目錄
1 數據庫操作
2 集合操作
3 文檔操作
3.1 插入文檔(insert|insertOne|insertMany)
3.2插入、刪除的循環操作
3.2?刪除文檔(remove|deleteOne|deleteMany)
3.3?更新文檔(update|save)
3.4?查詢文檔(find)
4 游標
5 索引
6 聚合
1 數據庫操作
? ? ? ? 當新創建的數據庫里沒有插入數據時,并不會被查詢到相應的信息,只有插入數據的數據庫才會顯示其相應的信息。
????????在對某個數據庫進行相關操作時,需先使用use命令選擇執行該數據庫。
#創建數據庫myDB(use命令在數據庫已存在時就是選擇執行,否則就是創建)
use myDB#查看數據庫
show dbs#選擇執行myDB數據庫
use myDB#統計數據信息
db.stats()#查看當前數據庫下的所有集合
show collections
db.getCollectionNames()#刪除當前數據庫
db.dropDatabase()2 集合操作
🏅普通集合操作
#創建集合
db.createCollection("myCollection") //顯式創建myCollection
sb.stu.insert({name: "jack"}) //隱式創建stu#查詢集合
show collections#查看集合的詳細信息
db.getCollectionInfos()#集合重命名
db.myCollection.renameCollection("myColl")#查看集合統計信息
db.myCollecyion.stats()#刪除集合
db.myCollection.drop()🏅定長集合操作
#定長集合的創建
db.createCollection("myCollection",{capped:true,size:3})#判斷集合是否為定長集合
db.myCollection.isCapped()#普通集合轉定長集合
db.runCommand({convertToCapped:"stu1",size:100})3 文檔操作
3.1 插入文檔(insert|insertOne|insertMany)
#向stu集合插入一個文檔
db.stu.insert({item: "card",qty: 15})#向stu集合插入多個文檔
db.stu.insert([{item: "card",qty: 15},{item: "card1",qty: 16},{item: "card2",qty: 17}]
)#使用變量方式插入多個文檔
document=[{item: "card",qty: 15},{item: "card1",qty: 16},{item: "card2",qty: 17}]
db.stu.insert(document)#insertOne只能用來一次插入一個文檔
#insertMany可以用來一次插入多個文檔
#具體用法與insert的一樣3.2插入、刪除的循環操作
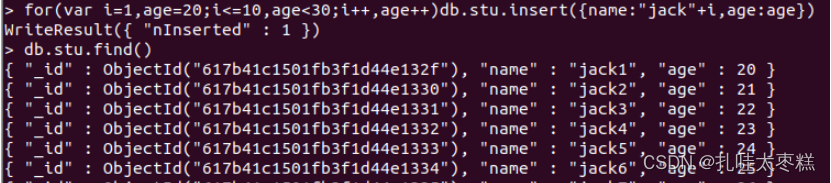
?💥循環插入10條數據
for(var i=1,age=20;i<=10;i++,age++)db.stu.insert({name:"jack"+i,age:age})
💥將一個集合的數據插入到另一個新建集合
db.stu1.find().forEach(function(x)){db.stu2.insert(x);}

💥循環修改集合中的文檔數據
for(var i=6;i<=10;i++)db.stu2.update({"name":["jack"+i,"tom"+i]},{$set:{"name":"tom"+i}})

3.2?刪除文檔(remove|deleteOne|deleteMany)
#刪除stu數據庫中滿足條件的所有文檔
db.stu.remove({條件})#刪除stu數據庫中滿足條件的一條文檔
db.stu.remove({條件},justOne:true)#刪除stu集合下的所有文檔
db.stu.deleteMany({})#刪除stu集合下的所有滿足條件的文檔
db.stu.deleteMany({條件})#刪除stu集合下的所有滿足條件的一條文檔
db.stu.deleteOne({條件})3.3?更新文檔(update|save)
db.集合名.update({條件},{$set:{字段名:修改后的值}})#將stu集合中item為card的文檔中qty值修改為35
db.stu.update({item: "card"},{$set: {qty: 35}}
)#save命令進行更新
db.stu.save({"_id": 10,item: "card",qty: 35})save與update命令的區別:
- save按_id進行匹配查找,修改的文檔若存在就進行修改,若不存在則創建該文檔并插入集合
- update按條件匹配查找,修改的文檔若存在就進行修改,若不存在則會拋異常
3.4?查詢文檔(find)
| 比較條件 | 符號 | 事例 |
| 等于 | : | db.stu.find({price:24}) |
| 大于 | $gt: | db.stu.find({price:{$gt:24}}) |
| 小于 | $lt: | db.stu.find({price:{$lt:24}}) |
| 大于等于 | $gte: | db.stu.find({price:{$gte:24}}) |
| 小于等于 | $lte: | db.stu.find({price:{$lte:24}}) |
| 不等于(數值) | $ne: | db.stu.find({price:{$ne:24}}) |
| 不等于(字符串) | $not: | db.stu.find({name:{$not:"《MongoDB 教程》"}}) |
| 與 | { , ,} | db.stu.find({price:{$gt:24}},{name:"《MongoDB教程》"}) |
| 或 | $or[{ , ,}] | db.stu.find({$or:[{price:{$gt:24}},{name:"《MongoDB教程》"}]}) |
| 包含 | $in: | db.stu.find({price:{$in:[23,24,25]}}) |
| 不包含 | $nin: | db.stu.find({price:{$nin:[23,24,25]}}) |
| 包含元素個數 | $size: | tags屬性中值為數組且包含三個元素的 db.stu.find(tags:{$size:3}}) |
配合find使用的其它方法
#age:null不僅會匹配到age的值為null的文檔,還會匹配到不包含age這個鍵的文檔。
db.stu.find({age:null})#限制返回值
db.stu.find().limit(3)#指定跳過第幾個文檔
db.stu.find().skip(3) //跳過第三個#查詢結果排序
查詢結果按照指定屬性升序顯示(-1降序)
db.stu.find().sort({"屬性":1})4 游標
????????db.stu.find()返回的就是一個游標,可以聲明一個變量進行接收,它是數據遍歷過程中的內部指針,是數據讀取的接口。
????????游標使用find方法返回,故上面說到配合find方法使用的sort、limit、skip等方法也可以使用,此外還有hint方法(強制使用索引進行查詢)。
#聲明游標并進行遍歷
var cursor = db.stu.find() //聲明游標
while (cursor.hasNext()){ //判斷游標的下一位有沒有值var doc = cursor.next(); //有值的情況下在聲明變量進行接收print(doc.name); //print(doc); //輸出的是一條BSON類型的數據printjson(doc); //轉成JSON的形式輸出print(tojson(doc)); //同上一行效果
}5 索引
? ? ? ? 什么叫索引呢?在沒有索引的情況下,用戶要是想要查詢某個文檔的話就必須掃描集合中的所有文檔,來選擇與查詢條件相匹配的文檔。然而,在有索引存在的情況下,用戶可以先查詢索引中是否有想要查詢的文檔,如果有的情況下就可以直接讀,從而節約了大量的時間。
? ? ? ? 索引的優點:提升文檔的查詢速率。相對而言,因為插入新的文檔會引起索引順序的重拍,從而會降低插入、更新的速率。
? ? ? ? MongoDB的索引基于B-tree數據結構,MySQL的索引基于B+tree數據結構。
#單索引
對stu集合中的score字段創建升序索引(-1降序)
索引名為:index1(索引名默認為字段名_1)
db.stu.createIndex({score:1},name:"index1")#復合索引
對stu集合中的score字段創建升序索引,state降序索引
db.stu.createIndex({score:1,state:-1})#唯一索引
對stu集合中的score字段創建升序唯一索引
db.stu.createIndex({score:1},{unique:true})#查詢stu集合的所有索引
db.stu.getIndexes()#查詢索引所占空間大小
db.stu.totalIndexSize()#刪除索引
索引的所有屬性都不能有所不同,否則會刪錯索引,或提示無此索引
db.stu.dropIndex({score:1})
刪除除_id索引外的所有索引
db.stu.dropIndexes()#修改索引
先刪除需要修改的索引,在創建一個修改后的索引6 聚合
對返回的文檔進行統計分析,使用aggregate方法實現。
💥管道操作:$match(過濾)?$group(分組) $project(顯示字段) $sort(排序) $limit(限制) $skip(跳過)
💥聚合運算符: $sum(求和) $avg(均值) $min(最小值) $max(最大值) $first?$last $push
#只顯示stu集合里文檔的quantity和pnumber字段
db.stu.aggregate({$project:{quantity:1,pnumber:1,price:0}})#過濾出stu集合里price大于4.0的所有文檔
db.stu.aggregate({$match:{price:{$gt:4.0}}})#對price字段升序排列
db.stu.aggregate({$sort:{price:1}})#返回stu集合的前三個文檔并跳過第一項
db.stu.aggregate({$limit:3},{$skip:1})分組求和的兩種方式
#管道聚合
按編號分組,并統計商品數量
db.stu.aggregate([{$group:{_id:"$pnumber",total:{$sum:"$quantity"}}}])#MapReduce
var mapFunc = function(){
emit(this.pnumber,this.quantity);
};var reduceFunc = function(key,values){
return Arrary.sum(values);
};db.stu.mapReduce(mapFunc,reduceFunc,{out:{replace:'result'}}) //創建一個集合用來接收結果)

)
)
時間單位(ms μs ns ps)長度單位(dm cm mm μm nm pm fm am zm ym))








)


,計算字符串或者是文本之間的相似度【附代碼】)
學在Java語法之前)
 注釋 數據類型 變量 常量 關鍵字 標識符 運算符 輸入輸出)
 控制流程 Math Date DateFormat Calendar System BigDecimal Random)