[2020-CVPR] Dynamic Region-Aware Convolution 論文簡析
論文地址:https://arxiv.org/abs/2003.12243
參考代碼地址(非官方):https://github.com/shallowtoil/DRConv-PyTorch
代碼筆者自己試了一下,應該是可以的,但是沒做到文中的性能,歡迎討論。
本文設計了一種新型動態區域感知卷積(DRConv),根據圖像的信息將圖像劃分為多個區域,并為每個區域單獨生成定制的卷積核。有強大的語義表示能力并且保持了平移不變性,本文還具體設計了此種卷積的反向傳播方式,根據總體的梯度進行參數更新,實現了端到端的訓練,該卷積在多項任務上具有極其優異的性能。
DRConv針對的問題是常規卷積同一個通道中所有卷積核共享參數,無法對圖像的不同的語義區域進行有針對性的卷積操作,所以標準卷積只能通過增加通道數來提取更多的視覺元素,這無疑會大幅增加計算的開銷。而本文提出的DRConv會根據圖像中不同的語義信息劃分不同的區域,然后針對每個語義區域定制不同的卷積核進行卷積,即不同區域間的卷積核的參數是不共享的、定制化的,這使得DRConv比標準卷積在建模語義信息的多樣性上表現更好。即DRConv將通道維度上的卷積核個數的增加轉換為了空間維度上可學習的區域劃分,這不僅提高了卷積的表示能力,并且保持了標準卷積的計算量和平移不變形。
作者還針對這個過程中的argmax函數無法反向傳播求梯度的問題提出了用softmax在反向傳播是近似代替argmax(hardmax)的解決方案。
實驗部分,作者將DRConv替換掉MobileNet等網絡的一些卷積層,在分類、人臉識別、檢測和分割任務上都取得了比較好的效果。
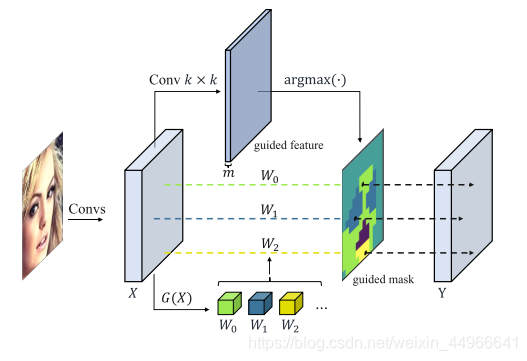
DRConv的具體結構如圖所示,我們先對輸入圖像使用標準卷積來得到guided feature。根據guided feature,將空間維度劃分為若干區域。如圖所示,guided mask中相同顏色的像素表示同一塊區域。在每個共享區域中,我們使用filter generator模塊來生成一個卷積核去執行2維的卷積操作。這樣需要優化的參數主要在filter generator模塊中,并且這些參數的數量與圖像本身的大小沒有關系。因此,除了大幅提升模型的性能外,DRConv相較于局部卷積來說參數的數量也大大下降了,與標準卷積的參數量相當。
標準卷積在空間域卷積核都使用權值共享。問題是計算不夠高效,并且優化困難。
局部卷積在不同的像素位置使用不同的權值在空間維度上使用多卷積核的方法來利用語義信息的多樣性,如此比標準卷積在提取空間特征是更加高效。但問題一是大大增加了參數量,而是是破壞了卷積的平移不變性。而且其在不同的樣本之間還是共享卷積核的,這使它對于每個樣本各自的特定特征不夠敏感。
具體來說,作者設計了一個可學習的guided mask模塊,來根據輸入圖像的特點將空間維度劃分為多個區域,將圖像劃分成不同的區域,在不同的區域上使用不同的卷積。區域內卷積是通用的,不同區域卷積不通用。GGG 是生成卷積的模塊,有多少個區域,就生成多少個卷積核 WiW_iWi? 。在每個區域內部只有一個共享的卷積核。不同樣本的不同區域的卷積核會根據輸入的相應特征動態生成,這能夠使我們更加高效地關注于它們的關鍵特征。
Method
標準卷積:
Yu,v,o=∑c=1CXu,v,o?Wc(o)Y_{u,v,o}=\sum_{c=1}^CX_{u,v,o}*W_c^{(o)} Yu,v,o?=c=1∑C?Xu,v,o??Wc(o)?
局部卷積:
Yu,v,o=∑c=1CXu,v,o?W(u,v,c)(o)Y_{u,v,o}=\sum_{c=1}^CX_{u,v,o}*W_{(u,v,c)}^{(o)} Yu,v,o?=c=1∑C?Xu,v,o??W(u,v,c)(o)?
DRConv:
Yu,v,g=∑c=1CXu,v,o?W(t,c)(o)Y_{u,v,g}=\sum_{c=1}^CX_{u,v,o}*W_{(t,c)}^{(o)} Yu,v,g?=c=1∑C?Xu,v,o??W(t,c)(o)?
可概括為兩步,兩個主要模塊:learnable guided mask模塊和filter generator模塊,前者決定哪個分類起被分配到哪個塊,后者決定根據輸入特征生成相關的卷積核
learnable guided mask
該模塊根據相應的損失函數進行參數更新,所以可以適應不同的圖像輸入產生不同的分塊
具體來說,對于一個k*k的DRConv(k是卷積核尺寸),m個區域。我們先使用k*k的標準卷積來生成m個通道的guided feature,
對于空間域中每個位置,有:
Mu,v=argmax(Fu,v0^,Fu,v1^,...,Fu,vm?1^)M_{u,v}=argmax(\hat{F_{u,v}^0},\hat{F_{u,v}^1},...,\hat{F_{u,v}^{m-1}}) Mu,v?=argmax(Fu,v0?^?,Fu,v1?^?,...,Fu,vm?1?^?)
M是guided mask(U*V),F是guided feature在(u,v)處的特征向量,有m個元素(U*V*m),該argmax取的是索引(M是個索引,取值在0到m-1之間)
為了使該模塊可學習,需要有梯度來更新參數,但是guided feature,argmax并沒有梯度,為此,本文設計了一種得到guided feature近似梯度的方法。
前向傳播
我們已經根據上式得到了guided mask,有每個位置(u,v)的卷積核如下:
W^u,v=WMu,v,Mu,v∈[0,m?1]=W?Mu,v\hat{W}_{u,v}=W_{M_{u,v}},\ \ \ \ \ \ \ \ \ \ \ M_{u,v}\in[0,m-1]=W*M_{u,v} W^u,v?=WMu,v??,???????????Mu,v?∈[0,m?1]=W?Mu,v?
WMu,vW_{M_{u,v}}WMu,v?? 是由filter generator模塊G生成的m個卷積核之一,Mu,vM_{u,v}Mu,v?是guided feature FFF位置(u,v)通道維度中最大值的索引。這樣,m個卷積核會與所有的位置建立相關關系,整個空間域的所有像素會被分成m組。各組中的像素使用同樣的濾波器,他們具有相似的語義,因為他們是通過具有平移不變性的標準卷積將他們的信息轉換到guided feature 上的。
注意:前向傳播時是one hot的hardmax
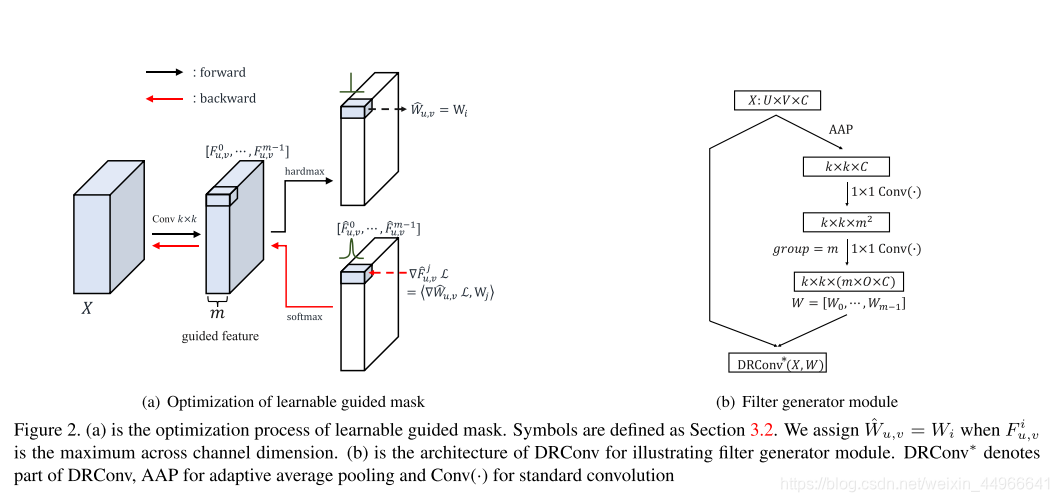
反向傳播
對 Mu,vM_{u,v}Mu,v? 的one-hot形式,如 Mu,v=2M_{u,v}=2Mu,v?=2, m=5m=5m=5,則其one-hot形式:(0,0,1,0,0)(0, 0, 1, 0, 0)(0,0,1,0,0) 作softmax得到 F^\hat{F}F^。
因為argmax是hardmax,沒法求導,所以這里在反向傳播的時候使用了softmax來近似代替。
filter generator
該模塊功能主要體現在針對不同輸入圖像,抓住其獨有特征。
具體做法如上圖右側所示:先經過一個自適應的池化層將 U?V?CU*V*CU?V?C 的圖像降采樣到 k?k?Ck*k*Ck?k?C ,再經過兩個 1?11*11?1 的卷積得到 mmm 個卷積核。
experiments
分類檢測分割均有提升,表就不放了,有興趣請自行查看原文。
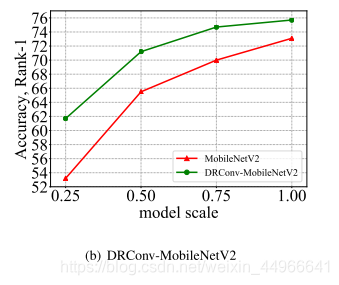
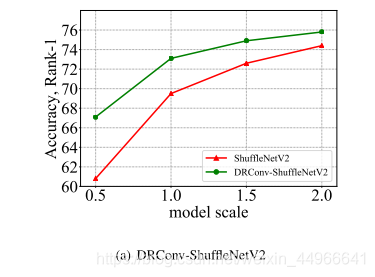
可以看到模型規模越小,本文方法提升越明顯,這是因為DRConv在空間維上提高了語義表達能力,對于表達能力較弱的小模型,幫助更為明顯。
不同層的可視化,可以看到有比較明顯的按照語義進行區域劃分的效果。
















![[2021-CVPR] Jigsaw Clustering for Unsupervised Visual Representation Learning 論文簡析及關鍵代碼簡析](http://pic.xiahunao.cn/[2021-CVPR] Jigsaw Clustering for Unsupervised Visual Representation Learning 論文簡析及關鍵代碼簡析)

、取地址()、解引用(*)與引用())

