盡管Hotspot 最新的垃圾回收器G1是在2006年推出的。但是G1從推行至今的市場反響來看,但現在足以證明這款垃圾收集器是經得起考驗的,從java9開始,就默認為G1垃圾收集器。G1是一款面向服務端應用的垃圾收集器。HotSpot開發團隊賦予它的使命是(在比較長期的)未來可以替換掉JDK1.5中發布的CMS收集器。與其他GC收集器相比,G1具備如下特點。
并行與并發、分代收集的垃圾收集算法、可預測的停頓、空間整合。
特點
從分代來看,G1依然屬于分代垃圾收集器,她會區分年輕代和老年代,依然有eden區和survivor區,但從堆的結構來看,它并不要求整個eden、年輕代或者老年代都連續,它使用了分區算法。
并行性: 在回收期間,可以由多個GC線程同時工作,有效利用多核計算能力。
井發性: GI 擁有與應用程序交替執行的能力,部分工作可以和應用程序同時執行,因此一 般來說,不會在整個回收期間完全阻塞應用程序。
分代 GC : Gl 依然是一個分代收集器,但是和之前回收器不同,它同時兼顧年輕代和老年代。對比其他回收器,它們或者工作在年輕代,或者工作在老年代。因此,這里是一個很大的不同。
空間整理: Gl 在回收過程中,會進行適當的對象移動,不像CMS,只是簡單地標記清理對象,在若干次 GC 后,CMS 必須進行一次碎片整理。而Gl不同,它每次回收都會有效地復制對象,減少空間碎片。
G1把內存“化整為零”的思路,理解起來似乎很容易,但其中的實現細節卻遠遠沒有想象中那樣簡單,否則也不會從2004年Sun實驗室發表第一篇G1的論文開始直到今天(將近10年時間)才開發出G1的商用版。
筆者以一個細節為例:把Java堆分為多個Region后,垃圾收集是否就真的能以Region為單位進行了?聽起來順理成章,再仔細想想就很容易發現問題所在:Region不可能是孤立的。一個對象分配在某個Region中,它并非只能被本Region中的其他對象引用,而是可以與整個Java堆任意的對象發生引用關系。那在做可達性判定確定對象是否存活的時候,豈不是還得掃描整個Java堆才能保證準確性?這個問題其實并非在G1中才有,只是在G1中更加突出而已。在以前的分代收集中,新生代的規模一般都比老年代要小許多,新生代的收集也比老年代要頻繁許多,那回收新生代中的對象時也面臨相同的問題,如果回收新生代時也不得不同時掃描老年代的話,那么Minor GC的效率可能下降不少。
?在G1收集器中,Region之間的對象引用以及其他收集器中的新生代與老年代之間的對象引用,虛擬機都是使用Remembered Set來避免全堆掃描的。G1中每個Region都有一個與之對應的Remembered Set,虛擬機發現程序在對Reference類型的數據進行寫操作時,會產生一個Write Barrier暫時中斷寫操作,檢查Reference引用的對象是否處于不同的Region之中(在分代的例子中就是檢查是否老年代中的對象引用了新生代中的對象),如果是,便通過CardTable把相關引用信息記錄到被引用對象所屬的Region的RememberedSet之中。當進行內存回收時,在GC根節點的枚舉范圍中加入Remembered Set即可保證不對全堆掃描也不會有遺漏。
G1的內存劃分和主要收集過程
G1收集器講堆進行分區,劃分為一個個區域,每次收集時,只收集其中幾個區域,以此來控制垃圾回收產生的一次停頓時間。
G1收集過程四個階段:
新生代GC(YGC)
并發標記周期
混合收集
如果需要進行full GC
G1的新生代GC
新生代GC的主要工作是回收eden區和survivor區。 一旦eden 區被占滿,新生代GC就會啟動。新生代GC收集前后的堆數據如圖5.6所示,其中E表示eden區,S表示survivor區, o表示老年代。可以看到,新生代GC只處理eden和survivor區,回收后,所有的eden區都應該被消空,而survivor區會被收集一 部分數據,但是應該至少仍然存在一 個 survivor 區,類比其他的新生代收集器,這一 點似乎并沒有太大變化。另一 個亟要的變化是老年代的區域增多,因為部分survivor區或者eden區的對象可能會晉升到老年代。


從日志中可以看到,eden區原本占用235MB空間,回收后被清空,survivor區從5MB增長到了11MB, 這是因為部分對象從eden區復制到survivor區,整個堆合計為400MB, 從回收前的239MB下降到10.5MB。
G1的井發標記周期
G1的并發階段與CMS有點類似,他們都是為了降低一次停頓時間,而將可以和應用程序并發的部分單獨提取出來執行。
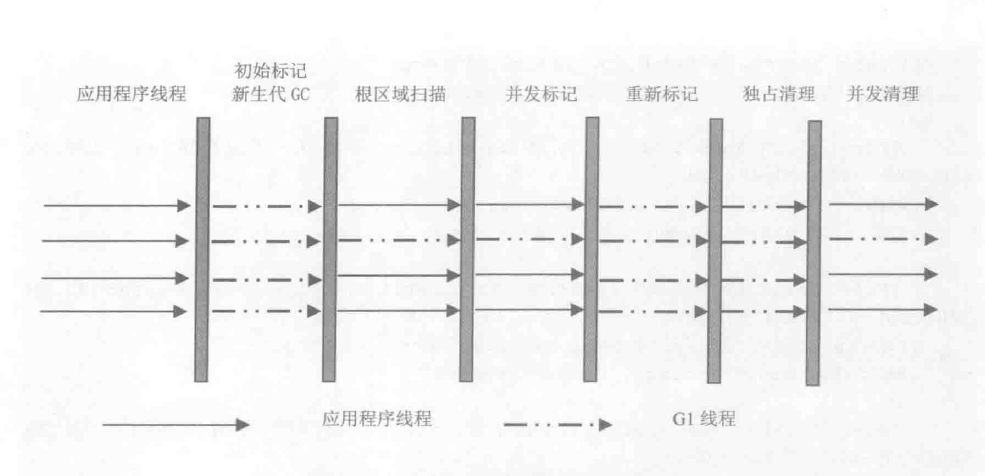
并發標記周期可以分為以下幾步。如果不計算維護RememberedSet的操作,G1收集器的運作大致可劃分為以下幾個步驟:
初始標記(Initial Marking)
根區域掃描
并發標記(Concurrent Marking)
最終標記(Final Marking)
獨占清理
篩選回收(Live Data Counting and Evacuation)
復制代碼
初始標記: 標記從根節點直接可達的對象。這個階段會伴隨一次新生代GC,它會產生全局停頓。
根區域掃描: 由于初始標記必然會伴隨一次新生代的GC,所以在初始化標記后,eden被清空,并且存活對象被移入survivor區。這個階段,將掃面survivor區直接可達的老年代對象,并標記這些直接可達的對象。根區域掃描不能和新生代GC同時執行。
并發標記: 和CMS類似,掃面查找整個對存活的對象,這是一個并發的過程,可以被一次新生代GC打斷。
重新標記: 由于并發標記過程中,應用仍在執行,因此標記結果需要修正,所以對上一次的標記結果進行補充,在G1中,這個過程使用STAB算法完成。即G1會在標記之初為存活對象創建一個快照,有助于加速重新標記速度。
獨占清理: 這個階段會引起停頓。
并發清理階段: 識別并清理完全空閑的區域。它是并發的清理,不會引起停頓。

在并發標記周期時,G1會產生如下日志:
(1)、初始標記,伴隨一次新生代GC
[GC pause (G1 Humongous Allocation) (young) (initial-mark), 0.0117414 secs]
...
[Eden: 1024.0K(4096.0K)->0.0B(2048.0K) Survivors: 2048.0K->1024.0K Heap: 9581.8K(20.0M)->12.3M(20.0M)]
[Times: user=0.11 sys=0.00, real=0.01 secs]
復制代碼
可以看到初始化標記時,eden被清空,并部分復制到survivor區
(2)、這是一次并發的根區域掃描,并發掃面過程中,不能被新生代GC打斷。
[GC concurrent-root-region-scan-start]
[GC concurrent-root-region-scan-end, 0.0007368 secs]
復制代碼
(3)、下面這個是指并發標記
[GC concurrent-mark-start]
[GC pause (G1 Evacuation Pause) (young) (to-space exhausted), 0.0427113 secs]
.....
[Eden: 2048.0K(2048.0K)->0.0B(1024.0K) Survivors: 1024.0K->1024.0K Heap: 16.4M(20.0M)->18.0M(20.0M)]
[Times: user=0.05 sys=0.02, real=0.04 secs]
...
[GC concurrent-mark-abort]
復制代碼
(4)、重新標記引起全局停頓
[Ref Proc: 0.3 ms]
復制代碼
(5)、重新標記后進行獨占清理
4.088: [GC cleanup 117M->106M(138M), 0.0015198 secs]
復制代碼
(6)、并發清理是并發執行的,會根據獨占清理階段計算出的每個區域的存活對象數量,直接回收已經不包含存活對象的區域。
4.090: [GC concurrent-cleanup-start]
并發清理階段開始,它釋放被發現為空的區域(不包含任何的活躍數據的區域),在上一個stop-the-world階段期間。
4.091: [GC concurrent-cleanup-end, 0.0002721]
并發清理階段清理空的區域用時0.0002721秒。
復制代碼
關于G1日志,想要知道所有內容的,可以看這篇文章,適合查詢:
blog.csdn.net/zhanggang80…
混合回收
在并發標記周期中,雖然有部分對象被回收,但是從整體上來說,回收的比例是相當低的。但是在并發標記周期后,G1已經明確知道哪些區域含有比較多的垃圾對象了,在混合階段,就是對這些區域進行回收的。當然,會優先回收垃圾比例比較高的區域。因為回收這些區域的性價比比較高。
G1是指垃圾優先的垃圾回收器,全稱"Garbage First Garbage Collector".
在混合回收中,即會執行正常年輕代GC,也會選取被標記的老年代區域進行回收,它同時處理了新生代和老年代。因為新生代GC的原因,eden區域必然被清空,此外,如下圖,有兩塊區域被標記為G的垃圾回收比例最高的區域被清理。被清理區域的存活對象會被移動到其他區域,這樣的好處是可以減少空間碎片。
混合GC產生如下日志:
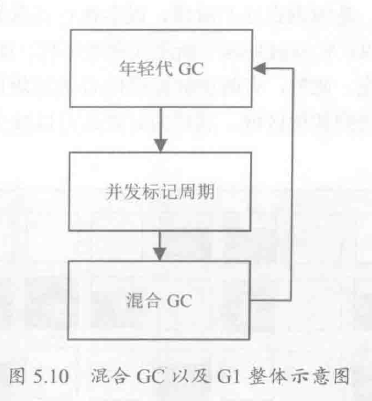
混合GC執行多次,直到回收了足夠多的內存空間,觸發一次新生代GC。新生代GC后,有可能會發生一次并發標記周期的清理,最后又引起混合GC。整個流程見下圖:
必要時的Full GC
與CMS類似,并發收集由于讓應用和GC線程交替工作,因此總是不能避免在特別的繁忙場合在回收過程導致內存不足,此時,G1也會執行一個Full GC回收。

此外,在混合GC和新生代GC時,survivor與老年代無法無法容納幸存對象,都會導致Full GC產生
完整的G1日志分析






G1 的相關參數
對于Gl收集器,可以使用-XX:+UseGIGC標記打開Gl收集器開關,對Gt收集器進行設置時,最重要的一 個參數就是-XX :MaxGCPauseMillis,它用于指定目標最大停頓時間。如果任何一次停頓超過這個設置值時,Gl就會嘗試調整新生代和老年代的比例、調整堆大小、調整晉升年齡等手段,試圖達到預設目標。對于性能調優來說,
有時候,總是魚和熊掌不可兼得的,如果停頓時間縮短,對千新生代來說,這意味著很可能要增加新生代GC的次數,GC反而會變得更加頻繁。對于老年代區域來說,為了獲得更短的停頓時間,那么在混合GC收集時,一次收集的區域數量也會變少,這樣無疑增加了進行FullGC的可能性。另外一個重要的參數是-XX :ParallelGCThreads, 它用于設置并行回收時,GC的工作線程數量。
此外,-XX:InitiatingHeapOccupancyPercent參數可以指定當整個堆使用率達到多少時,觸發并發標記周期的執行。默認值是45, 即當整個堆占用率達到45%時,執行并發標記周期。 InitiatingHeapOccupancyPercent 一 旦設置,始終都不會被G l收集器修改,這意味著G I收集器不會試圖改變這個值,來滿足MaxGCPause汕His的目標。如果InitiatingHeapOccupancyPercent值設置偏大,會導致并發周期遲遲得不到啟動,那么引起Full GC的可能性也大大增加,反之,一 個過小的 InitiatingHeapOccupancyPercent值,會使得并發周期非常頻繁,大整 GC 線程搶占CPU, 會導致應用程序的性能有所下降。
來自《深入理解JVM虛擬機》JVM高級特性與最佳實現。
《實戰java虛擬機》復制代碼

)
---xml、ini、excel、日志等配置)










)





