點擊上方“3D視覺工坊”,選擇“星標”
干貨第一時間送達

簡介
作者提出了一種基于RGB-D的深度學習方法6PACK,能夠實時的跟蹤已知類別物體。通過學習用少量的3D關鍵點來簡潔地表示一個物體,基于這些關鍵點,通過關鍵點匹配來估計物體在幀與幀之間的運動。這些關鍵點使用無監督端到端學習來實現有效的跟蹤。實驗表明該方法顯著優于現有方法,并支持機器人執行簡單的基于視覺的閉環操作任務。問題的提出
在機器人抓取任務中,實時跟蹤物體6D位姿的能力影響抓取任務的實施。現有的6D跟蹤方法大部分是基于物體的三維模型進行的,有較高的準確性和魯棒性。然而在現實環境中,很難獲得物體的三維模型,所以作者提出開發一種類別級模型,能夠跟蹤特定類別從未見過的物體。創新點
1、這種方法不需要已知物體的三維模型。相反,它通過新的anchor機制,類似于2D對象檢測中使用的proposals方法,來避免定義和估計絕對6D位姿。2、這些anchor為生成3D關鍵點提供了基礎。與以往需要手動標注關鍵點的方法不同,提出了一種無監督學習方法,該方法可以發現最優的3D關鍵點集進行跟蹤。3、這些關鍵點用于簡潔的表示物體,可以有效地估計相鄰兩幀之間位姿的差異。這種基于關鍵點的表示方法可以實現魯棒的實時6D姿態跟蹤。核心思想
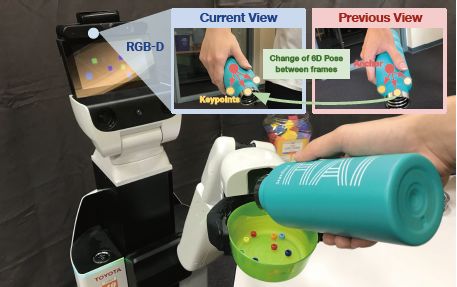
作者提出的模型使用RGB-D圖像,基于之前位姿周圍采樣的anchors(紅點),來魯棒地檢測和跟蹤一組基于3D類別的關鍵點(黃色)。然后利用連續兩幀中預測的關鍵點,通過最小二乘優化求解點集對齊的問題,計算出6D物體的位姿變化:
問題的定義
將類別級物體6D位姿跟蹤定義為:物體在連續時間t?1和t之間的位姿變化問題。初始位姿是針對相同類別的所有目標物體定義的標準框架相對于相機框架的平移和旋轉。例如,對于類別“相機”,將框架放置在物體的質心處,x軸指向相機物鏡的方向,y軸指向上方。將3D關鍵點定義為:在整個時間序列中幾何和語義上一致的點。給定兩個連續的輸入幀,需要從兩幀中預測匹配的關鍵點列表。基于剛體假設的基礎,利用最小二乘優化來解決點集對齊問題,從而得到位姿的變化?p。模型
首先在預測物體實例的周圍剪裁一個放大的體積,將其歸一化為一個單元;在體積塊上生成anchor網格;之后使用DenseFusion計算M個點的幾何與顏色融合特征;根據距離將它們平均池化成N個anchor特征;注意力機制網絡使用anchor特征來選擇最接近質心的點;用質心生成一組有序的關鍵點。將這種關鍵點生成方法應用在前一幀和當前幀,得到兩組有序的關鍵點來計算幀間的位姿變化。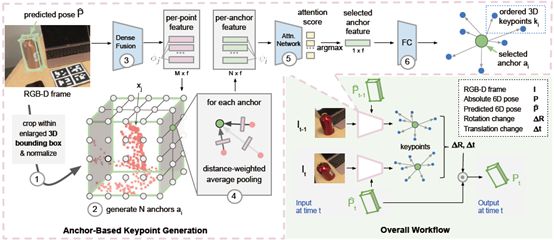 6-PACK算法在預測位姿周圍生成anchor網格的過程中使用了注意力機制。每個點用RGB-D點單獨特征的距離加權和來表示體積。使用anchor信息在新的RGB-D框架中找到物體的粗略質心,并指導對其周圍關鍵點的后續搜索,這比在無約束的三維空間中搜索關鍵點效率更高。?
6-PACK算法在預測位姿周圍生成anchor網格的過程中使用了注意力機制。每個點用RGB-D點單獨特征的距離加權和來表示體積。使用anchor信息在新的RGB-D框架中找到物體的粗略質心,并指導對其周圍關鍵點的后續搜索,這比在無約束的三維空間中搜索關鍵點效率更高。?實驗與結果
作者采用的數據集是NOCS-REAL275,包含六個類別。通過對比三個模型的baseline來評估作者的方法。NOCS:類別級物體6D位姿估計sota。ICP:Open3D中中實現的標準點對面ICP算法。KeypointNet:直接在三維空間中生成3D關鍵點。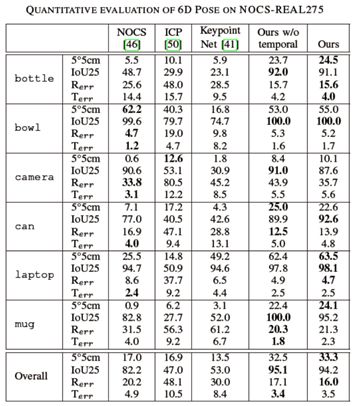 1)6-PACK指標5°/5cm比NOCS高出15%以上,指標IoU25高出12%。說明與使用所有輸入像素作為關鍵點的NOCS相比,6-PACK能夠檢測出最適合類別級6D跟蹤的3D關鍵點。實驗結果如下圖所示:
1)6-PACK指標5°/5cm比NOCS高出15%以上,指標IoU25高出12%。說明與使用所有輸入像素作為關鍵點的NOCS相比,6-PACK能夠檢測出最適合類別級6D跟蹤的3D關鍵點。實驗結果如下圖所示: 其中,前兩列為NOCS和6-PACK的定性對比,后兩列為關鍵點匹配的結果。2)6-PACK所有指標都優于KeypointNet,KeypointNet經常跟丟。作者的方法避免了丟失物體的軌跡(IoU25>94%),基于anchor的注意力機制提高了整體的跟蹤性能。3)為了檢驗不同方法的魯棒性和穩定性,作者計算了沒有前x幀的平均性能。這樣就能測量出初始位姿對性能的影響(接近初始位姿的幀很容易跟蹤)。如下圖,除了NOCS之外,所有方法的性能都有所下降,因為NOCS是位姿估計方法,而不是位姿跟蹤方法。在整個過程中,6-PACK的性能比NOCS高出10%以上,并在初始幀100后停止下降。
其中,前兩列為NOCS和6-PACK的定性對比,后兩列為關鍵點匹配的結果。2)6-PACK所有指標都優于KeypointNet,KeypointNet經常跟丟。作者的方法避免了丟失物體的軌跡(IoU25>94%),基于anchor的注意力機制提高了整體的跟蹤性能。3)為了檢驗不同方法的魯棒性和穩定性,作者計算了沒有前x幀的平均性能。這樣就能測量出初始位姿對性能的影響(接近初始位姿的幀很容易跟蹤)。如下圖,除了NOCS之外,所有方法的性能都有所下降,因為NOCS是位姿估計方法,而不是位姿跟蹤方法。在整個過程中,6-PACK的性能比NOCS高出10%以上,并在初始幀100后停止下降。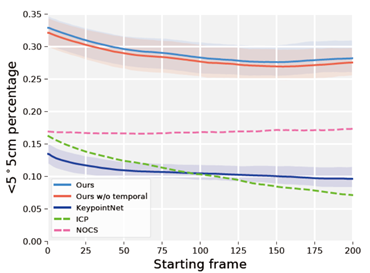 4)作者在機器人上進行了實時測試,超過60%的試驗中,成功地跟蹤了目標(目標在可視范圍內),而沒有丟失。
4)作者在機器人上進行了實時測試,超過60%的試驗中,成功地跟蹤了目標(目標在可視范圍內),而沒有丟失。論文地址:https://arxiv.org/abs/1910.10750v1
代碼鏈接:https://sites.google.com/view/6PACKtracking上述內容,如有侵犯版權,請聯系作者,會自行刪文。
推薦閱讀:
吐血整理|3D視覺系統化學習路線
那些精貴的3D視覺系統學習資源總結(附書籍、網址與視頻教程)
超全的3D視覺數據集匯總
大盤點|6D姿態估計算法匯總(上)
大盤點|6D姿態估計算法匯總(下)
機器人抓取匯總|涉及目標檢測、分割、姿態識別、抓取點檢測、路徑規劃
匯總|3D點云目標檢測算法
匯總|3D人臉重建算法那些年,我們一起刷過的計算機視覺比賽總結|深度學習實現缺陷檢測深度學習在3-D環境重建中的應用匯總|醫學圖像分析領域論文大盤點|OCR算法匯總
重磅!3DCVer-知識星球和學術交流群已成立
3D視覺從入門到精通知識星球:針對3D視覺領域的知識點匯總、入門進階學習路線、最新paper分享、疑問解答四個方面進行深耕,更有各類大廠的算法工程人員進行技術指導,550+的星球成員為創造更好的AI世界共同進步,知識星球入口:
學習3D視覺核心技術,掃描查看介紹,3天內無條件退款
?圈里有高質量教程資料、可答疑解惑、助你高效解決問題
歡迎加入我們公眾號讀者群一起和同行交流,目前有3D視覺、CV&深度學習、SLAM、三維重建、點云后處理、自動駕駛、CV入門、醫療影像、缺陷檢測、行人重識別、目標跟蹤、視覺產品落地、視覺競賽、車牌識別等微信群,請掃描下面微信號加群,備注:”研究方向+學校/公司+昵稱“,例如:”3D視覺?+ 上海交大 + 靜靜“。請按照格式備注,否則不予通過。添加成功后會根據研究方向邀請進去相關微信群。原創投稿也請聯系。
 ▲長按加群或投稿
▲長按加群或投稿



)



)



詳解)


: 使用go語言調用c語言的so動態庫-Go語言中文社區...)


![android 開機動畫 漸變,[Parallax Animation]實現知乎 Android 客戶端啟動頁視差滾動效果...](http://pic.xiahunao.cn/android 開機動畫 漸變,[Parallax Animation]實現知乎 Android 客戶端啟動頁視差滾動效果...)
