歡迎關注頭條號:java小馬哥
周一至周日早九點半!下午三點半!精品技術文章準時送上!!!
精品學習資料獲取通道,參見文末

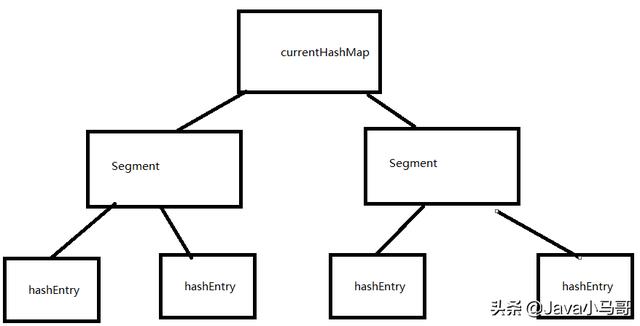
看源碼前我們必須先知道一下ConcurrentHashMap的基本結構。ConcurrentHashMap是采用分段鎖來進行并發控制的。
其中有一個內部類為Segment類用來表示鎖。而Segment類里又有一個HashEntry[]數組,這個數組才是真正用
來存放我們的key-value的。
大概為如下圖結構。一個Segment數組,而Segment數組每個元素為一個HashEntry數組
看源碼前我們還必須了解的幾個默認的常量值:
DEFAULT_INITIAL_CAPACITY = 16 容器默認容量為16
DEFAULT_LOAD_FACTOR = 0.75f 默認擴容因子是0.75
DEFAULT_CONCURRENCY_LEVEL = 16 默認并發度是16
MAXIMUM_CAPACITY = 1 << 30 容器最大容量為1073741824
MIN_SEGMENT_TABLE_CAPACITY = 2 段的最小大小
MAX_SEGMENTS = 1 << 16 段的最大大小
RETRIES_BEFORE_LOCK = 2 通過不獲取鎖的方式嘗試獲取size的次數
以上以及默認值是ConcurrentHashMap中定義好的,下面我們很多地方會用到他們。
先從初始化開始說起
通過我們使用ConcurrentHashMap都是通過 ConcurrentHashMap map = new ConcurrentHashMap<>();的方式
我們點進去跟蹤下源碼

/**
* Creates a new, empty map with a default initial capacity (16),
* load factor (0.75) and concurrencyLevel (16).
*/
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
可以看到,默認無參構造函數內調用了另一個帶參構造函數,而這個構造函數也就是不管你初始化時傳進來什么參數,最終都會跳到那個帶參構造函數。
點進去看看這個帶參構造函數實現了什么功能
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment s0 =
new Segment(loadFactor, (int)(cap * loadFactor),
(HashEntry[])new HashEntry[cap]);
Segment[] ss = (Segment[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
我們看到該構造函數一共有三個參數,分別是容器的初始化大小、負載因子、并發度,這三個參數如果我們new 一個ConcurrentHashMap時沒有指定,
那么將會采用默認的參數,也就是我們本文開始說的那幾個常量值。
在這里我對這三個參數做下解釋。容器初始化大小是整個map的容量。負載因子是用來計算每個segment里的HashEntry數組擴容時的閾值的。并發度是
用來設置segment數組的長度的。

開頭這兩個if沒什么好說的。就是用來判斷我們傳進來的參數的正確性。當負載因子,初始容量和并發度不按照規范來時會拋出算術異常。第二個if時當傳進來的
并發度大于最大段大小的時候,就將其設置為最大段大小。

這段就比較有意思了。由于segment數組要求長度必須為2的n次方,當我們傳進來的并發度不是2的n次方時會計算出一個最接近它的2的n次方值
比如如何我們傳進來的并發度為14 15那么通過計算segment數組長度就是16。在上圖中我們可以看到兩個局部變量ssize和sshift,在循環中如果ssize小于
并發度就將其二進制左移一位,即乘2。因此ssize就是用來保存我們計算出來的最接近并發度的2的n次方值。而ssfhit是用來計算偏移量的。在這里我們又
要說兩個很重要的全局常量。segmentMask和segmentShift。其中segmentMask為ssize - 1,由于ssize為2的倍數。那么segmentMask就是奇數。化為
二進制就是全1,而segmentShift為32 - sshift大小。32是key值經過再hash求出來的值的二進制位。segmentMask和segmentShift是用來定位當前元素
在segment數組那個位置,和在HashEntry數組的哪個位置,后面我們會詳細說說怎么算的。

這一段代碼就是用來確定每個segment里面的hashentry的一些參數和初始化segment數組了。第一個if是防止我們設置的初始化
容量大于最大容量。而c是用來計算每個hashentry數組的容量。由于每個hashentry數組容量也需要為2的n次方,因此這里也需要
一個cap和循環來計算一個2的n次方值,方法和上面一樣。這里計算出來的cap值就是最終hashentry數組實際的大小了。
初始化就做了這些工作了。
那么我們在說說最簡單的get方法。
get方法就需要用到定位我們的元素了。而定位元素就需要我們上面初始化時設置好的兩個值:segmentMask和segmentShift
上面說了,并發度默認值為16,那么ssize也為16,因此segmentMask為15.由于ssize二進制往左移了4位,那么sshift就是4,
segmentShift就是32-4=28.下面我們就用segmentMask=15,segmentShift為28來說說怎么確定元素位置的。
在這里我們要說下hash值,這里的hash值不是key的hashcode值,而是經過再hash確定下來的一個hash值,目的是為了減少hash沖突。
hash值二進制為32位。
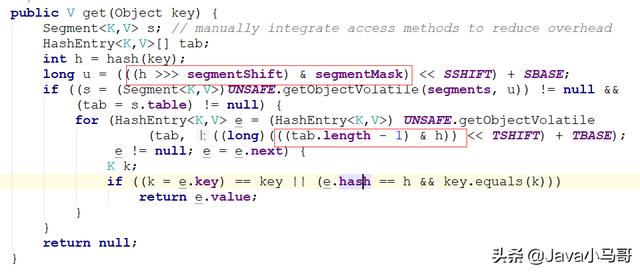
上圖兩個紅框就是分別確定segment數組中的位置和hashentry數組中的位置。
我們可以看到確定segment數組是采用 (h >>> segmentShift) & segmentMask,其中h為再hash過的hash值。將32為的hash值往右移segmentShift位。這里我們假設移了28位。
而segmentMask為15,就是4位都為一的二進制。將高4位與segmentMask相與會等到一個小于16的值,就是當前元素再的segment位置。
確定了所屬的segment后。就要確認在的hashentry位置了。通過第二個紅框處,我們可以看到確定hashentry的位置沒有使用上面兩個值了。而是直接使用當前hashentry數組的長度減一
和hash值想與。通過兩種不同的算法分別定位segment和hashenrty可以保證元素在segment數組和hashentry數組里面都散列開了。
Put方法
public V put(K key, V value) {
Segment s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry first = entryAt(tab, index);
for (HashEntry e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
上面兩片代碼就是put一個元素的過程。由于Put方法里需要對共享變量進行寫入操作,因此為了安全,需要在操作共享變量時加鎖。put時先定位到segment,然后在segment里及逆行擦汗如操作。
插入有兩個步驟,第一步判斷是否需要對segment里的hashenrty數組進行擴容。第二步是定位添加元素的位置,然后將其放在hashenrty數組里。
我們先說說擴容。

在插入元素的時候會先判斷segment里面的hashenrty數組是否超過容量threshold。這個容量是我們剛開始初始化hashenrty數組時采用容量大小和負載因子計算出來的。
如果超過這個閾值(threshold)那么就會進行擴容。擴容括的時當前hashenrty而不是整個map。
如何擴容
擴容的時候會先創建一個容量是原來兩個容量大小的數組,然后將原數組里的元素進行再散列后插入到新的數組里。
Size方法
由于map里的元素是遍布所有hashenrty的。因此統計size的時候需要統計每個hashenrty的大小。由于是并發環境下,可能出現有線程在插入或者刪除的情況。因此會出現
錯誤。我們能想到的就是使用size方法時把所有的segment的put,remove和clean方法都鎖起來。但是這種方法時很低效的。因此concurrenthashmap采用了以下辦法:
先嘗試2次通過不加鎖的方式來統計各個segment大小,如果統計的過程中,容器的count發生了變化,再采用加鎖的方式來統計所有segment的大小。
concurrenthashmap時使用modcount變量來判斷再統計的時候容器是否放生了變化。在put、remove、clean方法里操作數據前都會將辯能力modCount進行加一,那么在統計
size千后比較modCount是否發生變化,就可以知道容器大小是否發生變化了。
封面圖源網絡,侵權刪除)
私信頭條號,發送:“資料”,獲取更多“秘制” 精品學習資料
如有收獲,請幫忙轉發,您的鼓勵是作者最大的動力,謝謝!
一大波微服務、分布式、高并發、高可用的原創系列文章正在路上,
歡迎關注頭條號:java小馬哥
周一至周日早九點半!下午三點半!精品技術文章準時送上!!!
十余年BAT架構經驗傾囊相授
)











基于RASA開始中文機器人實現機制)






