
《深入淺出Greenplum內核》系列直播以每月一場的速度持續推出中。在第一場《架構解讀》直播里,我們了解了Greenplum的整體架構、存儲管理、索引、查詢執行、事務與日志等內容。今天(5月22日),第二場《Greenplum內核揭秘之執行引擎》也順利播出啦!現在,我們來回顧一下直播演講內容吧!
看完別忘了前往askGP做一下小測試(ask.greenplum.cn/exam)鞏固一下所學的知識點哦!
執行器
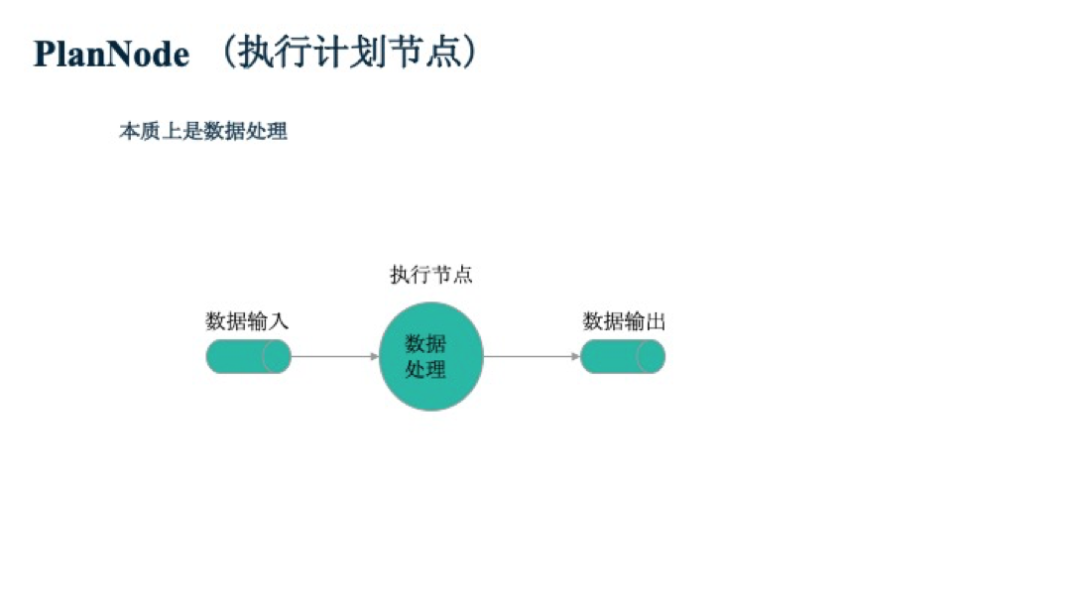
首先我們先來了解一下什么是執行器。簡單來講,執行器是處理一個由執行計劃節點組成的樹,并返回查詢結果。那么什么是執行計劃節點呢?從本質上講,一個執行計劃節點,實際上就是一個數據處理節點。從下圖可看到,在數據輸入后,執行節點會對數據進行數據處理,然后返回數據作為輸出。這些執行節點會被組織成樹的形式。
下圖是一個SELECT查詢的執行計劃樹。通過優化器優化后,就會生成這樣的樹狀結構,我們可以看到里面有四個執行節點,包括HashJoin節點,Hash節點,順序掃描節點,所有的節點通過樹的方式組織在一起,來表示各節點之間的數據流動或者順序關系。? 每一個計劃節點包含足夠多的元數據信息提供給執行器。
圖中的Seq Scan被稱為原發性的掃描節點,原發性的掃描節點是指,節點本身可以自己產生數據,而不依賴于其他節點;反之,非原發性掃描節點是需要子節點來為其提供數據,圖中的Hash Join和Hash就是非原發性掃描節點。了解了原發性掃描節點和非原發性掃描節點的不同,就可以更好的理解后面的執行模型。

執行模型
第一種是迭代模型,也被稱為流式模型,或者是抽拉式模型。它的定義非常簡單,每一個執行節點本質上就是一個next函數,我們會從一個樹節點的根節點一直往下執行這個next 函數。next 函數的實現會遵循這樣的特點:從輸出角度看,next 函數的每一次調用,執行節點返回一個tuple,沒有更多tuple的時候返回一個NULL。
從輸入的角度看,執行節點實現一個循環,每次調用子執行節點的next函數來獲取它們的輸出,并處理它們直到能返回一個tuple或者NULL。
執行控制流方向是自上往下,不斷抽拉的方式,由上層節點直接驅動下層節點來進行數據的驅動。而從數據流的角度來看,還是由上層節點往下層節點傳輸來完成。

向量化模型
第二種模型就是向量化模型,和迭代模型有一些相似之處,比如每一個執行節點實現一個next函數,但也有其不同之處。每一次迭代,執行節點返回一組tuple而非一個tuple,從而減少迭代次數,可以利用新的硬件特性如SIMD來加快一組tuple的處理。同時一組tuple在不同的節點之間傳輸,對列存也更加友好。執行節點實現一個循環,每次調用子執行節點的next函數來獲取它們的輸出,并能夠批量的處理數據。執行控制流方向自上而下,采用pull的方式。
Push執行模型
第三種模型是目前比較熱門的模型——PUSH執行模型。每一個執行節點定義兩個函數Produce函數
Consume函數
現在我們通過一個例子來看一下,下圖中有三個節點,一個掃描節點,一個投影節點,一個Join 節點。每個節點都生成了兩個函數,一個生產函數,一個消費函數。整個PUSH模型是怎么做的呢?圖中的紅框標注的為原發性的掃描節點,藍框標注的是非原發性的掃描節點。非原發性的掃描節點中的生產函數并不做真正的生產工作,而更多是承擔了控制工作,會調用它的子節點的生產函數。因此投影節點和Join節點會調用scan的生產函數。由于Scan是原發性的,因此會在生產并得到數據后,開始驅動數據的消耗。

PUSH模型是由下層的節點驅動上層的節點來完成的。數據流向也是自下而上的。下層驅動模型可以相對容易的轉換成由數據驅動的代碼。好處就是,上層的操作就會變成本節點的算子,增加代碼的局部性。此外,這樣的代碼可以更方便進一步轉換為一個純計算代碼,例如使用LLVM優化等。個人認為這種模型通用性不強,只能做一些局部的優化。
Greenplum使用的是迭代模型,但我們正在積極探索向量化模型和PUSH模型。Greenplum正在開發相應的功能,并提交到PG社區,基本思路是利用custom scan 的可定制特性,實現向量化版本的AGG節點,SORT節點,并替換原有查詢執行樹中的相應節點。大家對這一塊感興趣也歡迎去相應的郵件列表查看。

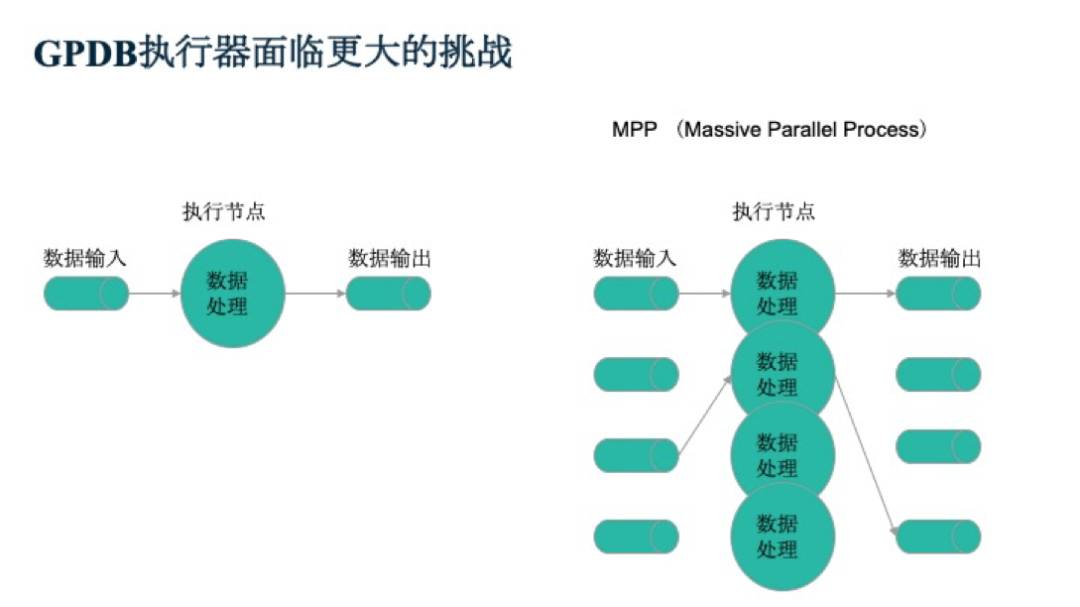
而Greenplum執行器面臨了更大的挑戰,首先Greenplum是MPP架構,意味著大規模的并行計算,每個執行節點就需要更多的處理過程。同一個執行節點就會變成多個處理過程,而數據也會被拆分。執行節點之間進行輸入和輸出的過程中,需要不同的計算單元進行交換。
Greenplum執行的挑戰和解決方案——Motion
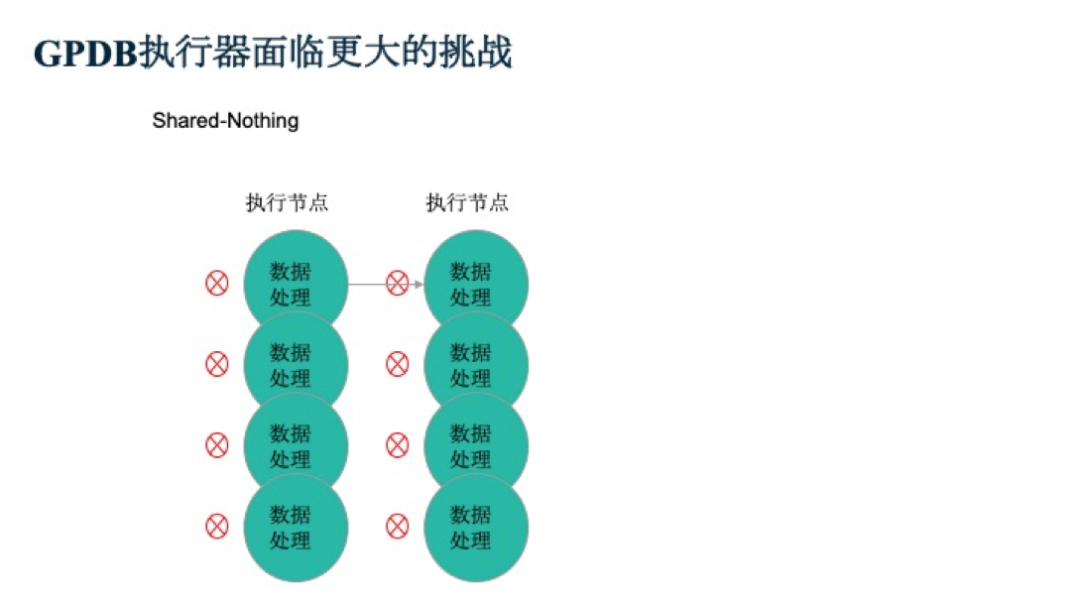
此外,Greenplum是一個Shared-Nothing的架構,這就意味著不同的計算單元之間的輸入輸出的過程會受阻。
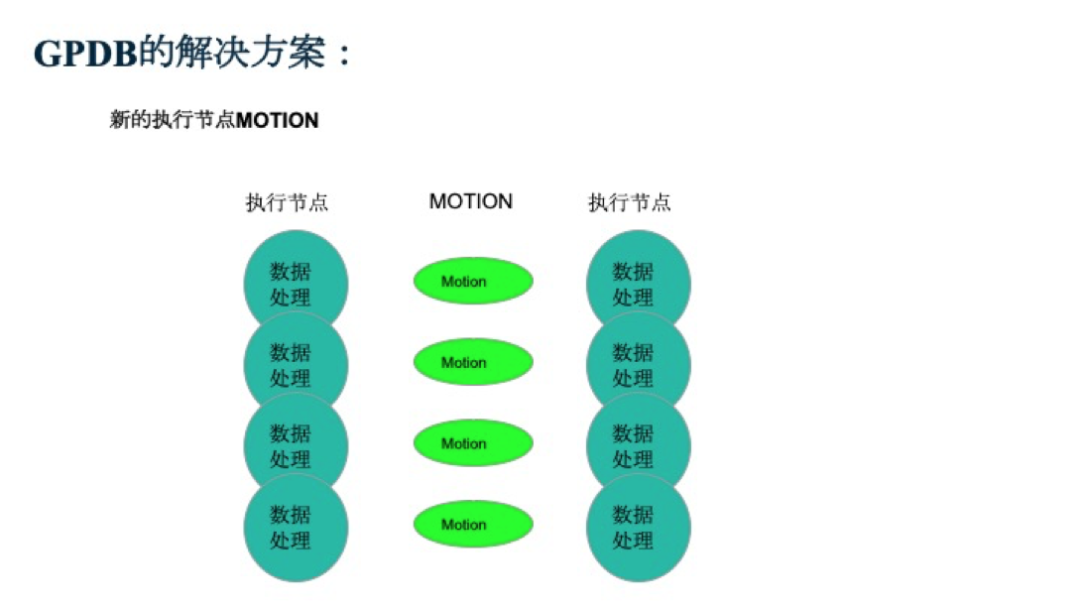
加了Motion后,執行計劃仍然是樹狀結構。只是在不同的節點之間加了個Motion節點,并最終通過Motion節點,將數據進行匯總。

接著我們來剖析一下并行化Plan。在下面的例子中,我們有一個Master和34個Segment節點。現在有兩張表:單身男和單身女,數據分布在不同的SEGMENT上。如果我們要進行一個查詢,將這兩張表格中,籍貫相同的單身男和單身女進行相親匹配,我們是如何生成一個可以被并行化執行的計劃樹呢?
為了更好的說明這個問題,我們可以在現實生活中進行映射,來方便大家理解。如果在現實生活中,我們會怎么辦?如果這些不同戶籍的單身男女在同一個省,此時處理方法就相對簡單,
首先把單身女找出來
再把單身男找出來
再把同戶籍的男生女生分配到相同的會場
從而較為快速的把這些單身男女進行匹配和篩選。
如果這些單身男女并不在同一個省,而是分布在全國34個省中,此時要如何處理呢?
為了做一個最優的策略,我們會分情況來看,
1. 如果單身男女都居住在戶籍所在地
可以由各省獨自舉辦相親會
針對本省的單身男女組織相親
將結果返回總部
對應到Greenplum上,是這樣的
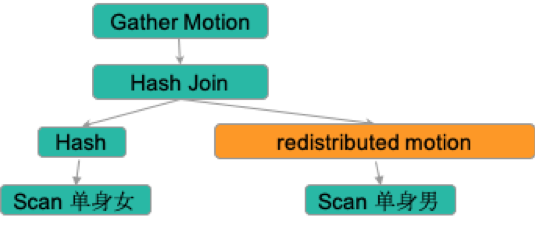
2. 對于單身女居住在戶籍所在地,而單身男生分散在全國各地。此時采取的策略可以是,
- 各省的分部獨自舉辦相親會:
- 將每個省的單身男青年找出來,并將他們通過火車派送回原戶籍所在地。
- 由每個省接待這些男青年,并在本省找出女單身青年,對他們進行相親配對。
如果女生數量很少,此時可以采用的策略是
找到本省所有適齡單身女青年,并為其買好34個省份的車票,每個省份都去一趟。
每個省接待這些單身女青年,并安排其與生活在本省的男青年相親,找出戶籍一致的配對。
對應到Greenplum上,是這樣的
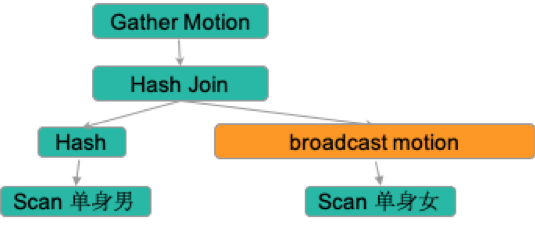
各分部舉辦相親會:
各省找出居住在本省的適齡單身男,并按戶籍派送到相應的省。
各省找出居住在本省的適齡單身女,并按戶籍派送到相應的省。
各省接待全國歸來的男女,進行相親配對。
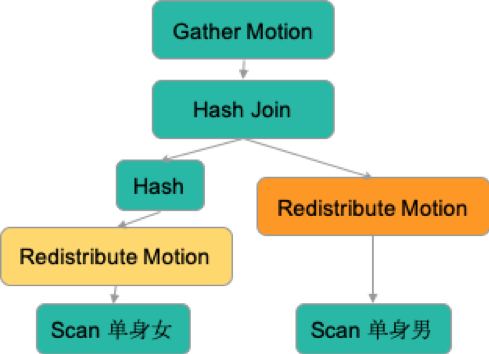
在進行相親策劃后,我們得出了以下經驗總結:
人多力量大的原則,盡量利有各省的分部
要首先分析當前男女青年的地域分布
必要時使用交通工具來打破地域的限制
其實在Greenplum里,也采用了類似的處理方式。每一張表都會有數據分布信息,Greenplum支持三種分布策略:鍵值分布(按列分布)、隨機分布、復制分布(數據在所有的segment上都保留了一份數據)。
Greenplum內部采用更通用的Locus信息來表示分布信息,所有的數據集合都會有數據分布狀態的。

Greenplum通過Motion來打破物理上的隔離。包括下圖中的四種Motion。Redistribute Motion是通過鍵值把Tuple在多個節點間進行重分布。Gather/Gather Merge Motion是把不同Segment上的數據聚集到一個節點上,Gather Merge保證了一個有序的收集過程。Broadcase Motion顧名思義就是廣播,每個節點都發送一份。Explict Redistribute Motion常用于Update/Delete操作,該類操作需要在數據原來所在的節點上進行更新或刪除,保證數據分布不會出現不一致。gp segment id隱藏列保存了數據所在原來節點信息。
并行化Plan


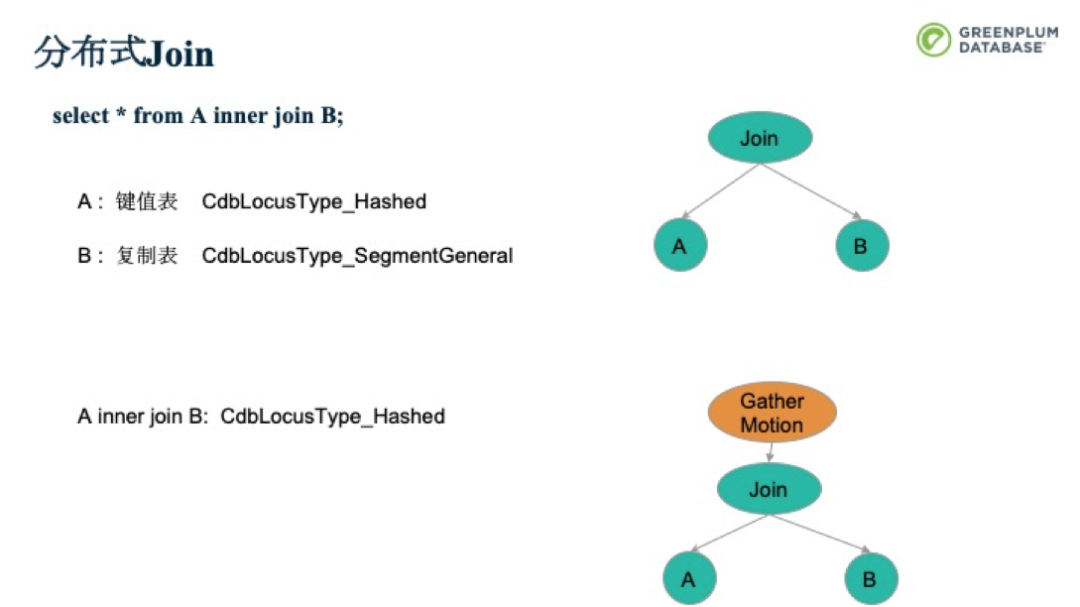
現在我們通過一個分布式Join的例子來鞏固一下。下面是一個簡單的inner join。A、B都是按照Hash分布的鍵值表。也就是數據被分散在各個Segment上,而每個Segment上只有部分數據。要做到A inner join B的完整數據集,就需要把B表全部復制到所有的segment上,和A的部分數據Join。得到的Plan就如下圖所示。前面我們提到,在Join完成后,也會有個數據分布。本例中,在Join完成后,還是會通過Hash分布。接著,由于QD會直接和Client進行交互,因此需要把所有的數據Gather到QD上,再由QD發送給Client。而其中的優化過程,會在本《深入淺出Greenplum內核》系列直播后續的課程中細講,請大家關注。
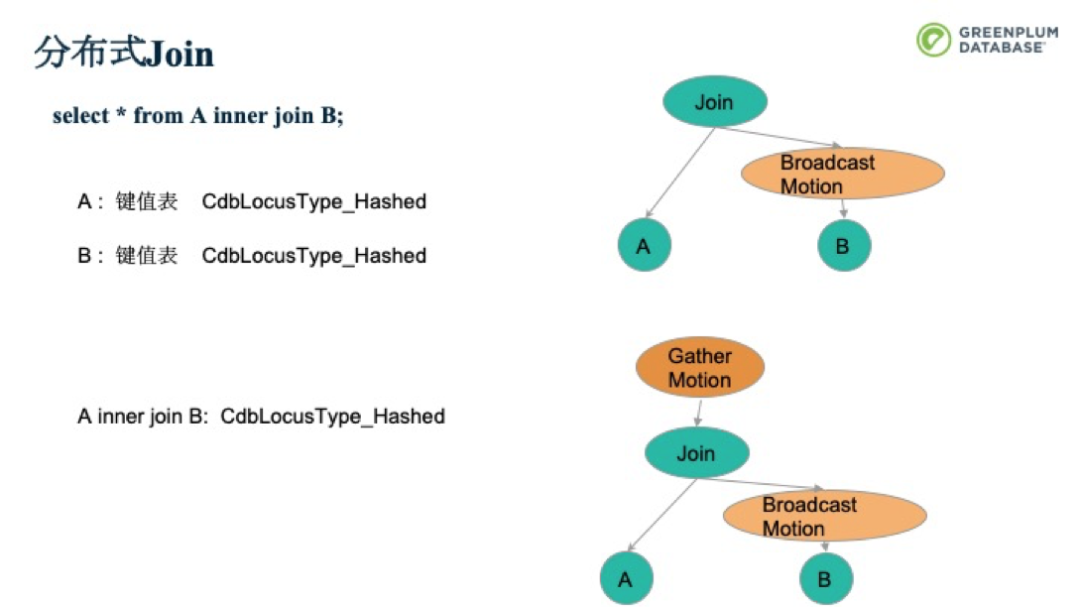
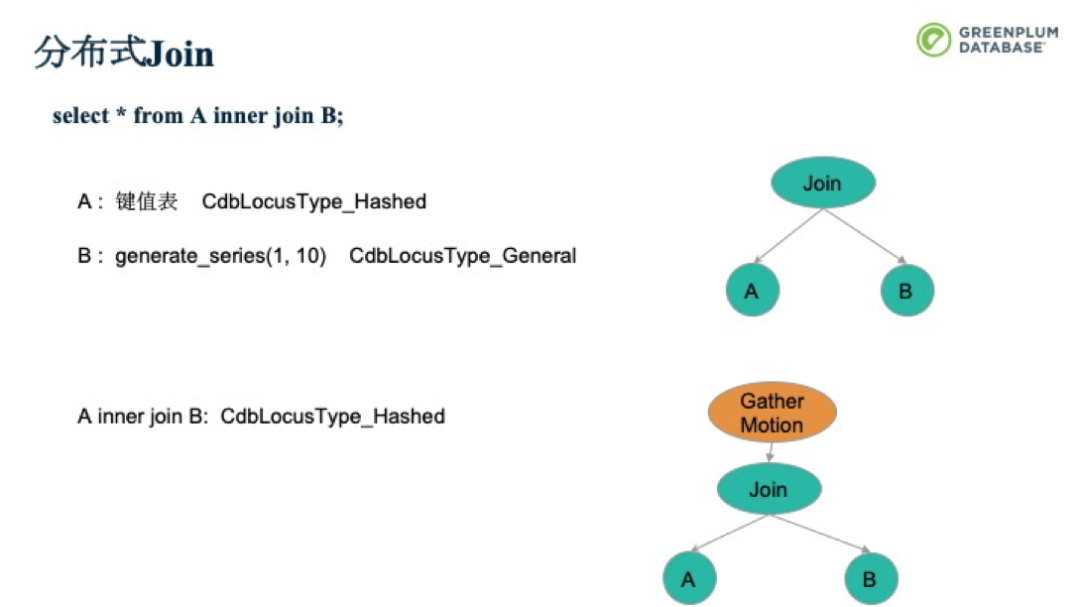
如果A是一個鍵值表,B是一個復制表。前面的Broadcast就不需要做了,可以直接進行Join。每個并行處理單元處理下圖中的計劃樹,再Gather到QD即可。
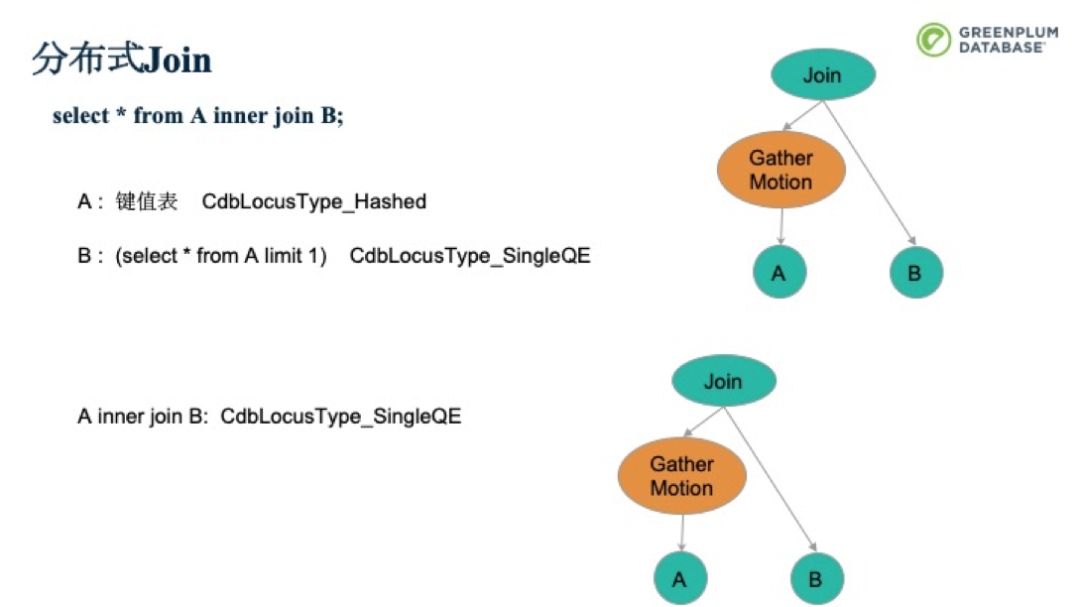
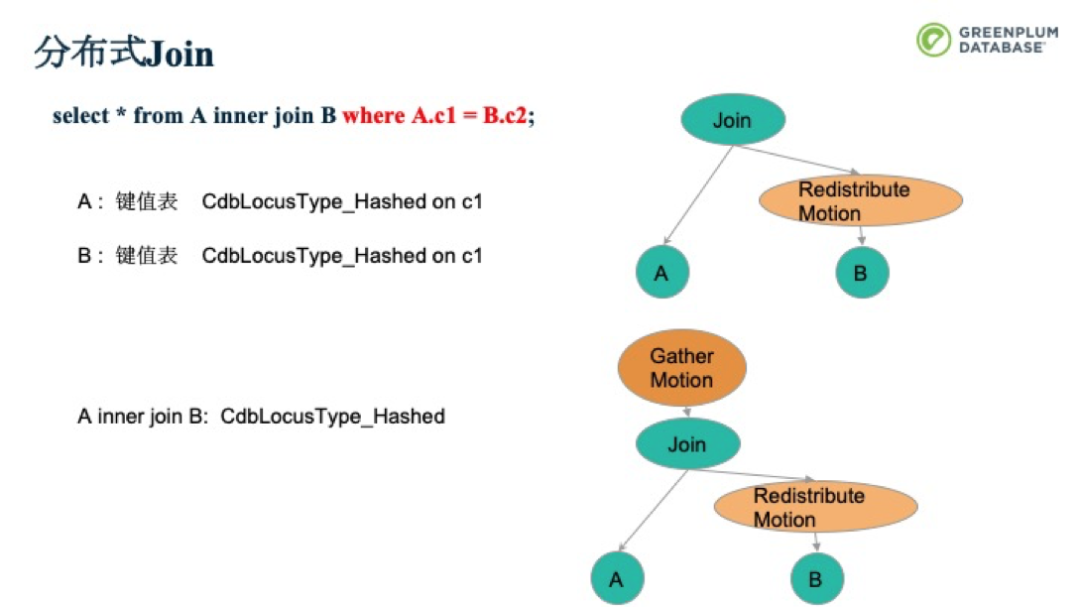
如果在Inner Join時加個條件,就可以將Broadcast Motion換成Redistribute Motion。讓c2這一列按照c1這個Hash重新分布到其他segment上,從而減少數據的移動。
我們再來看一個要AGG操作的例子,在下面的例子中,對A進行AGG操作,計算c1的count值。此時,我們只需要在每個Segment上做AGG,再Gather到QD即可。
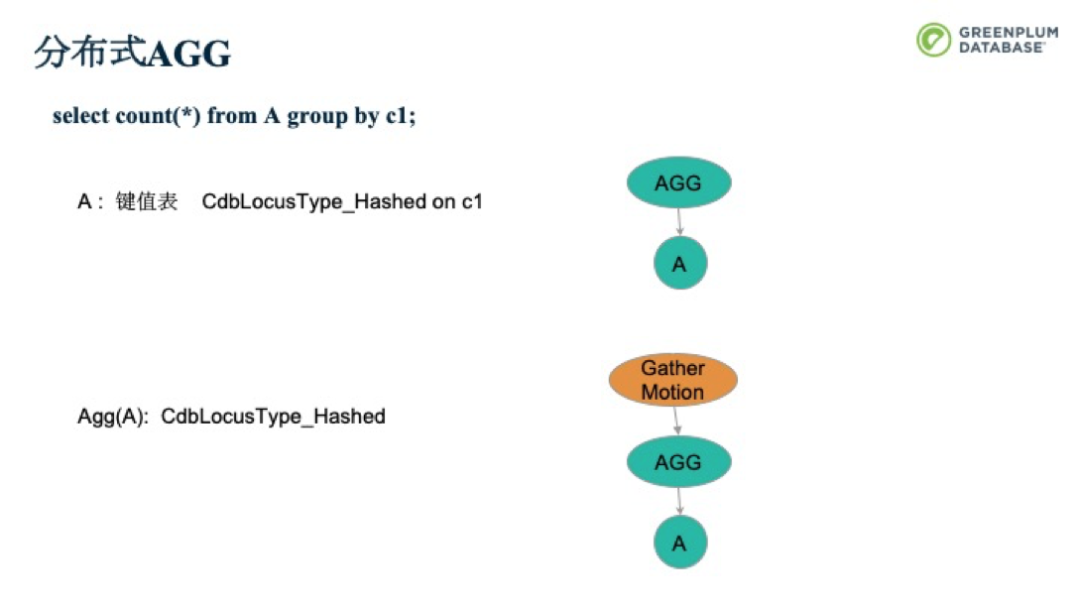
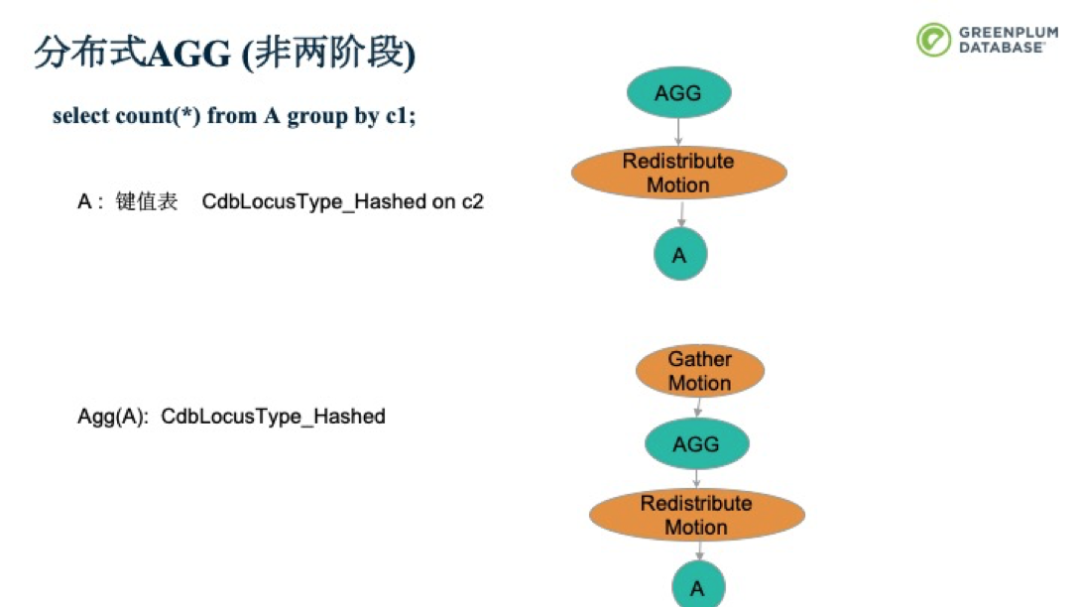
如果A表是按照C2做分布的(非兩階段),則前面的策略便不可用了。此時,我們可以將A可以按照C1做Redistrbute Motion,在前面提到的操作即可。
Dispatcher
講完分布式Plan的產生,我們再來看一下Greenplum中為了支持分布式plan而設計的模塊。第一個就是Dispatcher。上面提到的相親的策略,各省的分部獨自舉辦相親會。
首先每個省的單身男青年找出來,并將他們通過火車派送回原戶籍所在地。
然后每個省接待這些男青年,并在本省找出女單身青年,對他們進行相親配對。

對應到Greenplum上,有了分布式plan,一堆計算資源是如何分配調度和執行起來的呢?
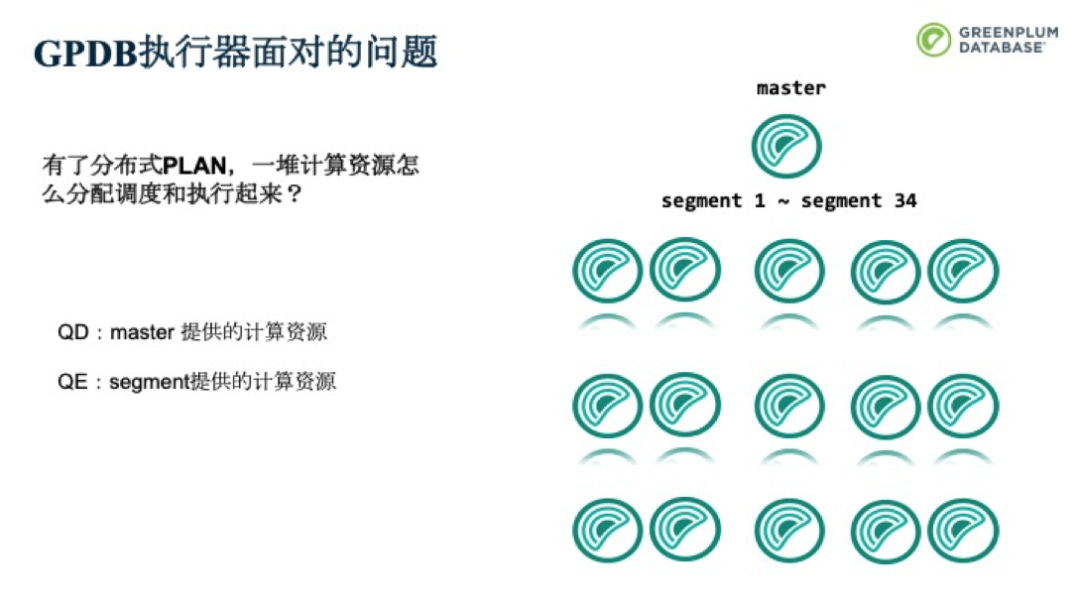
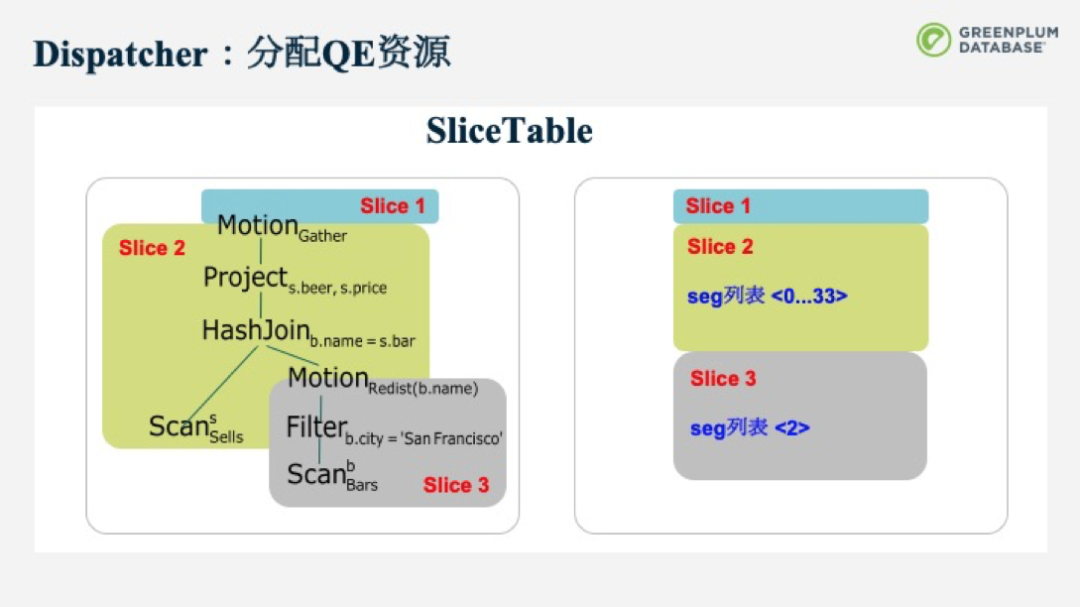
Dispatcher從SliceTable中得到信息后,會去分配資源。它會向CdbComponentDatabases這個component來申請資源,并將得到的資源回寫到SliceTable中。原本,SliceTable中只包括了需要在哪幾個Segment上起QE資源的較模糊的指令,但在分配完后,每個SliceTable就會得到QE資源具體的節點信息,包括地址和端口等。
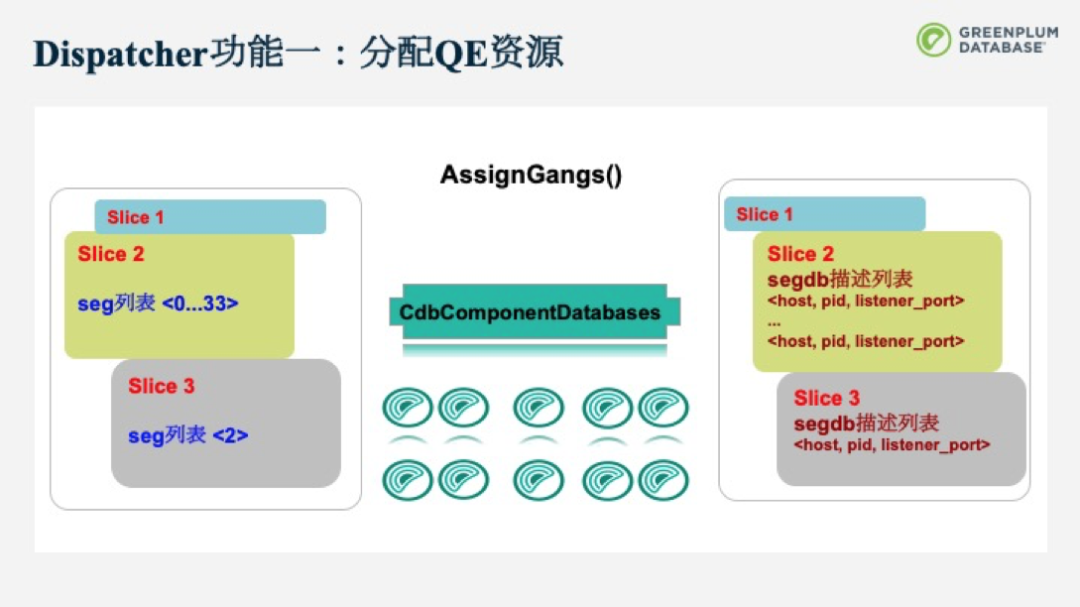
Dispatcher分配QE資源通過調用allocateGang()函數完成。GANG大小的分配非常靈活,最小可以只分配一個QE資源,而一般為segment的個數,甚至可以支持大于segment的個數的QE資源,即每個segment可以為一個gang分配多于一個的QE資源。此外QE資源閑置后,并不會被馬上回收,而是可以被后續的查詢重用,減少了重復分配QE帶來的開銷。

Dispatcher第二個功能是分發任務。CdbDispatchPlan可以分發并行性化plan的任務,SliceTable也會連同這個分布式plan一起發給QE。這樣的話所有的QE通過SliceTable可以找到自己預先被分配屬于哪個Gang,以及它的父節點的Gang是哪些以便于建立節點間通信。通過Parent Gang具體的QE描述符,我們就可以知道要把數據傳送到哪個端口。也可以分發純文本的、兩階段提交、查詢樹的任務。

Dispatcher的第三個功能就是協調功能,通過cdbdisp_checkDispatchResult函數來控制QE的狀態。有下面四種等待模式。

下圖就是一個典型的Dispatcher程序。Greenplum內的代碼基本都會遵循這樣的邏輯:分配上下文-分配資源-發送任務-等待發送的完成-等待QE的狀態-銷毀上下文。

Interconnect
第二個模塊就是Interconnect。Greenplum是通過網絡在QE之間移動數據,這個網絡模塊就是Interconnect。在Motion節點被初始化時,發送端和接收端就會建立Interconnect網絡連接。在Motion節點執行時,就會通過Interconnect來發送數據。
下圖是Interconnect的分層介紹。從應用層來說,主要任務是發送數據。Interconnect會對Tuple進行包裝,將其包裝成一個個Chunk。有些Tuple很大,就會進行切割,將其切成多個Chunk。Chunk通過數據包發送給receiver端。應用層還有一些數據流控制的包,包括EOS包,STOP包等。所有的包都會通過系統傳輸層中的UDPIFC和TCP IC進行傳輸。
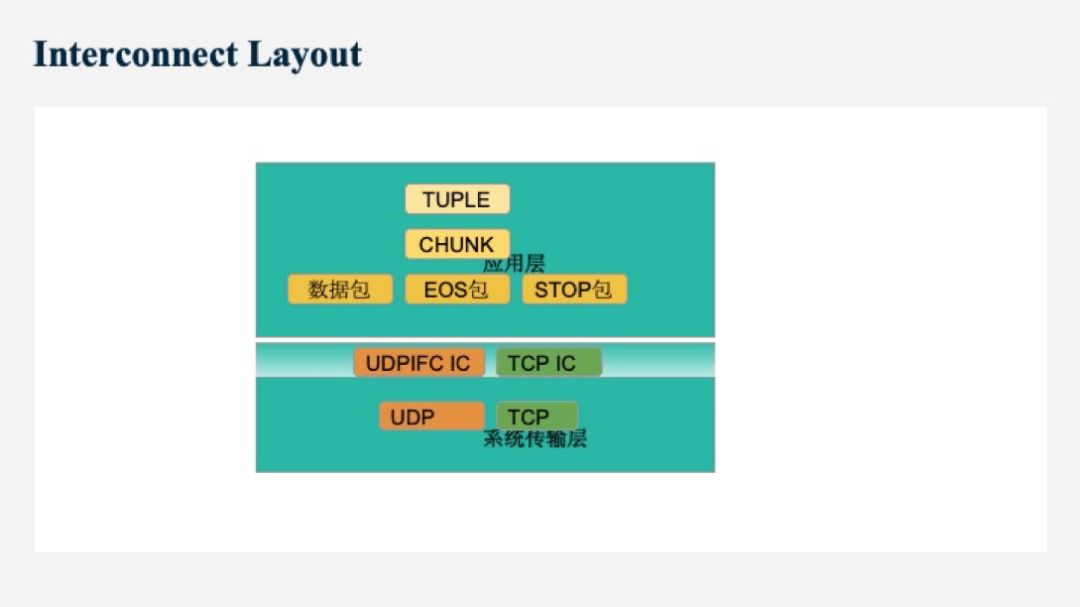
UDPIFC是Greenplum自己實現的一種RUDP(Reliable User Datagram Protocol)協議。基于UDP協議開發的,為了支持傳輸可靠性,實現了重傳,亂序處理,重傳處理,不匹配處理,流量控制等功能。GPDB當初引入UDPIFC主要為了解決復雜OLAP查詢在大集群中使用連接數過多的問題。UDPIFC實際上是一種線程模型。

后續,我們也可能會增加一些新的Interconnect類型,包括QUIC協議,Proxy協議等,歡迎大家的關注。

關于Hashjoin的內容,由于時間原因,本次分享就不做詳細的講解,如果大家對這一塊感興趣,可以反饋給我們社區,我們可以在后面添加專門的講解。大家可以參考一下之前Greenplum中文社區公眾號發布的關于Hashjoin的文章來了解相關內容。

Greenplum小測試第二期
(ask.greenplum.cn/exam)參加活動即可獲得“青梅稱號”,截圖分享至朋友圈還有機會獲得Greenplum變色杯!


我知道你
在看
哦
















)
)
)

