【本期分析師介紹】希音老師,《數據分析學堂》金牌分析師,對eviews的時間序列、ARMA、VAR、VECM、ARCH、GARCH等操作有深入的研究和實戰經驗,累計服務客戶1000+。今天邀請希音老師給大家分享eviews的詳細操作步驟。長文預警!可在文末聯系麻瓜學姐要PDF文檔,更方便閱讀,10G獨家干貨等你來拿!
AR-MA模型是一類常用的是隨機時序模型。由Box和Jenkins創立,亦稱B-J方法。它是一種精度較高的時序短期預測,其基本思想是,某些時間序列是依賴于時間t的一組隨機變量。構成該時序的單個序列制雖然具有不確定性。但整個序列的變化卻有一定的規律性。可以用相應的數學模型定制描述。通過對該數學模型的分析研究。能夠本質地認識時間序列的結構與特征,達到最小方差意義下的最優預測。本文章主要使用EVIews對構建ARMA模型,進行簡單認識,由于對于所有的平穩時間序列都可以轉化成MA形式。由于MA在可逆條件可以轉化成AR形式。所以我們對平穩時間序列可以使用ARMA形式構建模型,進行預測。
一、?平穩性檢驗(單位根檢驗)Eviews有多重檢驗平穩性的單位根檢驗,本文采用ADF進行采用檢驗,采用某國1960-1993年的GNP平減指數的季度數據,共136個觀測值,首先對變量進行變換,得到其通貨膨脹率,在EVIEWS的命令行中輸入:
genr pi=d(log(p))
其中p指的是GNP指數,pi指的是通貨膨脹率,genr是generate的縮寫,為生成一個新變量,也可以使用series進行生成新變量,log(p)是自然對數函數,進行d(*),是指對變量*進行一階差分。
生成變量以后,選中變量pi,雙擊打開,點擊右上角的View,然后點擊Unit root test那一項,進入頁面圖如下:
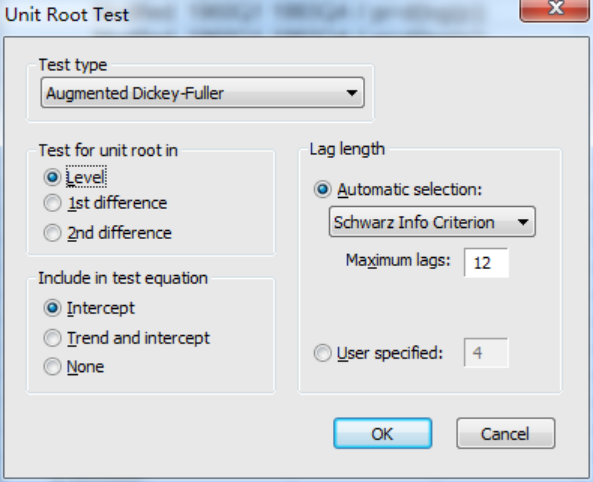
其中test type為檢驗單位根的類型,我們選中ADF檢驗(默認狀態),在include in test equation這一項中為ADF檢驗的三種形式,lag length為滯后階數,一般采用系統默認,在test for unit root in是對原數據進行單位根檢驗(level),還是對一階差分進行單位根檢驗(1st difference),還是二階差分進行單位姑娘檢驗(2st difference),本文先對原數據進行差分。
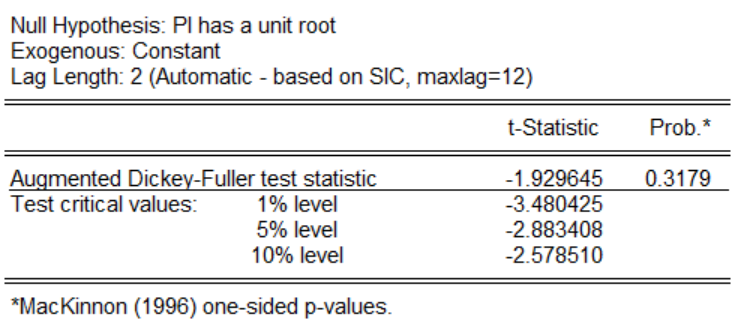
關于三種形式,可以使用以下方法,分別對三種形式進行一一檢驗,只要有一個拒絕存在單位根的原假設,那就說明時間序列是平穩的。點擊ok以后,發現三種形式下p值大于0.1,不能拒絕原假設,因此原時間序列不平穩,下圖為帶有截距項的示例圖:
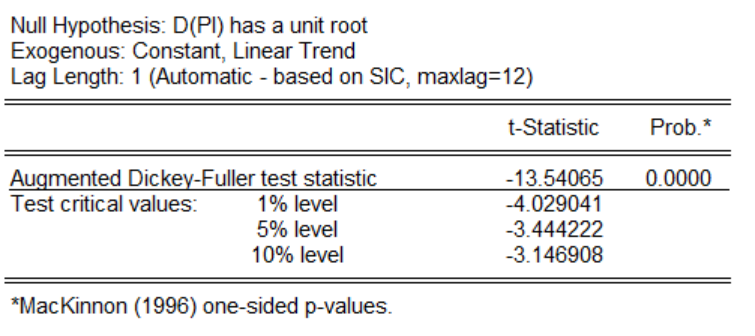
然后再對一階差分下。進行單位根檢驗,檢驗結果發現,三種形式下的p值為0.0000因此拒絕存在單位根的原假設,所以一階差分以后的時間序列是平穩的,可以對其進行構建ARMA模型。下圖為帶有時間趨勢項和截距項的結果展示圖:
二、?確定ARMA中的最大滯后階數p和q采用畫樣本相關系數圖和偏自相關系數圖來確定,在雙擊打開pi后,點擊view,然后在點擊correlogram,進行畫相關圖的頁面:
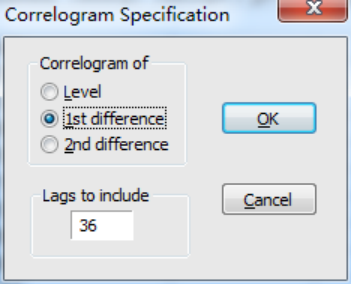
由于我們已經確定原數據是不平穩的額,一階差分以后數據時平穩的,因此在這里使用第二個選項,對其一階差分以后的時間序列進行研究,點擊ok以后,出現如下相關圖:
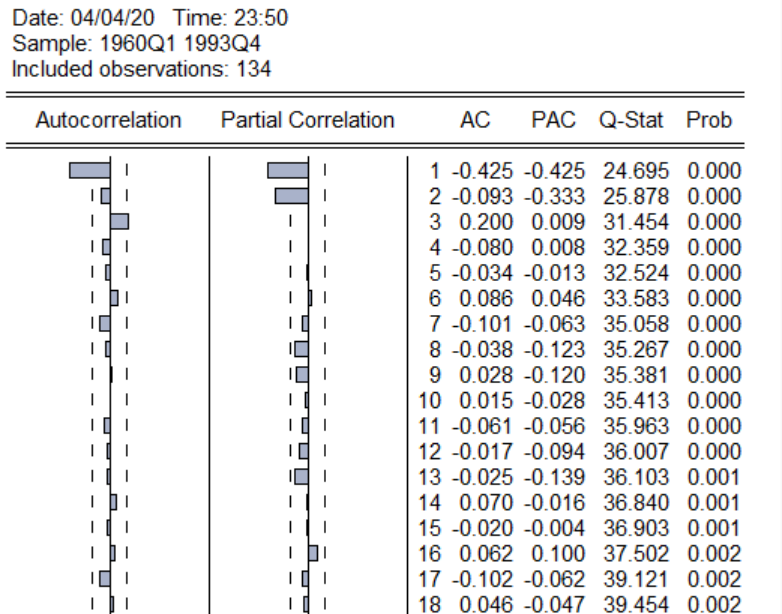
左邊的為AC圖(自相關圖),PAC為右邊圖(偏自相關),確定最大滯后階數的法則為圖中的AC和PAC下方的小長方形的連續多少個超過兩條虛線(兩虛線被稱為隨機區間),圖中PAC下方可以明顯看出連續兩個超出隨機區間,因此可以采用Pmax為2,而AC下方的連續一個超出隨機區間,因此可以采用qma為1。
三、?使用信息準則最小化原理確定最佳ARMA模型P的最大值為2,q的最大值為1,因此可以有以下4種組合ARMA(1,0),ARMA(1,1),ARMA(2,0),ARMA(2,1),通過信息準則篩選出最優模型,以下在EVIEWS命令行中輸入:Ls d(pi)ar(1)Ls?d(pi)?ar(1)?ma(1)Ls d(pi)ar(1)ar(2)Ls?d(pi)ar(1)ar(2)ma(1)以上是四種模型的回歸操作,這里對四種回歸結果進行展示,根據信息準則(在圖中為AIC,SC,HQ等),通過比較哪一個模型的這三個指標最小,就選哪一個模型,如果三個指標有大有小,采用投票原則,那個模型中三個指標最小的個數多就選那個。
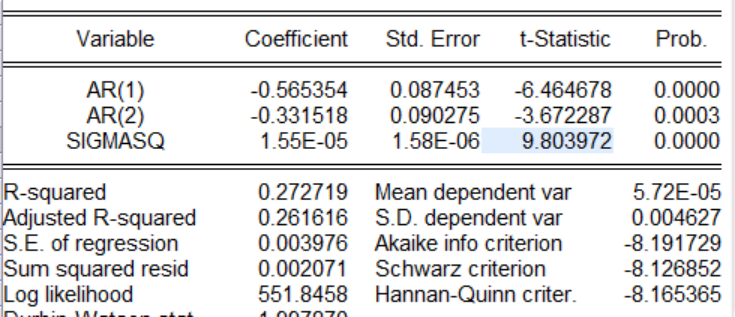
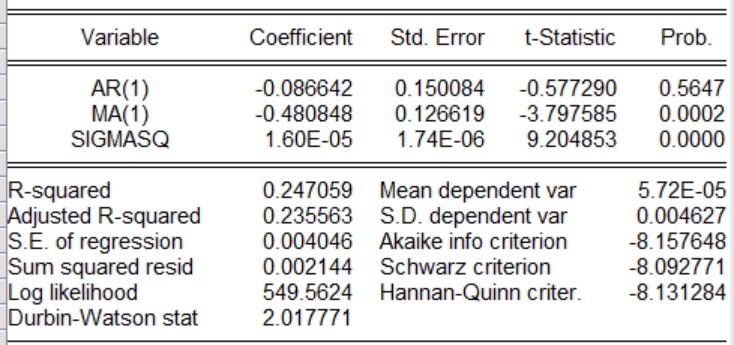
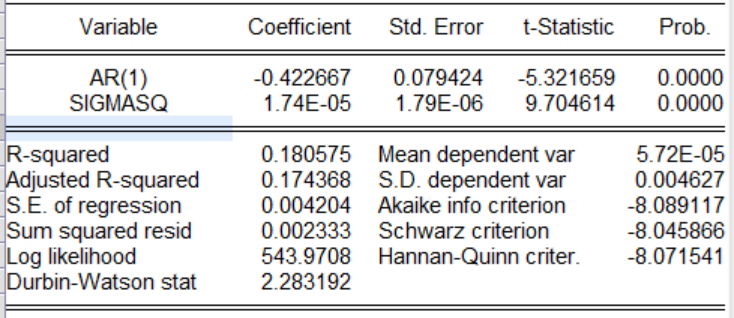
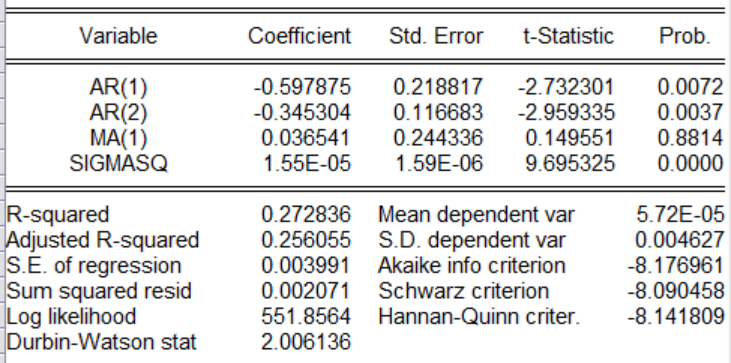
有圖可以知道ARMA(2,1)模型中AIC,SC,HQ是最小的個數是最多的。因此采用ARMA(2,1)模型。
四、?白噪聲檢驗在構建這個模型時,我們假設模型的誤差的序列無關的,因此我們有必要在構建模型以后進行誤差的序列相關性檢驗,以此來說明模型構建的良好,如果序列之間不存在序列相關性,我們就稱之為白噪聲,就是認為該序列已經沒有任何可以提取的信息了。對于白噪聲的檢驗,可以采用Q統計量的方法,具體操作如下圖:
在回歸以后的表中,點擊右上角的view,然后選中Residual diagnostics,在選第一個帶有Q的,點擊以后,選滯后階數,你可以自定義也可以默認,采用默認方式以后,得到下圖:
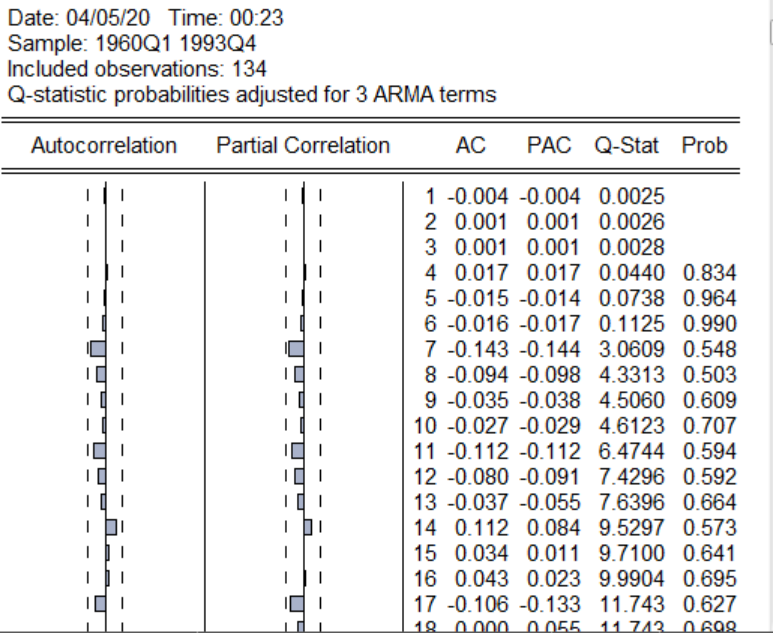
Q-star為Q統計量的值,prob為Q統計量的相伴概率,由于我們的樣本數為136,最大滯后階數m可以取[136/10]或者[],采用m為13,在表中尋找13行所對應的Q統計量和p值,分別為7.6396,0.664,。這個p值告訴我們在10%的顯著性水平之下,我們不能拒絕序列不存在相關性的原假設,因此可以認為最后的檢驗是序列是不存在相關性的,白噪聲檢驗通過,因此我們的模型時構建比較優良的。
五、?短期預測預測分為樣本內預測和樣本內預測,預測的形式又可以分為靜態預測和動態預測,其中樣本內預測就是根據某種預測方式對其樣本內的一段時間子區間進行預測,然后通過對比預測值和真實值之間的差距,這可以用一些指標(比如RMSE,MAPE)來衡量預測的好與壞,樣本外需要先擴展樣本區間,在進行樣本外預測。靜態預測每一期時需要用到上期的真實值,而動態預測用到的是其預測值或者說是擬合值,所以靜態預測,一般只能預測樣本為1期,而動態預測不受限制。下面對預測進行簡單展示:
1.首先調整樣本數,雙擊Range,然后對出現的頁面中1993改成1994,這樣我們就準備連續預測四期;
2.在回歸頁面表中,點擊forcast,然后出現以下頁面;
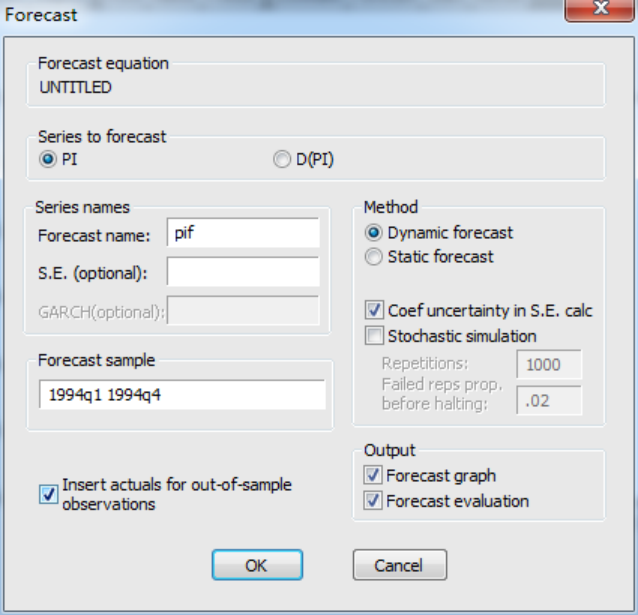
由于我們是通過對pi的一階差分呢進行建立ARMA模型的,但是由于我們預測的是pi,即前面所說的通貨膨脹率,因此選中pi,然后series names中forecast name為pif,這是系統默認的,如果你想預測某個序列,那么預測出來以后的序列名會在元序列多一個f,當然你也可以自定義。然后是forecast sample,預測樣本區間選為1994第一季度到1994年第二季度,我們選中動態預測,dynamic forecast,之后點擊ok。
3.然后點擊工作區中的pif序列,打開以后,尋找最后四期,結果如下圖所示:
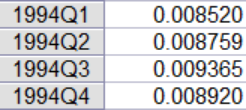
當然你也可以嘗試靜態預測,樣本內預測,其操作大體類似,本文就不再一一贅述。
往期推薦
SPSS經典案例 | 小白必看!方差分析、T檢驗、相關分析、因子分析,上財博士手把手教你套模板!
stata經典案例 | 初學者必看!面板數據、廣義矩估計、var模型、logit模型回歸詳細操作步驟
還在為畢業論文數據處理頭禿?!喏,秘籍給你,紅包也給你(文末有驚喜)

掃碼關注小數,每天一篇精選干貨!
[你長那么好看,文末點個在看再走唄】




)
——Linux管理類命令)
)

)
和多播地址有什么區別?)
-map元素查找)





_【從零學習OpenCV 4】輪廓面積與長度)


