[2020-AAAI] Revisiting Image Aesthetic Assessment via Self-Supervised Feature Learning 論文簡析
論文鏈接:https://arxiv.org/abs/1911.11419
本文探索從自監督的角度進行美學評估。基于一個基本的動機:一個好的美學特征表示應該能夠辨別出不同的專家設計的圖像篡改的方法。本文設計了一個針對于美學評估的自監督pretext task。

如上圖所示,在自監督pretext task預訓練階段,將原圖塊和進行不同方法不同參數的降質之后的圖塊輸入網絡,模型需要完成兩項任務,首先是分類,判斷輸入的降質圖塊是來自哪一種降質方法,然后是在同樣降質方法,不同降質參數的圖像上,模型需要最小化一個三元組損失,使得原圖塊與降質較輕的圖塊的相似度比重度降質圖塊的相似度更大,以避免某些降質方法過于容易辨認的問題。
另外,本文還設計了一個基于熵的取樣加權策略,熵值更高的圖塊會有更對不確定的視覺美學因素,因此在訓練中應當被分配更小的權重。
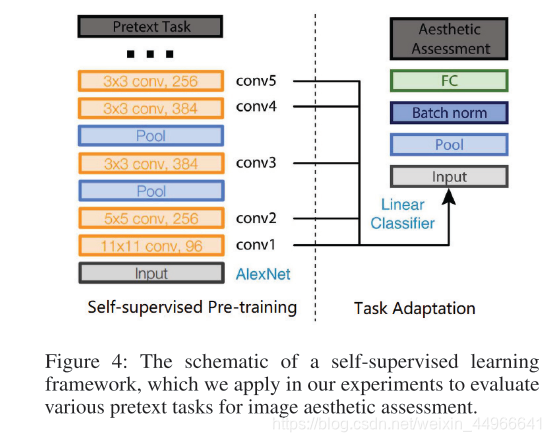
在預訓練完成后,在固定住特征提取器的參數,在美學數據集上微調分類器,如圖所示,本文中將特征提取器的各層的輸出都拿出來做了對比,結果如下(表中所展示的指標均為美學二分類準確率)。作者還選取了幾種經典的自監督pretext task與本文設計的美學相關任務做了對比。

作者根據各層的性能表現對各中間層特征的層次做了分析。
比較有關鍵的是low data adaption部分實驗,因為這里應該是體現自監督學習的優越性的地方,即在預訓練階段可以使用大量的圖像(因為不需要標注),根據自己設計的pretext task來進行訓練,在downstream task 微調時,由于根據預訓練時的pretext task,已經得到了一個對于下游任務比較有針對性的特征提取器,這樣應該只需要較少的有標簽訓練數據就可以得到比較好的性能。
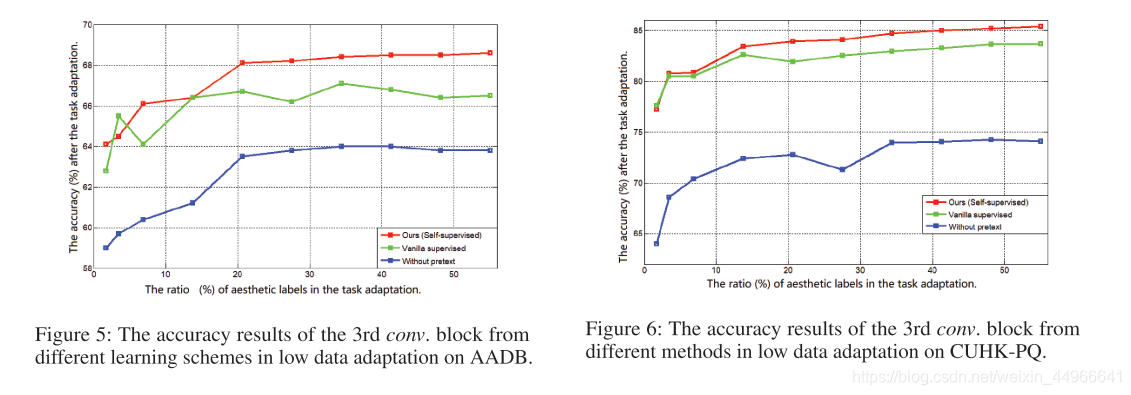
上面兩圖是作者匯報的實驗結果,可以看到在較少數量的有標簽數據時,本文方法基本是全面領先于無預訓練和有監督分類預訓練的方法的。
作者的另一實驗稱在使用非線性分類器的情況下,本文的自監督預訓練(未使用任何人工標注標簽)的最高性能基本能夠達到與有監督預訓練(用了大量人工標注標簽)相近。
最后作者的消融實驗分別說明了pretext task,不同image editting operation 和 entropy-based weighting各部分的作用。

![[2020-CVPR] Dynamic Region-Aware Convolution 論文簡析](http://pic.xiahunao.cn/[2020-CVPR] Dynamic Region-Aware Convolution 論文簡析)















![[2021-CVPR] Jigsaw Clustering for Unsupervised Visual Representation Learning 論文簡析及關鍵代碼簡析](http://pic.xiahunao.cn/[2021-CVPR] Jigsaw Clustering for Unsupervised Visual Representation Learning 論文簡析及關鍵代碼簡析)

、取地址()、解引用(*)與引用())