(2021) 26 [持久化] 持久數據的可靠性:RAID和journaling
南京大學操作系統課蔣炎巖老師網絡課程筆記。
視頻:https://www.bilibili.com/video/BV1HN41197Ko?p=26
講義:http://jyywiki.cn/OS/2021/slides/16.slides#/
背景
回顧
文件系統 = 把設備抽象成目錄樹
- mount - 文件系統管理
- mkdir, rmkdir, link, symlink, unlink… - 目錄管理
- open, mmap, read, write, lseek… - 文件管理
- 使用鏈表、索引、……實現
如何實現高可靠、高性能?
本次課的內容和目標
- RAID:Redundant Array of Inexpensive Disks,把多塊磁盤虛擬化成一塊性能更好、更可靠的磁盤。
- 崩潰一致性:如何在硬件可能崩潰的情況下保證文件系統(數據結構)的一致性。
RAID:Redundant Array of Inexpensive Disks
RAID:Redundant Array of Idependent / Inexpensive Disks
持久數據的可靠性
任何物理存儲介質都有失效的可能,你依然希望在存儲設備失效的時候能保持數據的完整。
- 極小概率事件:戰爭爆發/三體人進攻地球/世界毀滅
- 小概率事件:硬盤損壞。但是當小概率時間大量重復,那就是必然發生。但我們還是希望系統能照常運轉。
增加持久數據可靠性的方法
備胎:雞蛋不能放在一個籃子里
- 教務處:物理備份
- 期末考試后會提交所有批閱的試卷、成績表、成績分布
- 假設教務系統崩潰 v.s. 教務處崩潰是獨立事件
- 兩個極小概率事件同時發生,那就認倒霉吧
- 服務器:數據備份
- 所有數據同時寫入兩塊磁盤
- 每日或每周備份
- crontab (time-based job scheduler)
RAID: 存儲設備的虛擬化
RAID (虛擬化) = 虛擬磁盤塊到物理磁盤塊的 “映射”。
Redundant Array of Inexpensive (Independent) Disks (RAID)
- 把多個 (不可靠的) 磁盤虛擬成一塊非常可靠的虛擬磁盤
類比我們見過的虛擬化
- 進程:把一個 CPU 分時虛擬成多個虛擬 CPU
- 虛存:把一份內存通過 MMU 虛擬成多個地址空間
- 文件:把一個存儲設備虛擬成多個虛擬磁盤
RAID 的虛擬化是 “反向” 的
- (一個 → 多個) vs. (多個 → 一個)
RAID 所針對的 Fault Model: Fail-Stop
磁盤可能在某個時刻忽然徹底無法訪問 (數據好像完全消失)。如機械故障、芯片故障等,磁盤好像就 “忽然消失” 了。假設磁盤能報告這個問題 (如何報告?)
你還敢用這個硬盤做 {教務系統, 支付寶, 銀行, …} 嗎?總有一天,一定有磁盤會壞掉的,壞事件一旦發生,就有數據會丟失,永遠不丟失數據似乎是不可能的。我們還能構造可靠的 (單機) 存儲系統嗎?
RAID - 想法
假設我愿意在系統里多接入一塊硬盤用于容災。通過設備驅動程序抽象成 “一個磁盤” VVV (例如1TB)實際由 A,BA, BA,B 兩塊 1TB 的物理磁盤組成鏡像
- readb(VVV, blk),可以從 A 或 B 中的任意一個讀取。
- writeb(VVV, blk),將同樣的數據寫入 A, B 的同一位置。
假設內存帶寬遠高于磁盤帶寬,那我們這樣的做法
- 1X write (浪費了 1/2 的總帶寬)
- 2X sequential read (tricky)
- 2X random read (使用了 100% 的總帶寬)
- 抵抗任意一塊盤的損壞
實際上,這種做法就是RAID-1。寫的時候,寫入兩塊實際的盤用于容災;讀的時候可以同時從兩塊盤讀增加帶寬。即我們可以用多塊盤,來組成一塊更快、更可靠的虛擬磁盤。
RAID - 0
RAID-0: 把多塊盤 “交替拼接”
性能分析
RAID-0: 把多塊盤 “交替拼接”
- V0→A0,V1→B0,V2i→Ai,V2i+1→BiV_0→A_0, V_1→B_0, V_{2i}→A_i, V_{2i+1}→B_iV0?→A0?,V1?→B0?,V2i?→Ai?,V2i+1?→Bi?
- 完美擴展的高性能虛擬磁盤,100% 順序/隨機讀寫總帶寬
- 但完全不能容錯
對比RAID-1 (鏡像):
- V0→(A,B)V0→(A,B)V0→(A,B)
- 讀帶寬100%
- 容忍一塊盤 fail
RAID - 4
RAID: 允許 “多對多” 的映射 (一組映射稱為 “條帶”, stripe)。(V0,V1)→(A,B,C,D)(V_0,V_1)→(A,B,C,D)(V0?,V1?)→(A,B,C,D),其中A=B=V0,C=D=V1A=B=V_0, C=D=V_1A=B=V0?,C=D=V1?。
另一種可能的方式:(V0,V1,V2)→(A,B,C,D)(V_0,V_1,V_2)→(A,B,C,D)(V0?,V1?,V2?)→(A,B,C,D)。“三塊映射到四塊”。
不妨假設所有的條帶 Vi,A,B,C,DV_i,A,B,C,DVi?,A,B,C,D 的每個塊都只有 1-bit。
問題:如何用 4 個 bit 存儲 3-bit 信息,使得 4 個 bit 中的任何一個丟失,都能恢復出存儲的 3-bit 的信息?
異或!奇偶校驗!
對于 bits ,a1,a2,…,ana_1,a_2,…,a_na1?,a2?,…,an?
- 存儲時,an+1=a1⊕a2⊕…⊕ana_{n+1}=a_1⊕a_2⊕…⊕a_nan+1?=a1?⊕a2?⊕…⊕an?,移項得 a1⊕a2⊕…⊕an⊕an+1=0a_1⊕a_2⊕…⊕a_n⊕a_{n+1}=0a1?⊕a2?⊕…⊕an?⊕an+1?=0。
- 任何一個 bit 丟失 (對應A,B,C,DA,B,C,DA,B,C,D 中某塊硬盤不能啟動),可以根據 ai=a1⊕a2⊕…⊕ai?1⊕ai+1?⊕ana_i=a_1⊕a_2⊕…⊕a_{i-1}⊕a_{i+1}\dots⊕a_nai?=a1?⊕a2?⊕…⊕ai?1?⊕ai+1??⊕an?,來計算出丟失的位。
舉個例子,如下圖:

我們共有四塊盤A、B、C、PA、B、C、PA、B、C、P,其中A、B、CA、B、CA、B、C存儲數據,PPP盤做奇偶校驗。我們假設一開始數據盤存儲的數據為:(A,B,C)n=(0,1,0)(A,B,C)_n=(0,1,0)(A,B,C)n?=(0,1,0),(A,B,C)m=(1,0,1)(A,B,C)_m=(1,0,1)(A,B,C)m?=(1,0,1)。則由此我們可以根據 Pn=An⊕Bn⊕CnP_n=A_n⊕B_n⊕C_nPn?=An?⊕Bn?⊕Cn?,算出Pn=1P_n=1Pn?=1,Pm=0P_m=0Pm?=0。這時我們假設 AAA盤不幸掛掉了,我們就可以根據B、C、PB、C、PB、C、P盤恢復出AAA盤的數據:An=Pn⊕Bn⊕CnA_n=P_n⊕B_n⊕C_nAn?=Pn?⊕Bn?⊕Cn?,從而計算出An=0A_n=0An?=0,Am=1A_m=1Am?=1。
RAID-4: Parity Disk,專門留一塊磁盤作為奇偶校驗盤。
- (V0,V1,V2)→(A,B,C,P)(V0,V1,V2)→(A,B,C,P)(V0,V1,V2)→(A,B,C,P)
- A=V0,B=V1,C=V2A=V_0, B=V_1, C=V_2A=V0?,B=V1?,C=V2?
- P=V0⊕V1⊕V2P=V_0⊕V_1⊕V_2P=V0?⊕V1?⊕V2? (奇偶校驗)
性能分析
- sequential/random read: 3x (75% 總帶寬)
- sequential write: 3x (75% 總帶寬)
- random write (tricky)
- D=V0⊕V1⊕V2D=V_0⊕V_1⊕V_2D=V0?⊕V1?⊕V2?
- 寫入任意V0,V1,V2V_0,V_1,V_2V0?,V1?,V2?都需要更新DDD,更新 V0V_0V0? 需要 readb({A,PA,PA,P}), writeb({A,PA,PA,P})。奇偶校驗盤成為了寫瓶頸: 0.5x。
RAID - 5:Rotating Parity
RAID - 5:交錯排列 parity block
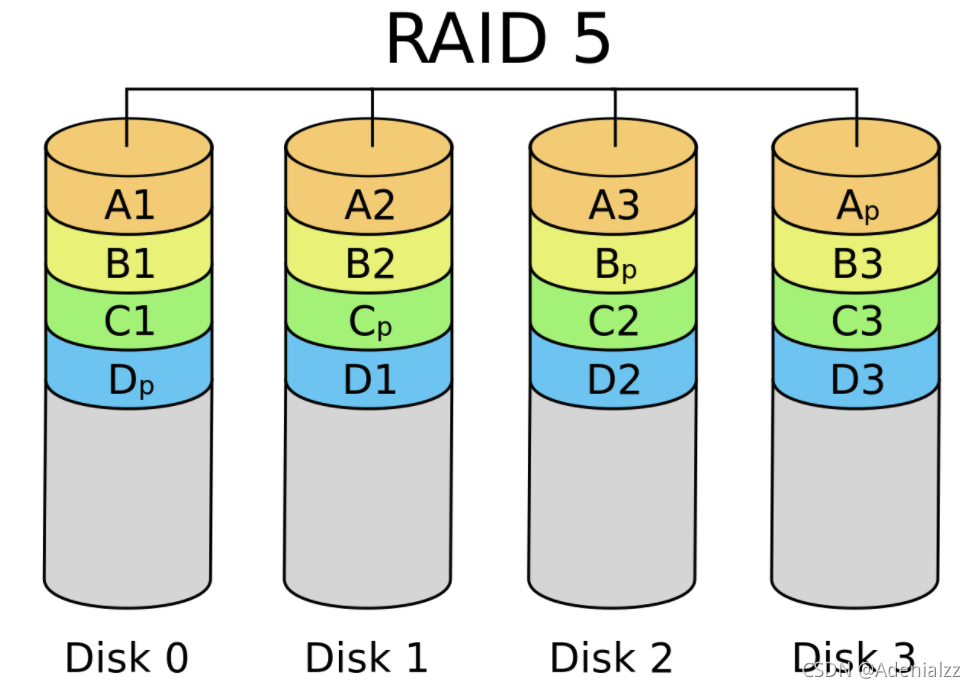
性能分析
交錯排列 parity block,讓每一塊盤都有均等的機會存儲 parity
-
sequential read/write: 3x (75% 總帶寬)
-
random read (tricky),(read 足夠大,所有磁盤都可以提供數據) 4x (100% 總帶寬)
-
random write (tricky),D=V0⊕V1⊕V2D=V_0⊕V_1⊕V_2D=V0?⊕V1?⊕V2?; 寫入任意 V0,V1,V2 都需要更新 D0
奇偶校驗依然嚴重拖慢了隨機寫入,但至少 n 塊盤可以獲得 n/4 的隨機寫性能 (能夠 scale)
RAID - 更多地討論
更快、更可靠、近乎免費的大容量磁盤已經成為今天服務器的標準配置。
RAID 的可靠性
- RAID 系統發生斷電?例子:RAID-1 鏡像盤出現不一致的數據
- 檢測到磁盤壞?自動重組
崩潰一致性
另一種 Fault Model
我們的硬件的可靠性可以由RAID做到一定程度的保證,而我們的文件系統,是在磁盤驅動上做的虛擬化,是一棵目錄樹,它的可靠性我們需要單獨分析。
磁盤并沒有故障,但操作系統內核可能 crash,系統可能斷電。在內存中讀寫時,我們不會考慮到一致性的問題。因為內存掉電數據全部丟失,我們回來重新跑程序就是了。但是在磁盤讀寫時,由于我們的磁盤時持久化的存儲設備,就會涉及到崩潰一致性的問題。比如,以ext2文件系統為例,即使只是向文件的末尾append一個字節的數據,也涉及到bitmap、inode和實際data三部分的寫入,那假如在我們剛剛寫完bitmap時,系統斷電了,后面兩部分都沒有寫完,我們這時的文件系統還是正確的嗎?有點像我們并發程序設計中的原子性,即崩潰的時候,寫磁盤的原子性被打破了。
崩潰一致性 (Crash Consistency)
Crash Consistency: Move the file system from one consistent state (e.g., before the file got appended to) to another atomically (e.g., after the inode, bitmap, and new data block have been written to disk).
導致崩潰一致性的原因就如同我們上面介紹的那樣,源自于原子性的喪失:
- RAID: write(V0V_0V0?) → write(AAA), write(BBB)
- ext2 (文件追加寫入一塊): write(inode); write(bitmap); write(data);
- 但是存儲設備的多次寫入沒有原子性保證
- 有些磁盤在設計時,甚至為了性能,沒有順序保證
- (類似我們之前講的 并發編程:從入門到放棄)
原子性喪失:后果
考慮追加寫入一個數據塊,磁盤上數據結構的更新,包括我們之前說過的b(bit), i, d三個部分的寫:
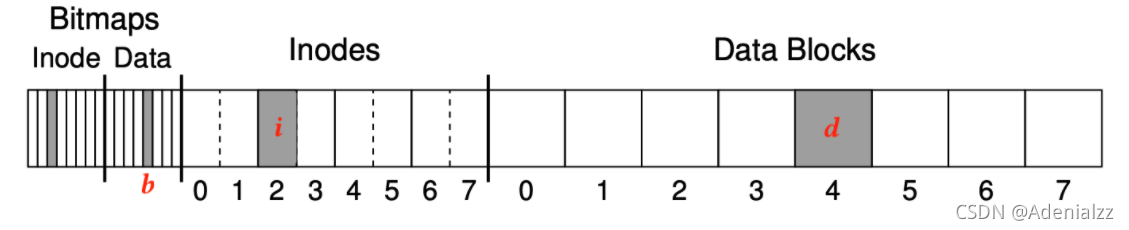
我們接下來分別分析,只寫了三個部分中的某一部分時的后果:
- {b} - dead block,如果只寫了bitmap,而inodes和data blocks都沒有寫的話,就相當于一塊block被標記為了已用,雖然實際上時還沒有寫過的,可用的block,但是再也不能被用到了,成為了一塊dead block。有點類似于malloc了當時沒有free的內存泄漏。(磁盤泄漏?)
- {i} - dangling pointe, 如果只寫了inode,但是沒寫bitmap和data blocks的話,問題就大了。試想這樣一種情況,某個高權限的人寫入了自己的私密信息(如密碼等)到某個文件,但在這個寫入過程中斷電了,只寫了inode,但是沒寫bitmap和data blocks。那這一塊就會被認為是還未寫的,如果有人試圖分配這塊block,就可以獲得它的讀寫權限,可能會訪問到上述私密信息。如果被別有用心之人構造大量的workload,來獲取大量的磁盤上寫了 i 但是沒寫 b 和 d 的塊的讀寫權限,后果不堪設想,相當于本磁盤的數據安全性已經得不到保證。
- {d} - random writes (沒有一致性問題)
- {b,i} - incorrect data
- {i,d} - dangling pointer
- {b,d} - dead block
崩潰恢復:FSCK(File System Checking)
大家可能會有印象,早年間的Windows XP系統在不正常關機之后,會在再次開機藍屏時問你要不要檢測磁盤,如果要檢測,就會是一個很漫長的等待時間,這就是在做FSCK(File System Checking)。
根據磁盤上已有的信息,恢復出 “最可能” 的數據結構
- 檢查 inode 標記的數據塊是否 bitmap 都標記為 “1”
- 檢查 inode 數據是否 “看起來合法”,否則刪除
- 檢查是否存在 dangling link,沒有鏈接的 inode 被移到 lost+found 目錄中,lost+found目錄大家應該都在Linux系統中見到過,就在完成FSCK檢測時創建的
剛才的哪些情況可以由 fsck 修復?
- {b,i} - incorrect data
- {i,d} - dangling pointer
- {b,d} - dead block
FSCK的難題
到底誰是對的?
在發生不一致時,“到底什么是對的”?在發生不一致時,可能會有多種情況導致現有的情況,那么到底應該按哪一種來恢復呢?
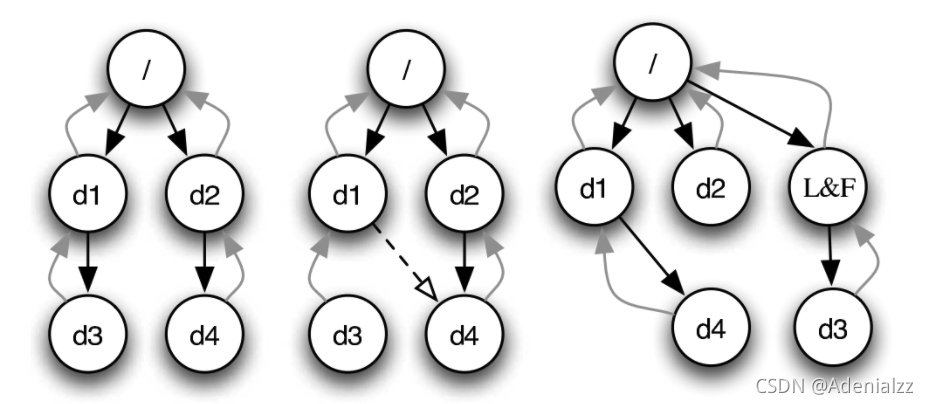
如果 fsck 的時候發生崩潰
fsck 也是程序,fsck 也要訪問文件系統。如果 fsck 時發生崩潰,由于 fsck 完成的工作比一般的磁盤讀寫更加危險,文件系統可能進入徹底無法恢復的狀態!
因此fsck 更多用于磁盤發生部分損壞時的數據搶救。
針對 crash,我們需要更可靠的方法我們需要一個更可靠的方法,文件系統不一致的根本原因是存儲設備無法提供多次寫入的原子性
崩潰恢復:journaling
日志 (Journaling)
能否在磁盤 API 上實現可靠的 multi-write 原子性?
- readb (讀一塊), writeb (寫一塊), sync (等待所有過去的寫入落盤)
數據結構的兩種實現方法
我們前面說到要將文件系統理解為磁盤上的數據結構。
- 存儲實際數據結構,這是我們學習數據結構時常見的表示形式
- 文件系統的 “直觀” 表示
- crash unsafe
- append-only 記錄所有歷史操作,這種形式不常見,聽起來也很離譜,但是在維護崩潰一致性時卻有關鍵作用
- “重做” 所有操作得到數據結構的當前狀態
- 容易實現崩潰一致性
append-only 的數據結構也是實現分布式系統的關鍵技術。
實現 Atomic Append
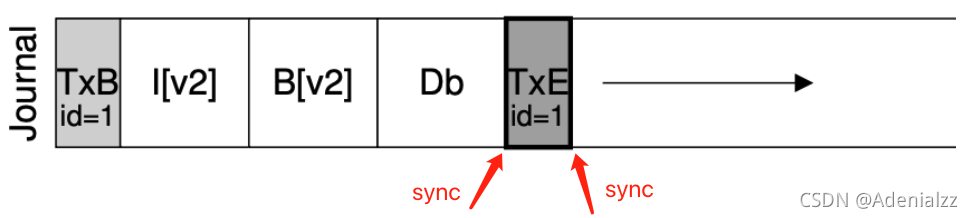
-
定位到 journal 的末尾 (使用 readb)
-
在 journal 末尾 append TXBegin,并記錄所有操作
記錄文件系統操作 v.s. 記錄磁盤塊操作
-
sync,等待數據落盤
-
append TXEnd
-
sync,等待 TXEnd 落盤
sync 返回后持久化完成 (“committed”)
實現 Crash Consistency
小孩子才做選擇,我文件系統全都要! — 兩種數據結構的便是形式都維持
主要維護文件系統的結構,但預留一定的 journal 區域,journal commit 后,可以將 journal 中的操作直接應用到文件系統上 (checkpoint)。
- redo logging (write-ahead logging): journal 記錄 “做什么”
- 先寫 journal,再寫文件系統
- 崩潰恢復時,重做 journal 中的操作
- undo logging: 記錄如何 “撤銷” 操作 (即塊中的數值)
- 先寫文件系統,再寫 journal
- 崩潰恢復時,撤銷文件系統中的
Journaling: 優化
現在為了做journaling,磁盤需要寫入雙份的數據,性能會大幅下降,我們需要再性能和可靠性之間做一個trade-off。下面是集中常見的文件系統的實現方式:
- 批處理 (xv6; jbd)
- 多次系統調用的 Tx 合并成一個,減少 log 的大小
- jbd: 定期 write back
- Checksum (ext4)
- 不再標記 TxBegin/TxEnd
- 直接標記 Tx 的長度和 checksum
- Metadata journaling (ext4 default)
- 數據占磁盤寫入的絕大部分,只對 inode 和 bitmap 這些關鍵信息做 journaling 可以提高性能
- 保證文件系統的目錄結構是一致的;但數據可能丟失
為應用程序提供 Multi-Write 的一致性?
在未來,可能會有TxOS, 提供三個新的系統調用
- xbegin, xend, xabort
- 實現多個系統調用的原子性
- 應用場景:數據更新、軟件更新、check-use……
- D. E. Porter, et al. Operating systems transactions. In Proc. of SOSP, 2009.
總結
本次課內容與目標
持久數據的可靠性
- fail-stop: RAID
- 隨機損壞:fsck
- 崩潰:journaling
Takeaway messages
- 把磁盤理解成 “數據結構”
_百度百科)













)
)



![[分布式訓練] 單機多卡的正確打開方式:PyTorch](http://pic.xiahunao.cn/[分布式訓練] 單機多卡的正確打開方式:PyTorch)