構建深度學習模型的基本流程就是:搭建計算圖,求得損失函數,然后計算損失函數對模型參數的導數,再利用梯度下降法等方法來更新參數。
搭建計算圖的過程,稱為“正向傳播”,這個是需要我們自己動手的,因為我們需要設計我們模型的結構。由損失函數求導的過程,稱為“反向傳播”,求導是件辛苦事兒,所以自動求導基本上是各種深度學習框架的基本功能和最重要的功能之一,PyTorch也不例外。
我們今天來體驗一下PyTorch的自動求導吧,好為后面的搭建模型做準備。
一、設置Tensor的自動求導屬性
所有的tensor都有.requires_grad屬性,都可以設置成自動求導。具體方法就是在定義tensor的時候,讓這個屬性為True:
x = tensor.ones(2,4,requires_grad=True)
In [1]: import torchIn [2]: x = torch.ones(2,4,requires_grad=True)In [3]: print(x)tensor([[1., 1., 1., 1.], [1., 1., 1., 1.]], requires_grad=True)只要這樣設置了之后,后面由x經過運算得到的其他tensor,就都有equires_grad=True屬性了。
可以通過x.requires_grad來查看這個屬性。
In [4]: y = x + 2In [5]: print(y)tensor([[3., 3., 3., 3.], [3., 3., 3., 3.]], grad_fn=)In [6]: y.requires_gradOut[6]: True如果想改變這個屬性,就調用tensor.requires_grad_()方法:
In [22]: x.requires_grad_(False)Out[22]:tensor([[1., 1., 1., 1.], [1., 1., 1., 1.]])In [21]: print(x.requires_grad,y.requires_grad)False True這里,注意區別tensor.requires_grad和tensor.requires_grad_()兩個東西,前面是調用變量的屬性值,后者是調用內置的函數,來改變屬性。
二、求導
下面我們來試試自動求導到底怎么樣。
我們首先定義一個計算圖(計算的步驟):
In [28]: x = torch.tensor([[1.,2.,3.],[4.,5.,6.]],requires_grad=True)In [29]: y = x+1In [30]: z = 2*y*yIn [31]: J = torch.mean(z)這里需要注意的是,要想使x支持求導,必須讓x為浮點類型,也就是我們給初始值的時候要加個點:“.”。不然的話,就會報錯。
即,不能定義[1,2,3],而應該定義成[1.,2.,3.],前者是整數,后者才是浮點數。
上面的計算過程可以表示為:

好了,重點注意的地方來了!
x、y、z都是tensor,但是size為(2,3)的矩陣。但是J是對z的每一個元素加起來求平均,所以J是標量。
求導,只能是【標量】對標量,或者【標量】對向量/矩陣求導!
所以,上圖中,只能J對x、y、z求導,而z則不能對x求導。
我們不妨試一試:
- PyTorch里面,求導是調用.backward()方法。直接調用backward()方法,會計算對計算圖葉節點的導數。獲取求得的導數,用.grad方法。
試圖z對x求導:
In [31]: z.backward()# 會報錯:Traceback (most recent call last) in ()----> 1 z.backward()RuntimeError: grad can be implicitly created only for scalar outputs正確的應該是J對x求導:
In [33]: J.backward()In [34]: x.gradOut[34]:tensor([[1.3333, 2.0000, 2.6667], [3.3333, 4.0000, 4.6667]])檢驗一下,求的是不是對的。
J對x的導數應該是什么呢?
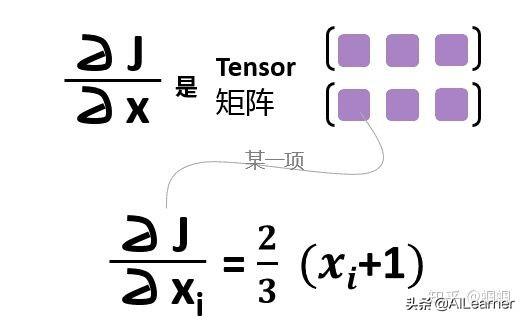
檢查發現,導數就是:
[[1.3333, 2.0000, 2.6667],
[3.3333, 4.0000, 4.6667]]
總結一下,構建計算圖(正向傳播,Forward Propagation)和求導(反向傳播,Backward Propagation)的過程就是:

三、關于backward函數的一些其他問題:
1. 不是標量也可以用backward()函數來求導?
在看文檔的時候,有一點我半天沒搞懂:
他們給了這樣的一個例子:
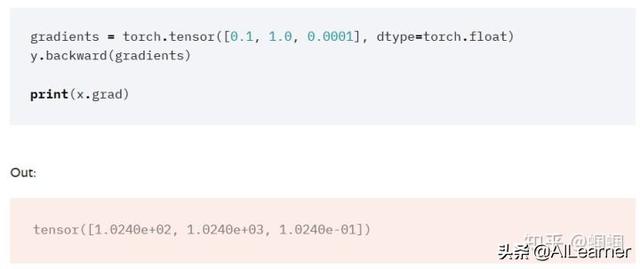
我在前面不是說“只有標量才能對其他東西求導”么?它這里的y是一個tensor,是一個向量。按道理不能求導呀。這個參數gradients是干嘛的?
但是,如果看看backward函數的說明,會發現,里面確實有一個gradients參數:


從說明中我們可以了解到:
- 如果你要求導的是一個標量,那么gradients默認為None,所以前面可以直接調用J.backward()就行了如果你要求導的是一個張量,那么gradients應該傳入一個Tensor。那么這個時候是什么意思呢?
在StackOverflow有一個解釋很好:
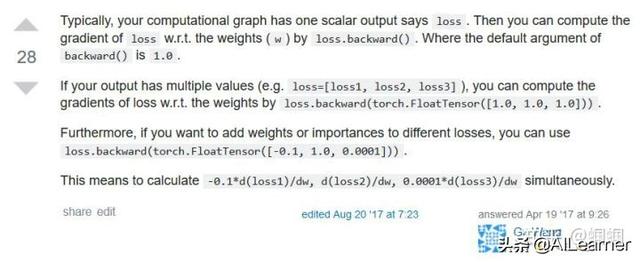
一般來說,我是對標量求導,比如在神經網絡里面,我們的loss會是一個標量,那么我們讓loss對神經網絡的參數w求導,直接通過loss.backward()即可。
但是,有時候我們可能會有多個輸出值,比如loss=[loss1,loss2,loss3],那么我們可以讓loss的各個分量分別對x求導,這個時候就采用:
loss.backward(torch.tensor([[1.0,1.0,1.0,1.0]]))
如果你想讓不同的分量有不同的權重,那么就賦予gradients不一樣的值即可,比如:
loss.backward(torch.tensor([[0.1,1.0,10.0,0.001]]))
這樣,我們使用起來就更加靈活了,雖然也許多數時候,我們都是直接使用.backward()就完事兒了。
2. 一個計算圖只能backward一次
一個計算圖在進行反向求導之后,為了節省內存,這個計算圖就銷毀了。
如果你想再次求導,就會報錯。
比如你定義了計算圖:
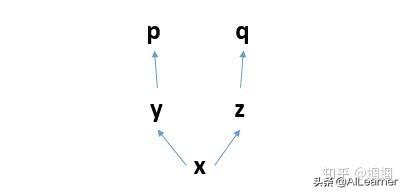
你先求p求導,那么這個過程就是反向的p對y求導,y對x求導。
求導完畢之后,這三個節點構成的計算子圖就會被釋放:
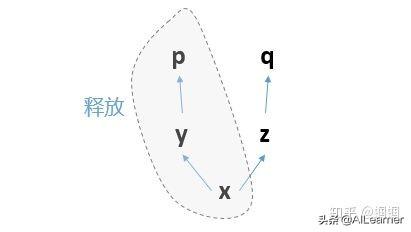
那么計算圖就只剩下z、q了,已經不完整,無法求導了。
所以這個時候,無論你是想再次運行p.backward()還是q.backward(),都無法進行,報錯如下:
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
好,怎么辦呢?
遇到這種問題,一般兩種情況:
1. 你的實際計算,確實需要保留計算圖,不讓子圖釋放。
那么,就更改你的backward函數,添加參數retain_graph=True,重新進行backward,這個時候你的計算圖就被保留了,不會報錯。
但是這樣會吃內存!,尤其是,你在大量迭代進行參數更新的時候,很快就會內存不足,memory out了。
2. 你實際根本沒必要對一個計算圖backward多次,而你不小心多跑了一次backward函數。
通常,你要是在IPython里面聯系PyTorch的時候,因為你會反復運行一個單元格的代碼,所以很容易一不小心把backward運行了多次,就會報錯。這個時候,你就檢查一下代碼,防止backward運行多次即可。
文章轉自:https://zhuanlan.zhihu.com/p/51385110






——可變剪切)





)






