精簡CUDA教程——CUDA Driver API
tensorRT從零起步邁向高性能工業級部署(就業導向) 課程筆記,講師講的不錯,可以去看原視頻支持下。
Driver API概述
CUDA 的多級 API
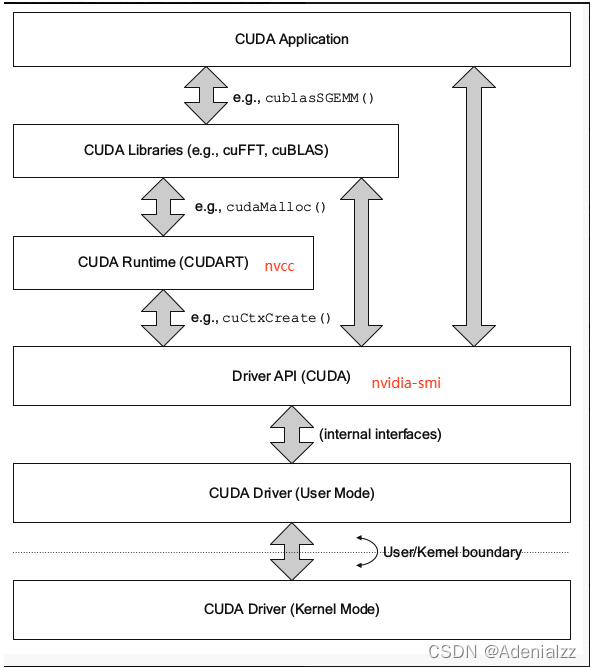
CUDA 的 API 有多級(下圖),詳細可參考:CUDA環境詳解。
- CUDA Driver API 是 CUDA 與 GPU 溝通的驅動級底層 API。早期 CUDA 與 GPU 溝通都是直接通過 Driver API。
cuCtxCreate()等cu開頭的基本都是 Driver API。我們熟悉的nvidia-smi命令就是調用的 Driver API。 - 后來發覺 Driver API 太過底層,細節太過復雜,故演變出了 Runtime API,Runtime API 是基于 Driver API 開發的,常見的
cudaMalloc()等 API 都是 Runtime API。
CUDA Driver
環境相關
CUDA Driver 是隨著顯卡驅動發布,要與 cudatoolkit 分開看。
CUDA Driver 對應于 cuda.h 和 libcuda.so 兩個文件。注意 cuda.h 會在安裝 cudatoolkit 時包含,但是 libcuda.so 是隨著顯卡驅動安裝的我們的系統中的(而不是也跟著 cudatooklit 安裝)。因此,如果要直接復制移動 libcuda.so 文件時要注意驅動版本需要與之適配。
如何了解CUDA Driver
本精簡課程對于底層的 Driver API 的理解,是為了有利于后續的 Runtime API 的學習與錯誤調試。Driver API 是理解 cudaRuntime 中上下文的關鍵。因此,本精簡課程在 CUDA Driver 這部分的主要的知識點是:
- Context 的管理機制
- CUDA 系列接口的開發習慣(錯誤檢查方法)
- 內存模型
關于context和內存的分類
關于context,有兩種:
- 手動管理的 context:
cuCtxCreate,手動管理,以堆棧的方式 push/pop - 自動管理的 context:
cuDevicePrimaryCtxRetain,自動管理,Runtime API 以此為基礎
關于內存,有兩大類:
- CPU 內存,稱之為 Host Memory
- Pageable Memory:可分頁內存
- Page-Locked Memory:頁鎖定內存
- GPU 內存(顯存),稱之為 Device Memory
- Global Memory:全局內存
- Shared Memory:共享內存
- … 其他
以上內容之后會展開介紹。
cuIint 驅動初始化
cuInit的意義是,初始化驅動 API,全局執行一次即可,如果不執行,則所有 API 都將返回錯誤。- 沒有對應的
cuDestroy,不需要釋放,程序銷毀自動釋放。
返回值檢查
版本一
正確友好地檢查 cuda 函數的返回值,有利于程序的組織結構,使得代碼的可讀性更好,錯誤更容易發現。
我們知道 cuInit 返回的類型是 CUresult,該返回值會告訴程序員函數成功還是失敗,失敗的原因是什么。
官方版本的檢查的邏輯,如下:
// 使用有參宏定義檢查cuda driver是否被正常初始化, 并定位程序出錯的文件名、行數和錯誤信息
// 宏定義中帶do...while循環可保證程序的正確性
#define checkDriver(op) \do{ \auto code = (op); \if(code != CUresult::CUDA_SUCCESS){ \const char* err_name = nullptr; \const char* err_message = nullptr; \cuGetErrorName(code, &err_name); \cuGetErrorString(code, &err_message); \printf("%s:%d %s failed. \n code = %s, message = %s\n", __FILE__, __LINE__, #op, err_name, err_message); \return -1; \} \}while(0)
是一個宏定義,我們在調用其他 API 的時候,對函數的返回值進行檢查,并在出錯時將錯誤碼和報錯信息打印出來,方便調試。比如:
checkDriver(cuDeviceGetName(device_name, sizeof(device_name), device));
如果有未初始化等錯誤,報錯信息會被清晰地打印出來。
這個版本一也是 Nvidia 官方使用的版本,但是存在一些問題,比如代碼可讀性較差,直接返回 int 型錯誤碼等。推薦使用版本二。
版本二
// 很明顯,這種代碼封裝方式,更加的便于使用
//宏定義 #define <宏名>(<參數表>) <宏體>
#define checkDriver(op) __check_cuda_driver((op), #op, __FILE__, __LINE__)bool __check_cuda_driver(CUresult code, const char* op, const char* file, int line){if(code != CUresult::CUDA_SUCCESS){ const char* err_name = nullptr; const char* err_message = nullptr; cuGetErrorName(code, &err_name); cuGetErrorString(code, &err_message); printf("%s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message); return false;}return true;
}
很明顯的,版本二的返回值、代碼可讀性、封裝性等都相較版本一好了很多。使用的方式是一樣的:
checkDriver(cuDeviceGetName(device_name, sizeof(device_name), device));
// 或加一個判斷,遇到錯誤即退出
if (!checkDriver(cuDeviceGetName(device_name, sizeof(device_name), device))) {return -1;
}
CUcontext
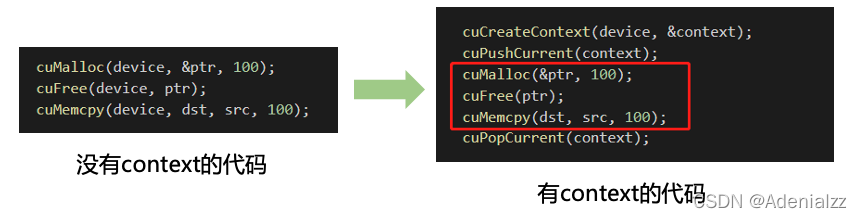
手動上下文管理
-
context 是一種上下文,關聯對 GPU 的所有操作。
-
一個 context 與一塊顯卡關聯,一塊顯卡可以被多個 context 關聯。
-
每個線程都有一個棧結構存儲 context,棧頂是當前使用的 context,對應有 push/pop 函數操作 context 的棧,所有 API 都以當前 context 為操作目標
試想一下,如果執行任何操作你都需要傳遞一個 device 決定送到哪個設備執行,得多麻煩。context 就是為了方便管理當前 API 是在哪個 device 上執行而提出的一種手段,而棧結構的使用則是為了保存之前的上下文中的 device,從而方便控制多個設備。
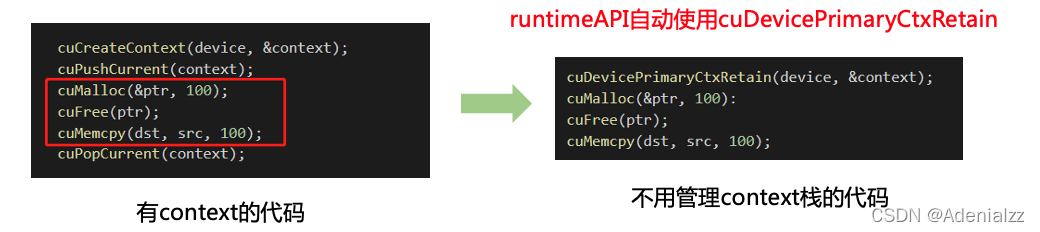
自動上下文管理
- 由于高頻操作都是一個線程固定訪問一個 device 不變,不經常會有同一個線程來回多次訪問不同 device 的情況,且只會使用到一個 context,很少用到多 context。
- 即在多數情況下,
CreateContext、PushCurrent、PopCurrent這種多 context 管理就顯得很麻煩 - 因此就推出了
cuDevicePrimaryCtxRetain,為設備關聯主 context,這樣分配、設置、釋放、棧都不需要我們再去手動管理,是一種自動管理 context 的方式 primaryContext:給我設備 id,給你 context 并設置好,此時一個 device 對應一個 primary context。不同線程,只要設備 id 相同,primary context 就相同,且 context 是線程安全的。- 在之后要介紹的 CUDA Runtime API 中,就是自動使用
cuDevicePrimaryCtxRetain的。
DriverAPI 內存管理
- host memory 是計算機本身的內存,可以用 CUDA Driver API 來申請和釋放,也可以用 C/C++ 的
malloc/free和new/delete來申請和釋放。 - device memory 是顯卡上的內存,即顯存,有專用的 Driver API 來進行申請和釋放。






)









![[深度][PyTorch] DDP系列第一篇:入門教程](http://pic.xiahunao.cn/[深度][PyTorch] DDP系列第一篇:入門教程)
![[深度][PyTorch] DDP系列第二篇:實現原理與源代碼解析](http://pic.xiahunao.cn/[深度][PyTorch] DDP系列第二篇:實現原理與源代碼解析)
![[深度][PyTorch] DDP系列第三篇:實戰與技巧](http://pic.xiahunao.cn/[深度][PyTorch] DDP系列第三篇:實戰與技巧)
