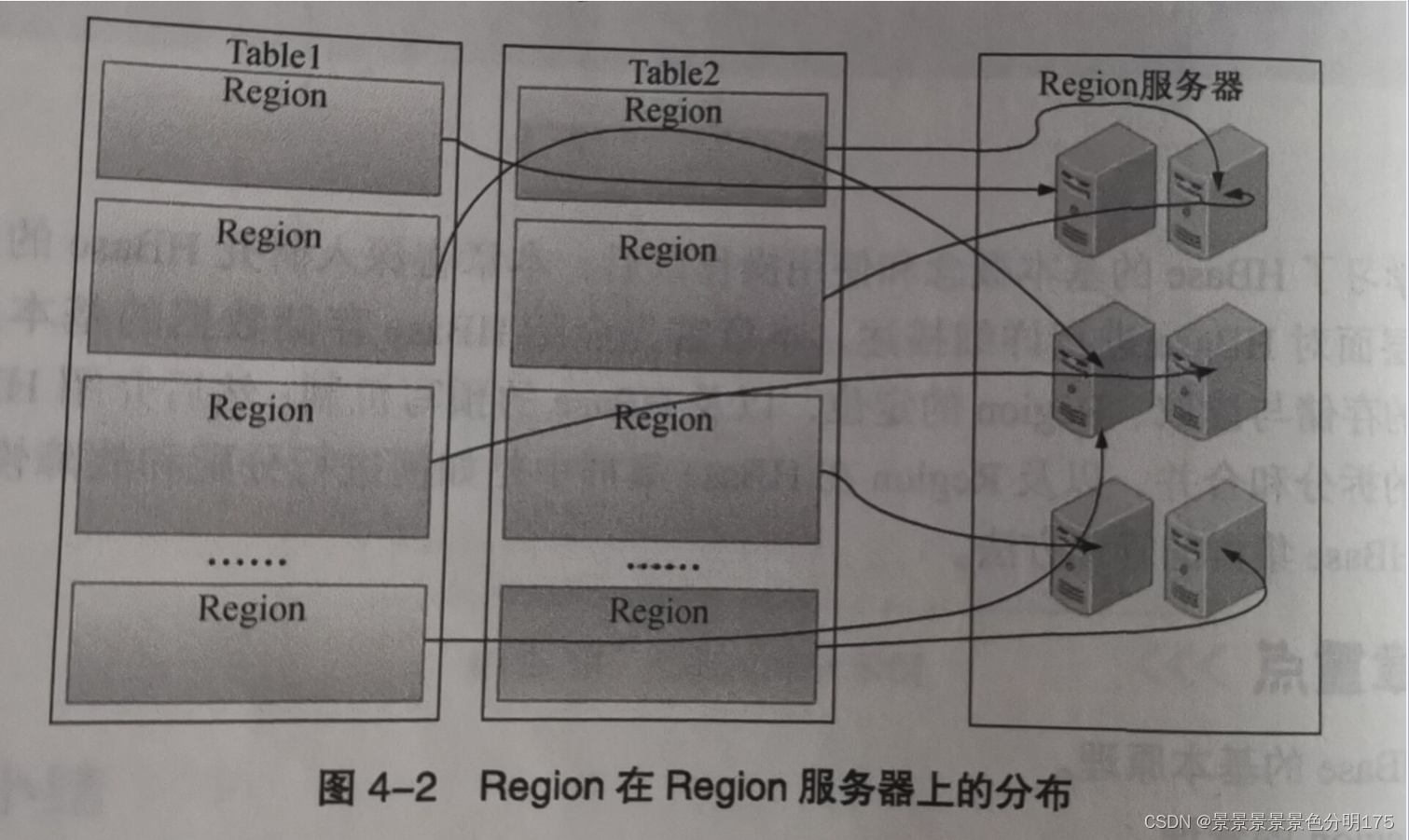
?????????客戶端在對表彰數據進行增刪改查時需要知道數據存儲在哪個RegionServer上,這個查找Region的過程就叫做Region定位。Region標識符可以唯一標志一個Region,Region標識符 = 表名+起始行鍵+時間戳+RegionID,其中RegionID等于(表名+起始行鍵+時間戳)進行MD5加密。其中第一個Region沒有首行,最后一個Region沒有末行。
5.1.2 Meta表
????????Meta映射表的每個條目包含兩項內容:Region標識、RegionServer標識,該條目表示了Region與RegionServer之間的對應關系,可以讓用戶知道該Region存儲在哪個RegionServer上。總而言之,Meta表記錄了元數據信息,使Region的定位變得精準且快速。
5.1.3 Region查找
? ? ? ? 早期的Region查找使用三層架構:首先訪問zookeeper的/hbase/root-region-server節點來得知ROOT表在哪個RegionServer上,然后訪問ROOT表獲取數據所在Meta表以及Meta表所在RegionServer的位置,接著訪問META表找到數據所在的Region去訪問。后來改為二層架構:客戶端先通過查找ZooKeeper的Meta表,獲取到查詢的數據的Region元數據信息,按照元數據信息獲取到相應的數據。
參考博客:HBase查詢機制--Region定位_Fys的博客-CSDN博客_查看hbase 表的region
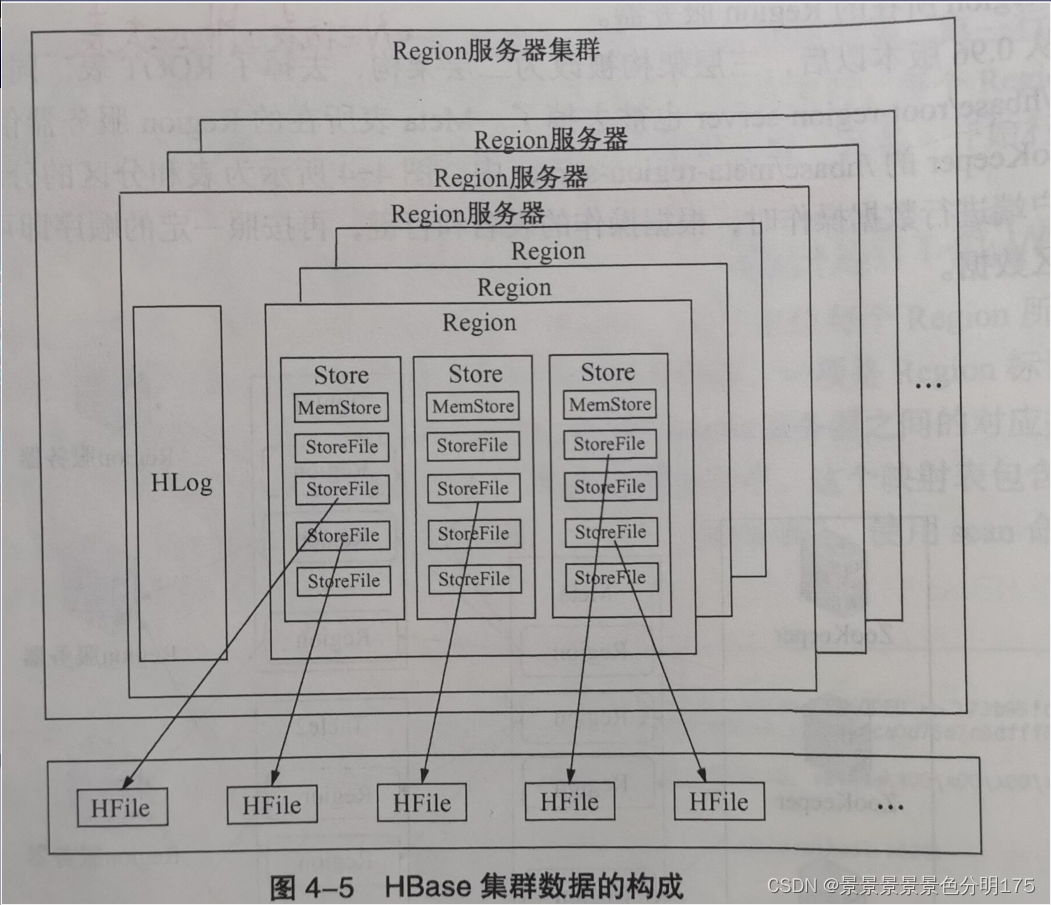
5.2 Region再細分
????????Hbase的核心模塊是RegionServer,RegionServer又由HLog和Region構成,Region存儲著一系列連續的數據集。Region對應著和多個的Store,每個Store對應著表中的一個列族的存儲,Store又是由一個MemStore和零到多個的StoreFile組成,StoreFile的底層是用HFile實現,也可以說StoreFile就是HFile。
????????????????????????
5.2.1 Hbase寫數據
- (獲取元數據)客戶端訪問Zookeeper,從Meta表中得到數據寫入的Region和RegionServer的相關信息
- (兩次寫信息)客戶端按照Zookeeper返回的相關信息,直接訪問RegionServer把數據分別寫入HLog和MemStore。
- (持久化數據)當MemStore的存儲量達到一定閾值(默認64M)時,會把數據寫入磁盤文件StoreFile中,并在HLog中寫入一個標記表示MemStore中的緩存數據寫入到StoreFile中。如果MemStore中的數據丟失,則可以在HLog中恢復。
- (StoreFile合并分裂)StoreFile文件的數量達到一定的數量時,會觸發合并成一個大的StoreFile,當StoreFile的文件大小超過一定的閾值時,大StoreFile會分裂成兩個StoreFile。同時,當前父Region會分裂成兩個子Region,父Region下線,兩個子Region被Master分配到相應的RegionServer(父Region拆分的原因參考 5.4Region拆分)。
?5.2.2 Hbase讀數據
- (獲取元數據)客戶端訪問Zookeeper,從Meta表中得到讀取數據的Region和RegionServer的相關信息
- (發送請求)客戶端向對應的RegionServer發送讀取數據請求
- (查找數據)RegionServer在就收到請求消息之后,現在MemStore中查找數據,如果沒有就到StoreFile中讀取,最后將數據返回給客戶端。
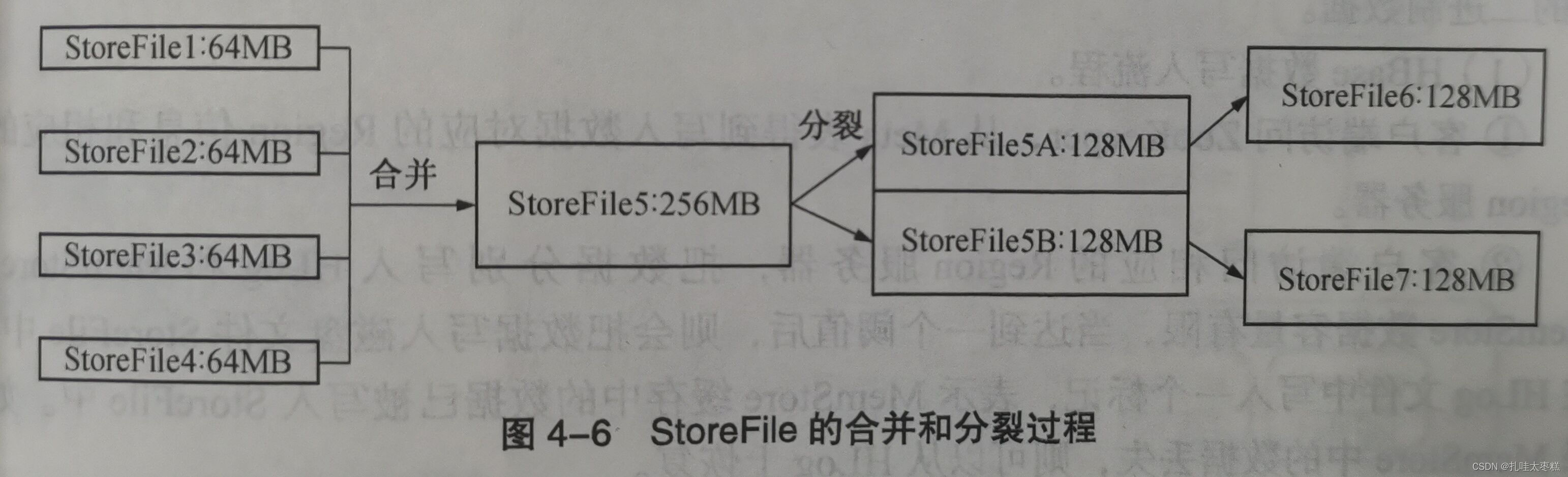
5.2.3 HFile的合并(Minor|Major)
Minor合并(滿足條件的小HFile進行合并)
????????執行合并時,Hbase將多個小HFile的內容讀出并寫入到一個新的文件中,然后激活新文件,舊文件標記為刪除,被標記后的舊文件只有在下一次Major合并時才會被刪除,在此之前仍會出現在HFile中。HFile的Minor合并是觸發式的,觸發條件很多,比如在將MemStore中的數據刷新到HFile中時會申請對符合條件的HFile進行合并,定期合并等。除此之外,對選擇進行合并的HFile文件也是有條件的,條件如下:
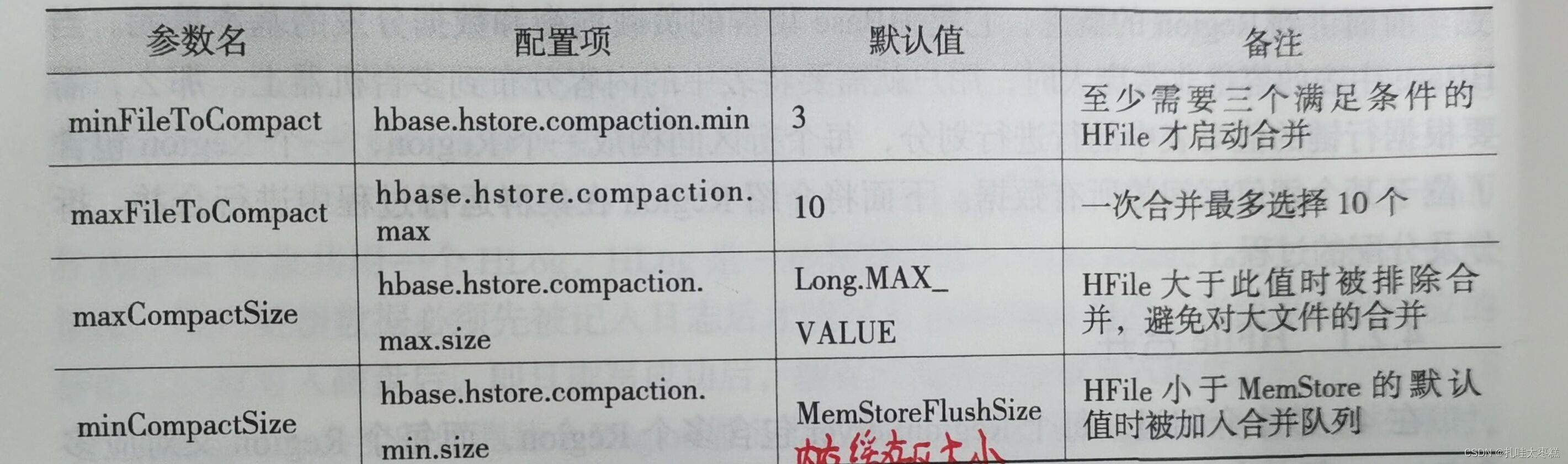
?也就是說,一次Minor合并的HFile文件的個數在3~10個之間。
Major合并(無差別合并)
????????Major合并會對Store中的所有HFile文件進行無差別的合并,甚至有時會將整個表中同一列族的HFile進行合并,這是一個耗時且耗費資源的操作,很影響集群的性能。故一般情況下都只做Minor合并,不做甚至有些集群干脆就禁止Major合并,只有在集群負載較小時才進行手動的Major合并,或者配置Major的合并中期,默認為7天。
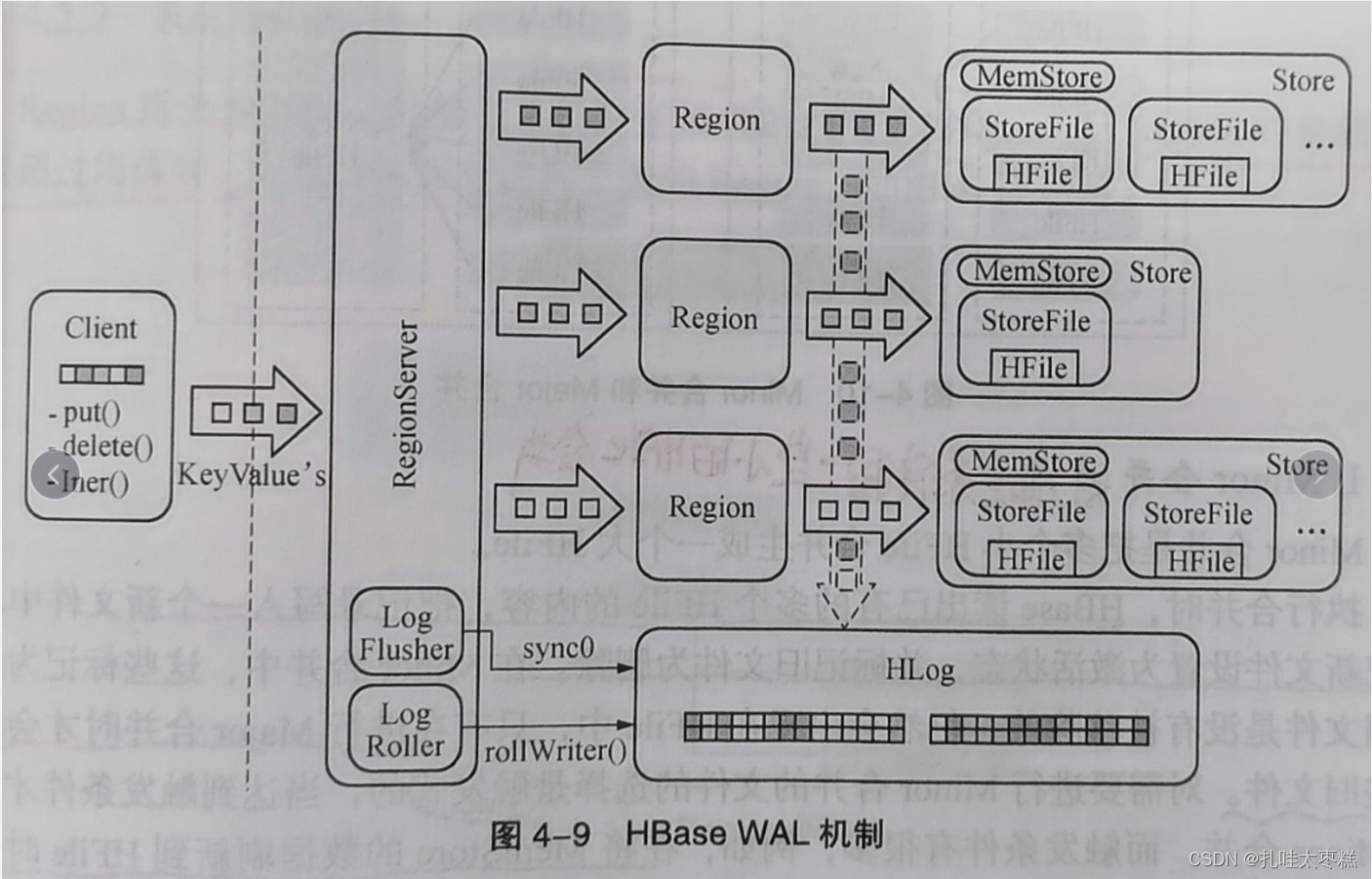
5.3 WAL機制
????????WAL就是(Write Ahead Log),字面翻譯就是預寫日志文件機制。如下圖所示,每個RegionServer中的所有Region共用一個HLog文件,HLog就是上面說到的預寫日志文件,也就是說,每當客戶端更寫數據必須先寫入到HLog文件后才能被寫入到MemStore中。
? ? ? ? 故障轉移:Zookeeper會實時監控每個Regionserver的狀態,當某個RegionServer故障時,RegionServer在Zookeeper上的臨時節點就會過期,Zookeeper會首先通知Master,Master會第一時間處理該RegionServer上的HLog文件,對其按照Region進行拆分并放到相應Region的目錄下,等到Region被重新分配到可用的RegionServer上時,按照Region目錄下的HLog進行數據恢復。
?5.4 Region拆分
????????一旦Region的負載過大或者超過閾值時(Region中最大的Store的大小大于設置的閾值時就會觸發Region拆分),它就會被拆分成兩個新的Region,這個過程是由RegionServer來完成的,具體流程如下:
- (下線并阻止請求)下線需要拆分的Region,阻止所有對該Region的客戶端請求,Master檢測到Region的狀態為SPLITING。
- (建立引用文件并指向)在父Region的下面建立兩個引用文件,分別指向父Region的首行與末行,此時并不會開始復制數據。
- (建立目錄并復制)在HDFS上建立兩個子Region的目錄,分別復制上一步建立的引用文件,每個子Region分別占用父Region的一半數據,復制完成后刪除兩個引用文件。
- (更新Meta表元數據)完成子Region的創建后,向Meta表發送新產生的兩個Region的元數據信息,刪除父Region的元數據信息。
- (更新狀態)將Region的拆分信息更新到HMaster中,并且每個Region進入可用狀態。
5.5 Region合并
- (發送請求)客戶端發送Region合并請求給Master。
- (聚堆并發送請求)Master在RegionServer上將Region移到一起,并發起一個Region合并操作的請求。
- (下線并合并)RegionServer將準備合并的Region下線,然后進行合并。
- (更新元數據)從Meta表上刪除被合并的Region的元數據,并寫入新的Region的元數據。
- (更新狀態及信息)新的Region設置上線,同時更新Region信息到Master。
????????Region合并的必要性:Region過多會導致Meta表過大,Zookeeper管理不過來,從而影響客戶端的請求響應。

)

)
)
時間單位(ms μs ns ps)長度單位(dm cm mm μm nm pm fm am zm ym))








)


,計算字符串或者是文本之間的相似度【附代碼】)
學在Java語法之前)
 注釋 數據類型 變量 常量 關鍵字 標識符 運算符 輸入輸出)