在了解了窗口函數實現原理 spark、hive中窗口函數實現原理復盤?和?sparksql比hivesql優化的點(窗口函數)之后,今天又擼了一遍hive sql 中窗口函數的源碼實現,寫個筆記記錄一下。
簡單來說,窗口查詢有兩個步驟:將記錄分割成多個分區;然后在各個分區上調用窗口函數。
傳統的 UDAF 函數只能為每個分區返回一條記錄,而我們需要的是不僅僅輸入數據是一張表,輸出數據也是一張表(table-in, table-out),因此 Hive 社區引入了分區表函數 Partitioned Table Function (PTF)。
1、代碼流轉圖
PTF 運行在分區之上、能夠處理分區中的記錄并輸出多行結果的函數。
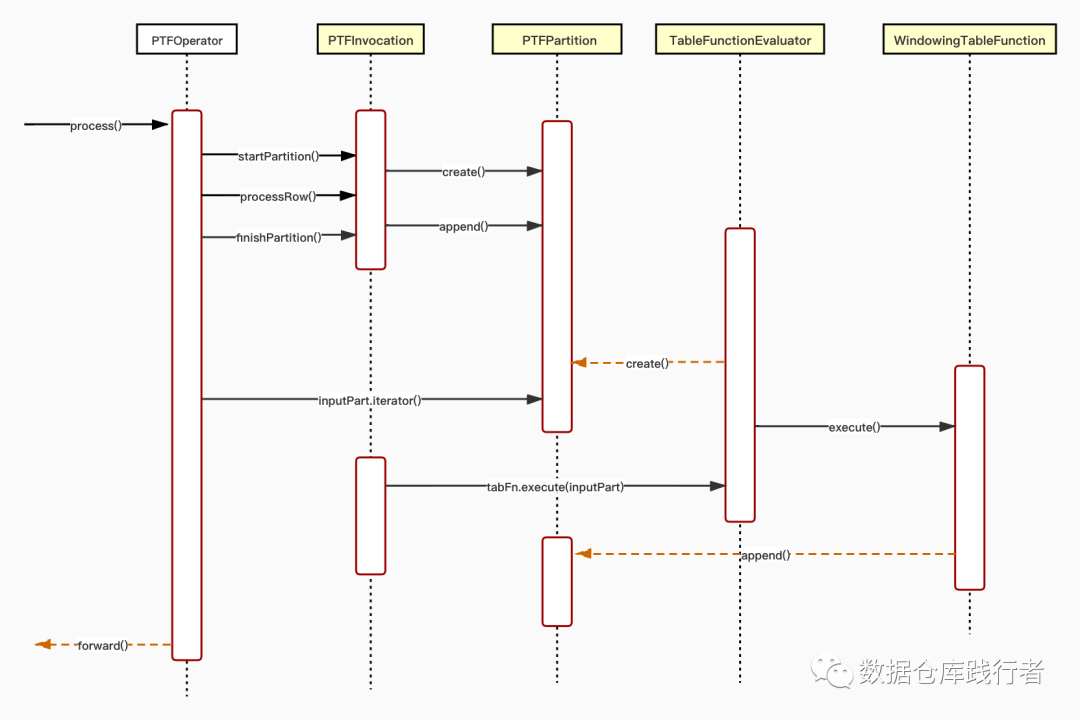
hive會把QueryBlock,翻譯為執行操作樹OperatorTree,其中每個operator都會有三個重要的方法:
initializeOp() ?--初始化算子
process() ? ?--執行每一行數據
forward() ? --把處理好的每一行數據發送到下個Operator
當遇到窗口函數時,會生成PTFOperator,PTFOperator 依賴PTFInvocation讀取已經排好序的數據,創建相應的輸入分區:PTFPartition inputPart;
WindowTableFunction 負責管理窗口幀、調用窗口函數(UDAF)、并將結果寫入輸出分區: PTFPartition outputPart。
2、其它細節
PTFOperator.process(Object row, int tag)-->PTFInvocation.processRow(row)
void processRow(Object row) throws HiveException { if ( isStreaming() ) { handleOutputRows(tabFn.processRow(row)); } else { inputPart.append(row); //主要操作就是把數據 append到 ptfpartition中,這里的partition與map-reduce中的分區不同,map-reduce分區是按照key的hash分,而這里是要把相同的key要放在同一個ptfpartition,方便后續的windowfunction操作 }}真正對數據的操作是當相同的key完全放入同一個ptfpartition之后,時機就是finishPartition:
void finishPartition() throws HiveException { if ( isStreaming() ) { handleOutputRows(tabFn.finishPartition()); } else { if ( tabFn.canIterateOutput() ) { outputPartRowsItr = inputPart == null ? null : tabFn.iterator(inputPart.iterator()); } else { outputPart = inputPart == null ? null : tabFn.execute(inputPart); //這里TableFunctionEvaluator outputPartRowsItr = outputPart == null ? null : outputPart.iterator(); } if ( next != null ) { if (!next.isStreaming() && !isOutputIterator() ) { next.inputPart = outputPart; } else { if ( outputPartRowsItr != null ) { while(outputPartRowsItr.hasNext() ) { next.processRow(outputPartRowsItr.next()); } } } } } if ( next != null ) { next.finishPartition(); } else { if (!isStreaming() ) { if ( outputPartRowsItr != null ) { while(outputPartRowsItr.hasNext() ) { forward(outputPartRowsItr.next(), outputObjInspector); } } } }}還有一個雷區,PTFPartition append():
public void append(Object o) throws HiveException { if ( elems.rowCount() == Integer.MAX_VALUE ) { //當一個ptfpartition加入的條數等于Integer.MAX_VALUE時會拋異常 throw new HiveException(String.format("Cannot add more than %d elements to a PTFPartition", Integer.MAX_VALUE)); } @SuppressWarnings("unchecked") List<Object> l = (List<Object>) ObjectInspectorUtils.copyToStandardObject(o, inputOI, ObjectInspectorCopyOption.WRITABLE); elems.addRow(l);}需要把相同key的數據完全放入一個ptfPartition進行操作,這時對加入的的條數做了限制,不能>=Integer.MAX_VALUE(21億),這塊需要注意。
我是小蘿卜算子 在成為最厲害最厲害最厲害的道路上 很高興認識你 ~~ enjoy ~~ |










![mysql join圖解_MySQL中Join算法實現原理分析[多圖]](http://pic.xiahunao.cn/mysql join圖解_MySQL中Join算法實現原理分析[多圖])






)

