深度學習自動編譯和優化技術調研
轉自:https://moqi.com.cn/blog/deeplearning/
作者:墨奇科技全棧開發
在墨奇科技,我們需要將一些包含深度神經網絡(DNN)的 AI 算法移植到邊緣端的設備, 這些設備往往使用 ARM 架構的 CPU 和一些特殊的邊緣端推理芯片(NPU)。這個時候,我們可以使用 NPU 產商提供的推理框架(例如瑞芯微的 rknn-toolkit)或 TensorFlow Lite 這樣的通用邊緣端推理框架。另一個選擇是使用深度神經網絡編譯器,自動化的生成對模型和硬件最適合的機器代碼。我們將這個領域內的一些論文和開源項目進行了梳理。
為什么需要深度神經網絡編譯器
深度學習在我們的日常生活中無處不在。深度神經網絡(DNN)可以識別圖像,處理自然語 言,甚至在一些很有挑戰性的策略游戲中擊敗人類。當前的深度學習框架,如 TensorFlow1、MXNet2 和 PyTorch3,支持使用 GPU 加速深度學習模型的訓練 和推理,這種支持依賴于由 GPU 產商提供的高度優化的張量算子庫(比如 NVIDIA 的 cuDNN)。對于一個張量算子,存在許多邏輯上等效的實現,但由于線程、內存重用、流水 線和其他硬件因素的差異,這些實現在性能上會有很大差距。為了優化張量算子,程序員必 須從這些邏輯等效的實現中選擇性能最好的。這些算子級別的優化需要大量的手動調整,非 常的專業和不透明,而且無法輕松地跨硬件設備移植。因此,一個深度學習框架如果想要支 持不同的硬件后端,需要大量的工程工作。即使在當前受支持的硬件上,開發深度學習框架 和模型也受到庫中優化算子集合的限制,從而阻止了可能產生不受支持的算子的優化(例如 計算圖優化和算子融合)。
從云服務器到自動駕駛汽車和嵌入式設備,我們需要將包含 DNN 的 AI 應用程序部署到各 種各樣不同的設備上。由于硬件的多樣性,存在 CPU、GPU、ASIC(如 TPC 和 NPU)、FPGA 等不同類型的硬件,這些硬件的設計目標在內存組織、計算功能單元等方面都有很大的不同 (下圖展示了 CPU、GPU 和 TPU 的不同內存組織和計算功能單元),將深度學習模型映射 到這些硬件設備變得很復雜。深度學習框架依靠計算圖的中間表示來實現優化,例如自動微 分和動態內存管理。但是,計算圖級別的優化通常過于高級,無法處理特定硬件后端的算子級轉換 。
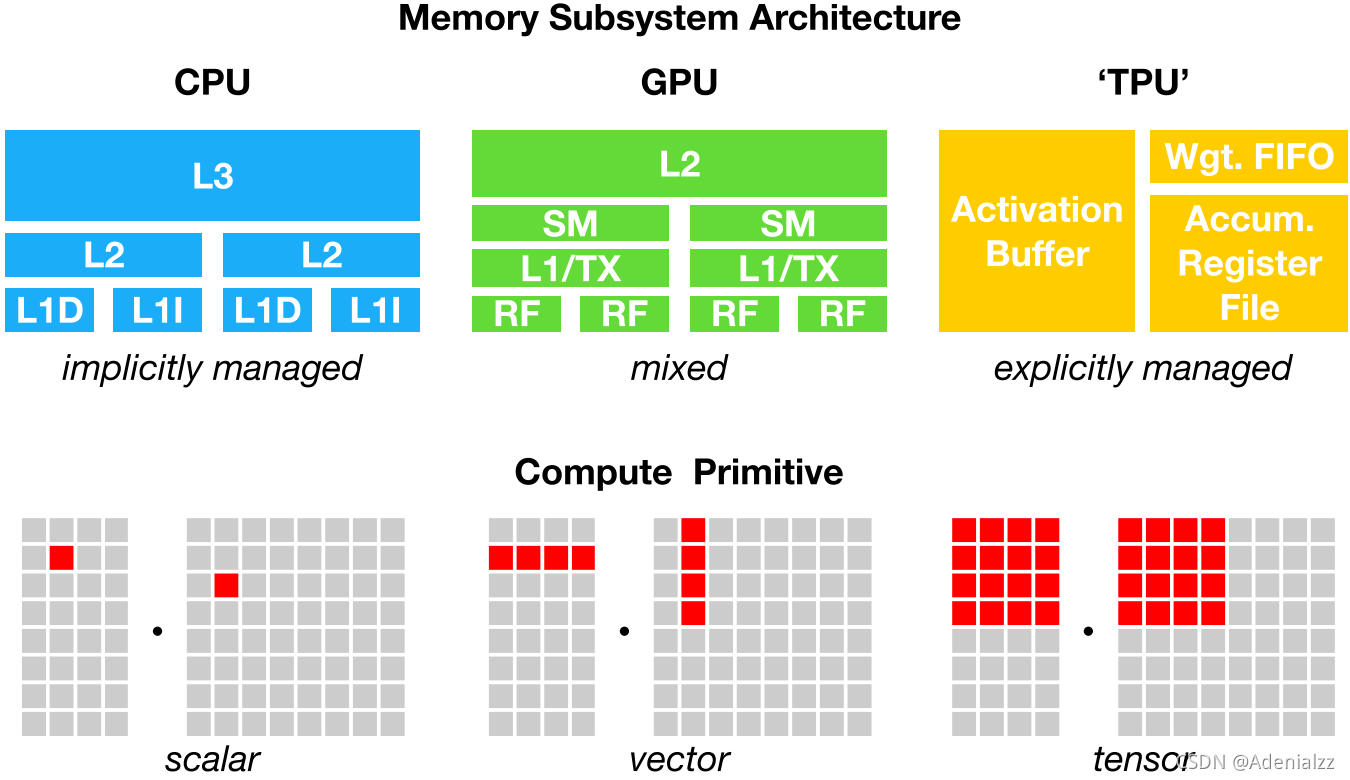
為了在不同的硬件后端上同時實現計算圖級別和算子級別的優化,讓深度學習計算被更廣泛 的應用,我們需要一套自動化的針對不同硬件后端的深度學習編譯技術。
主要工作
這節我們介紹深度學習編譯技術中的一些代表性工作。
TVM
為了解決上一節所說的種種問題,陳天奇等人提出了 TVM4,第一個端到端的深度學習自 動編譯和代碼生成方法。TVM 允許將高級框架(如 TensorFlow、MXNet、PyTorch 等)專用 的深度學習網絡部署到多種硬件后端上(包括 CPU、GPU 和基于 FPGA 的加速器)。在設計 上,TVM 結合了內存訪問、線程模式和新的硬件元語,建立一個足夠大的搜索空間,保證可 能的人工工程優化全部包含在這個搜索空間里面。TVM 通過快速的搜索這個搜索空間,生成 可部署代碼。其性能可與當前最優的硬件供應商庫相比,且可適應新型專用加速器后端。
TVM 是一個由社區維護的開源項目,來自全世界的貢獻者們 仍然在持續的改進它。2018 年,陳天奇等人提出了 AutoTVM5,旨在通過機器學習來編 譯優化深度學習系統底層算子。當 TVM 建立了足夠大的搜索空間后,剩下的問題是如何在 幾十億的可能性里面去選擇比較好的實現。這里有幾種常見的做法。傳統的高性能計算庫如 會采用自動整定(auto tuning),也就是把可能的參數都嘗試一遍。這樣做的潛在問題是 空間太大之后枚舉開銷過高。另外一種常見的做法是類似于數據庫做查詢優化的做法,針對 程序建立一個代價估價函數,然后利用估價函數來搜索。這個做法可能碰到的主要問題是估 價函數不一定可以估計準確,并且針對每個新的硬件特性必須要重新設計估價函數。 AutoTVM 利用機器學習來學習程序空間的代價估價函數。具體地說, 探索程序在一開始會 隨機地選取一些設定,直接到硬件上面去運行生成的代碼,再通過得到的反饋數據來更新程 序代價估計函數。這里面比較有趣的一點是模型的可遷移性。因為真正的深度學習系統需要 優化許多不一樣輸入類型和輸入形狀的算子。一個可遷移的模型可以通過學習已經看到過的 算子優化記錄來預測新的目標的代價,導致最后的搜索時間可以大幅降低。
Relay6 是一種功能多樣的編程語言,TVM 用 Relay 作為深度學習模型的中間表示( IR, intermediate representation)。Relay 支持代數數據類型、閉包、控制流和遞歸, 從而可以直接表示比基于計算圖的中間表示更復雜的模型。Relay 還包括一種使用類型關系 的依賴類型的形式,來處理對參數形狀有復雜的要求的操作符的形狀分析。Relay 在設計上 是可擴展的,這使得機器學習的研究人員和實踐者可以很容易地開發新的大型程序轉換和優 化。
鄭憐憫等人在 TVM 的基礎上實現了 Ansor7。Ansor 主要解決了 TVM 中的兩個問題:
- 如何自動化的構造一個更大的搜索空間?Ansor 使用了一個層次化的搜索空間;
- 如何更有效的進行搜索?Ansor 在搜索過程中增加了采樣,先對完整的程序進行采樣然 后再調整,提高了搜索效率。
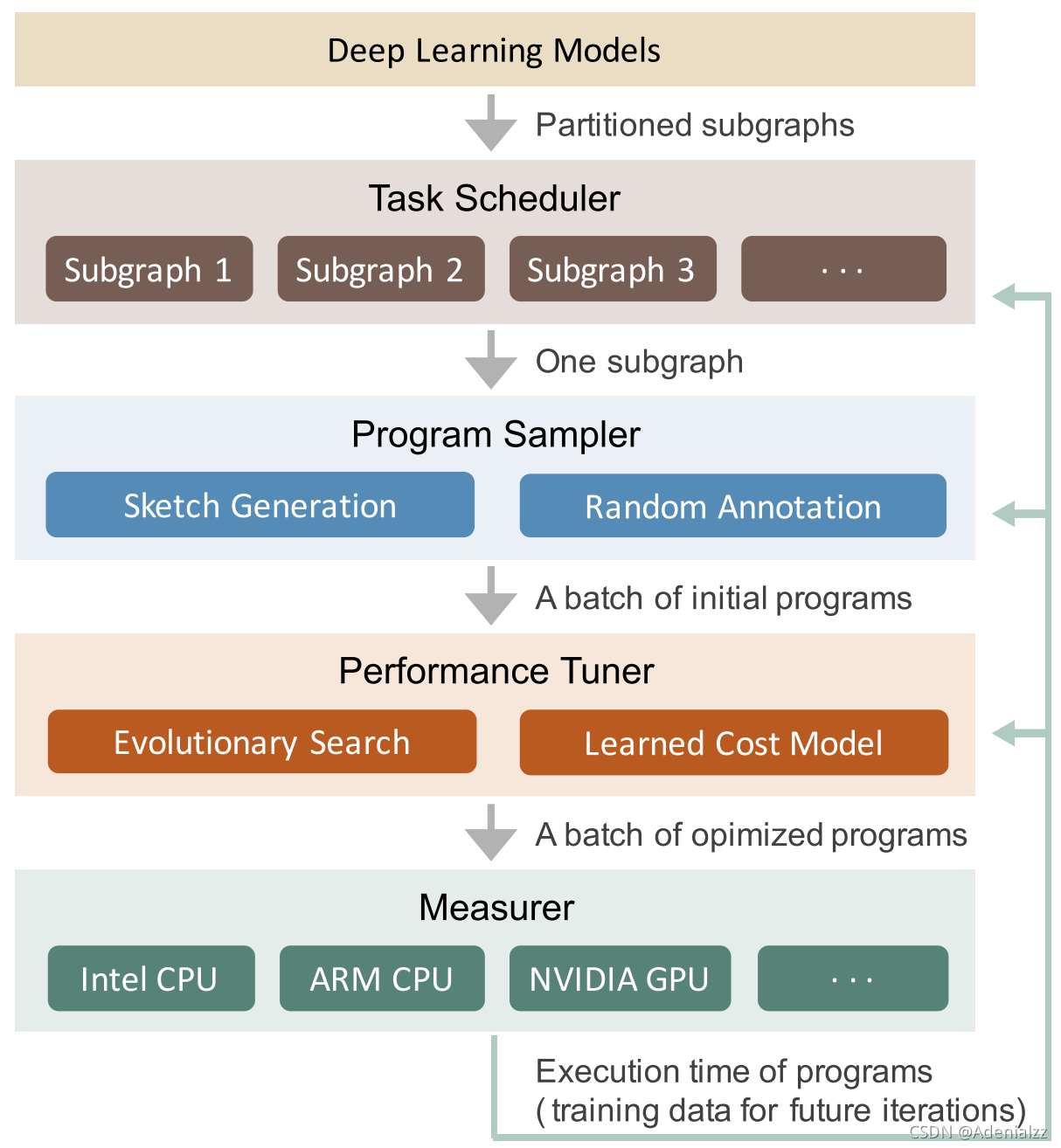
下圖展示了 Ansor 的整體架構。Ansor 的輸入是一組待優化的深度神經網絡(DNN)。 Ansor 使用 Relay6 中的算子融合算法,將 DNN 從流行的模型格式(如 ONNX 和 TensorFlow PB)分割成的小子圖。然后 Ansor 為這些子圖生成張量程序。Ansor 有三個主 要部分:(1) 程序采樣器(program sampler):構建一個大的搜索空間,并從中采樣不同 的程序;(2) 性能調整器(performance tuner):對采樣程序的性能進行微調;(3) 任務 調度器(task scheduler):為優化 DNN 的多個子圖分配時間資源。
Rammer
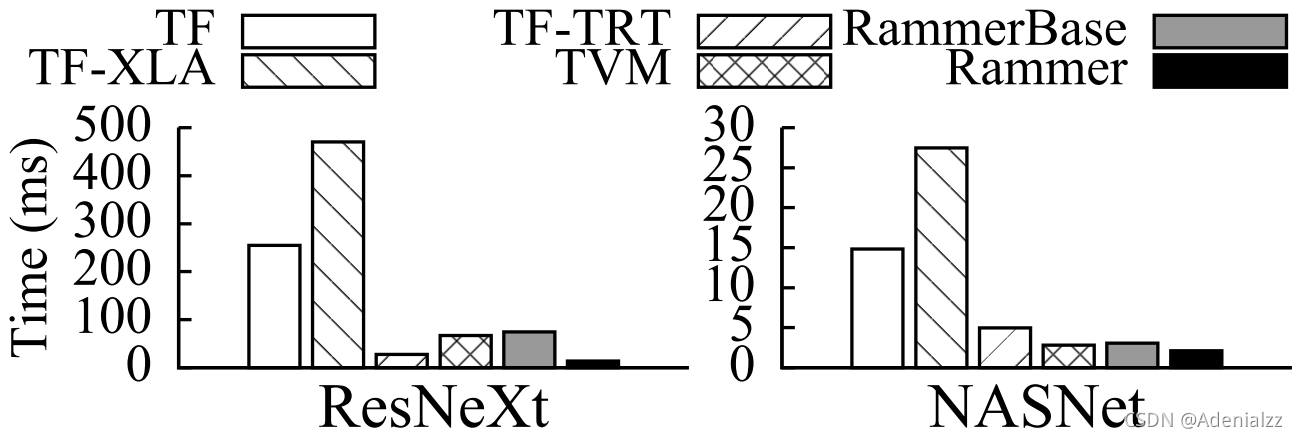
Rammer8 是微軟發布的一個針對深度神經網絡的自動編譯框架。Rammer 針對的主要是并 行計算能力較強的 GPU 和 ASIC 神經網絡加速器。在神經網絡中,有兩個層級可以通過并 行來加速,第一層是在神經網絡的計算圖上,可以將相互之間獨立的算子并行化;第二層是 在一個算子的內部,比如矩陣乘法,可以使用并行計算加速。Rammer 的特點是提供了對算 子和硬件的兩種抽象,統一的對兩層級的并行進行調度,提高了并行編排的效率。作者在 NVIDIA GPU、AMD GPU 和 GraphCore IPU 上進行了實驗,如下圖所示,NVIDIA GPU 上的實 驗表明,Rammer 在部分模型上的效果超越了 TensorFlow、TVM 和 TensorRT。
MLIR
Google 在 2019 年的 C4ML 上發布了 MLIR9。 MLIR (multi-level intermediate representation) 是一種用來構建可重用和可擴展編譯 基礎設施的新方法,它是 Google 用于統一其 TensorFlow 中眾多中間表示的路徑。乍看之 下,MLIR 似乎可以替代 XLA 和相關的 TensorFlow 編譯器,但事實并非如此。 MLIR 是用 于構建一組可互操作的中間表示「方言」的共享基礎結構,可用于構建編譯器。 MLIR 項目 正在針對 TensorFlow 的中間表示和低級多面體中間表示的方言開展工作,但是尚沒有基于 MLIR 的深度學習的端到端解決方案。MLIR 深受 LLVM 的影響,并不折不扣地重用其許多優 秀理念,比如擁有靈活的類型系統,可在同一編譯單元中表示、分析和轉換結合多層抽象的 圖等。這些抽象包括 TensorFlow 算子、嵌套的多面循環區域乃至LLVM 指令和固定的硬件 操作及類型。
為區分不同的硬件與軟件受眾,MLIR 提供中間表示「方言」,其中包括:
- TensorFlow IR,代表 TensorFlow 圖中可能存在的一切
- XLA HLO IR,旨在利用 XLA10 的編譯功能(輸出到 TPU 等)
- 實驗性仿射方言,側重于多面表示與優化
- LLVM IR,與 LLVM 自我表示之間存在 1:1 映射,可使 MLIR 通過 LLVM 發出 GPU 與 CPU 代碼
- TensorFlow Lite,將會轉換以在移動平臺上運行代碼
TorchScript
TorchScript11 是一種類似 Python 的高級中間表示,它是作為 PyTorch 的 JIT (Just-In-Time) 編譯器的第一層。 PyTorch(從v1.0開始)可以將一部分用戶程序重寫為 TorchScript(Python 的理想化子集)。 然后,TorchScript 可以由 TorchScript VM 執 行,也可以通過 JIT 編譯到目標平臺。 TorchScript 位于代碼生成之上的多個層次,并且 必須適應 Python 的靈活語義,從而排除了所有的靜態分析優化方法。 為了優化這種動態 行為,TorchScript 有一種用于性能分析的 JIT 模式,該模式在執行期間標識穩定的程序 trace。 然后,可以通過低級編譯器(例如 Glow12 或 Relay6)來優化這些穩定的 靜態 trace,以執行最后一級的代碼生成。
Glow
Glow12 是 Facebook 推出的深度學習編譯器。Glow 采用 TensorFlow 或 Caffe2 等框 架生成的深度學習計算圖,然后將它渲染成用于硬件加速器的字節代碼。Glow 包括多個工 具,如用來生成用于芯片特定內存配置的指令排程器、線性代數優化器、內存分配器,以及 用來測試硬件準確率的基于 CPU 的推斷實現。
其它相關工作
基于調度語言的自動張量程序生成
Halide13 是一個開源的專門設計用于簡化圖像處理的程序語言。Halide 引入了一種可 以描述循環優化原語的調度語言。該語言適用于手動優化和自動搜索。Halide 基于不同的 技術有三種版本的自動調度器141516。最新的一種具有波束搜索和學習成本模型的版 本表現最好。 TVM4 也利用了類似的調度語言。FlexTensor17 是一個張量計算的調度 探索和優化框架,可以用于改進 TVM 的搜索算法。FlexTensor 首先定義了規整的優化空間 ,然后使用了模擬退火結合機器學習的方法去探索優化空間,找到最優的調度策略。
多面體編譯模型
多面體編譯模型將程序的優化公式化為整數線性規劃(ILP)問題。它使用仿射循環轉換來 優化程序,從而使從屬語句之間的數據重用距離最小化。Tiramisu18 和 Tensor Comprehensions19 是兩個針對深度學習領域的多面體編譯器。Tiramisu 提供的 調度語言類似于 Halide 語言,并且需要手動調度。 Tensor Comprehensions 可以自動搜 索 GPU 代碼,但尚未打算將其用于計算瓶頸區域(compute-bound)的問題。由于缺乏某些 優化和多面體公式中不準確的隱式成本模型,Tensor Comprehensions 不能在 conv2d 和 matmul 等算子上勝過 TVM。
深度學習的計算圖級別優化
計算圖級別優化將計算圖中的算子視為基本單元,并在計算圖級別執行優化,而無需更改算 子的內部實現。計算圖級別的常見優化包括布局優化20、算子融合4、常數折疊6 、自動批處理、自動生成圖替換21等。計算圖形級優化通常是對算子級優化的補充。計算 圖級別優化還可以從算子的高性能實現中受益。TensorFlow XLA10 和 DLVM22 都屬 于針對深度學習的計算圖級別的優化框架。TACO21 是第一個使用自動生成子圖替換的神 經網絡優化器。它將一系列算子操作作為輸入,生成一系列可替換的候選子圖,利用自動定 理證明來通過形式化驗證篩選,最后使用基于代價的回溯搜索法來找到最優圖。TACO 可以 自動的對于圖結構和數據布局進行聯合優化。而其他框架如 TensorFlow、PyTorch、TVM 則 是通過一系列基于規則的手寫子圖組合進行圖的優化,然后分開進行數據布局的優化。作為 一個計算圖的優化器,因為不涉及到底層代碼的生成,TACO 可以很容易的作為一個插件去 進一步提升其他框架如 TVM 的推理性能。
傳統機器學習算法的優化
傳統的機器學習算法(如決策樹、支持向量機等)仍然在各種領域中廣泛使用,它們使用的 框架各異(如 scikit-learn、xgboost、SparkML 等),這些框架通常只對于部分硬件后端 進行過推理性能的優化。如前面所述,由于神經網絡的流行,在不同硬件后端上對深度神經 網絡的推理性能優化,已經有了大量的工作。微軟推出了一個名為 Hummingbird 的系統, 可以將傳統的機器學習算法運行在深度學習推理引擎上,這樣可以利用現成的深度學習自動 編譯器來加速傳統機器學習算法在不同硬件后端上的推理性能23。目前 Hummingbird 已 經支持將 scikit-learn、 LightGBM 和 XGBoost 中的決策樹模型轉換成可以在 PyTorch、 TorchScript、 ONNX 和 TVM 上運行的模型。
小結
從近幾年的論文和開源社區的發展來看,深度學習自動編譯和優化這個方向還在蓬勃的發展 中。在開源社區中,TVM 應該是最為成功的一個,它有先發優勢,并且還在不斷的進步(最 近的改進 Ansor 在 OSDI’20 發表了)。同時,對于 TensorFlow 和 PyTorch 這樣的深度 學習框架,自動編譯和優化對于他們在邊緣端設備上的推廣是非常重要的,所以可以看到大 公司們也在這個方向上不斷發力。
墨奇科技基礎架構組專注于大規模圖像搜索系統的基礎架構和邊緣端的 AI 算法優化兩個方向。有興趣的朋友請發簡歷(校招/社招)到 talent@moqi.ai。
參考文獻
- Abadi, Martín, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. “TensorFlow : A System for Large-Scale Machine Learning.” In OSDI, 265–83, 2016. ??
- Chen, Tianqi, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. “MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems.” In LearningSys, 1–6, 2015. ??
- Paszke, Adam, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, et al. “PyTorch: An Imperative Style, High-Performance Deep Learning Library.” In NeurIPS, 2019. ??
- Chen, Tianqi, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, et al. “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning.” In OSDI, 2018. ??
- Chen, Tianqi, Lianmin Zheng, Eddie Yan, Ziheng Jiang, Thierry Moreau, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. “Learning to Optimize Tensor Programs.” In NeurIPS, 3389–3400, 2018. ??
- Roesch, Jared, Steven Lyubomirsky, Marisa Kirisame, Logan Weber, Josh Pollock, Luis Vega, Ziheng Jiang, Tianqi Chen, Thierry Moreau, and Zachary Tatlock. “Relay: A High-Level Compiler for Deep Learning.” ArXiv, 2019. ??
- Zheng, Lianmin, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, et al. “Ansor: Generating High-Performance Tensor Programs for Deep Learning.” In OSDI, 2020. ??
- Ma, Lingxiao, Zhiqiang Xie, Zhi Yang, Jilong Xue, Youshan Miao, Wei Cui, Wenxiang Hu, Fan Yang, Lintao Zhang, and Lidong Zhou. “Rammer: Enabling Holistic Deep Learning Compiler Optimizations with RTasks.” In OSDI, 881–97, 2020. ??
- Lattner, Chris, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, and Oleksandr Zinenko. “MLIR: A Compiler Infrastructure for the End of Moore’s Law.”ArXiv, 2020. ??
- XLA: Optimizing Compiler for Machine Learning | TensorFlow ??
- TorchScript ??
- Rotem, Nadav, Jordan Fix, Saleem Abdulrasool, Garret Catron, Summer Deng, Roman Dzhabarov, Nick Gibson, et al. “Glow: Graph Lowering Compiler Techniques for Neural Networks.” ArXiv, 2019. ??
- Ragan-Kelley, Jonathan, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe. “Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines.” In PLDI, 519–30, 2013. ??
- Mullapudi, Ravi Teja, Andrew Adams, Dillon Sharlet, Jonathan Ragan-Kelley, and Kayvon Fatahalian. “Automatically Scheduling Halide Image Processing Pipelines.” TOG 35, no. 4 (2016). ??
- Li, Tzu Mao, Micha?l Gharbi, Andrew Adams, Frédo Durand, and Jonathan Ragan-Kelley. “Differentiable Programming for Image Processing and Deep Learning in Halide.” TOG 37, no. 4 (2018). ??
- Adams, Andrew, Karima Ma, Luke Anderson, Riyadh Baghdadi, Tzu Mao Li, Micha?l Gharbi, Benoit Steiner, et al. “Learning to Optimize Halide with Tree Search and Random Programs.” TOG 38, no. 4 (2019). ??
- Zheng, Size, Yun Liang, Shuo Wang, Renze Chen, and Kaiwen Sheng. “FlexTensor: An Automatic Schedule Exploration and Optimization Framework for Tensor Computation on Heterogeneous System.” In ASPLOS, 859–73, 2020. ??
- Baghdadi, Riyadh, Jessica Ray, Malek Ben Romdhane, Emanuele Del Sozzo, Abdurrahman Akkas, Yunming Zhang, Patricia Suriana, Shoaib Kamil, and Saman Amarasinghe. “TIRAMISU: A Polyhedral Compiler for Expressing Fast and Portable Code.” In CGO, 2019. ??
- Vasilache, Nicolas, Oleksandr Zinenko, Theodoros Theodoridis, Priya Goyal, Zachary DeVito, William S. Moses, Sven Verdoolaege, Andrew Adams, and Albert Cohen. “Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions.” ArXiv, 2018. ??
- Liu, Yizhi, Yao Wang, Ruofei Yu, Mu Li, Vin Sharma, and Yida Wang. “Optimizing CNN Model Inference on CPUs.” In USENIX ATC, 1025–39, 2019. ??
- Jia, Zhihao, James Thomas, Todd Warszawski, and Alex Aiken. “TASO : Optimizing Deep Learning Computation with Automatic Generation of Graph Substitutions.” In SOSP, 47–62. New York: ACM, 2019. ??
- Wei, Richard, Lane Schwartz, and Vikram Adve. “DLVM: A Modern Compiler Infrastructure for Deep Learning Systems.” ArXiv, 2017. ??
- Nakandala, Supun, Karla Saur, Gyeong-In Yu, Konstantinos Karanasos, Carlo Curino, Markus Weimer, and Matteo Interlandi. “A Tensor Compiler for Unified Machine Learning Prediction Serving.” In OSDI, 2020.






)
來編譯和優化模型)








來處理算子)


