前不久,滴滴ES團隊將維護的30多個ES集群,3500多個ES節點,8PB的數據,從2.3.3跨大版本無縫升級到6.6.1。在對用戶查詢寫入基本零影響和改動的前提下,解決了ES跨大版本協議不兼容、文件格式不兼容、mapping不兼容等難題,整個過程對絕大部分用戶完全透明。同時還完成了Arius的架構升級,取得了單機查詢性能提升40%,整體集群cpu下降10%,寫入tps提升30%,集群資源使用率提升20%、0故障、運維成本下降60%的成績。
本文將系統的介紹滴滴在從2.3.3跨大版本升級到6.6.1過程中的遇到的問題和解決方案,以及在搜索平臺建設過程中的體系化思考。
01
背景介紹
1. 集群規模

目前滴滴使用的ES版本是2.3.3,集群個數有40多個,節點規模有3500+,集群總容量有8PB。
2. 業務規模

1200多個平臺應用方在使用ES,30多個核心應用在使用ES,寫入的TPS有1500W,查詢的QPS有25W。
02
問題分析
針對以上規模的ES集群,從2.3.3升級到6.X版本,小版本會根據最后分析的結果確定,需要對潛在可能的問題進行分析和區分。
1. 問題分析

主要先從四大問題域進行區分分析:
- 引擎側:由于從2.3.3升級到6.X版本,版本差距過大,在文件格式和協議上都不兼容,因此無法進行原地滾動直接升級,需要雙寫搬遷升級,這樣會耗費大量的機器去參與其中
- 用戶側:6.X版本開始逐漸的不支持TCP接口,因此需要用戶適配和升級;查詢和返回值也有一定差異,如果用戶側做適配,會極大影響升級的進度
- 資源側:由于無法直接原地滾動直接升級,需要雙寫使用大量的機器,但是無法提供升級所需要的機器,如果升級過程中資源無法得到保障,那也會極大影響升級的進度
- 操作側:新版本的多集群如何進行運維管控?升級的結果如何驗證?查詢的效率和質量如何保障和保證的?這些問題都需要考慮
2. 升級思路
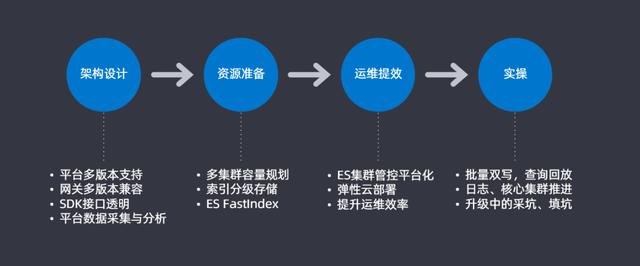
根據上一部分問題的匯總和分類,形成了一個大致的升級思路并會根據這四大步驟來解決具體的問題。
- 架構設計:平臺支持多版本支持,查詢網關上進行多版本兼容,在查詢和插入使用SDK時候要做到SDK接口的透明,最后要做一個平臺數據采集和分析用于后續做升級的分析對比
- 資源準備:進行合理的多集群容量規劃來提高資源使用率,盡可能的節省機器;設計索引分級存儲來提升資源的利用率;還針對大索引遷移開發了一個插件FastIndex也用來提升資源利用率
- 運維績效:開發ES集群管控平臺,將ES集群管控平臺化和圖表化;通過Docker的方式來提升部署和運維的效率
- 實操:在實際操作中,需要實現批量雙寫以及查詢回放的功能;需要對業務進行區分,實現日志和核心集群的分步推進;最后就是升級過程中會遇到一些坑,需要把坑都填滿,后續會詳細介紹一下這些坑
3. 升級方案

上面是升級思路,接下來介紹一下升級方案:
- 架構:ES多版本支持的架構改造,同時支持2.3.3以及6.X版本;開發一套多集群管控平臺,用于滴滴內部ES多個集群的管控;同時還開發了一套ES服務元數據體系建設
- 資源:設計ES分級存儲體系;開發ES-FastIndex離線數據導入的插件;最后構建了一套ES集群容量規劃方案來提升集群的資源使用率,節約資源成本
- 實操:通過ES多集群搭建、ES流量回放對比系統、ES版本升級采坑分享來完成升級和對比的一個過程
03
方案介紹
1. 架構
① 架構重構
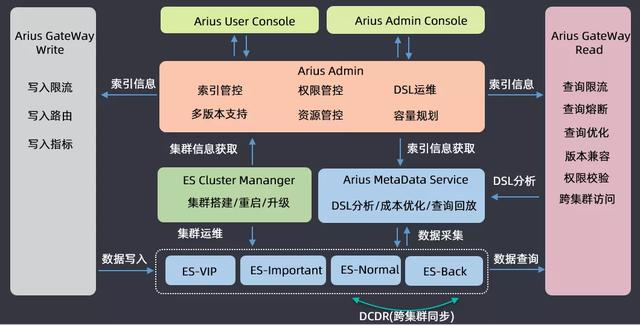
介紹一下滴滴搜索平臺(Arius)的架構,業務方使用ES搜索進行讀寫請求時都會經過網關;運維的時候會根據集群的重要程度進行劃分,會將四十多個集群劃分為VIP、Important、Normal、Backup四類,開發了一個DCDR工具用于跨集群的數據同步;在ES集群運維之上開發了三大組件,一個是ES Cluster Manager,用于集群的搭建、重啟和升級混合操作的平臺;第二個是集群ES的數據分析構建了一個Arius Metadata Service的元數據管理服務,用于做DSL分析、成本優化和查詢回放;在這兩個系統之上有一套Arius Admin管控系統,包含索引管控、權限管控、DSL運維、多版本支持、資源管控以及容量規劃等功能;基于Arius Admin,構建了兩套面向運維和用戶的管控平臺前端工程。
以上就是滴滴搜索平臺的整體架構,然后基于此來做ES的版本升級。
② 升級流程

上圖為升級的流程,首先是要升級對ES集群的管控,要支持2.3.3和6.6.1兩個版本;對每個要升級的索引要進行主備索引的創建,創建完畢后通過雙寫的形式對主和備都同時寫入到新的索引中,對于歷史索引采取的是這樣一個策略:在雙寫之前,主備創建之后,會暫停歷史數據的寫入,把歷史數據通過migration的方式從低版本遷移到高版本中,遷移完后再進行雙寫;在遷移完成,雙寫鏈路打開之后,做一個DSL數據回放,由于用戶的讀寫都是通過gateway進行的,所以可以拿到用戶的DSL語句和返回數據來進行一個高低版本的查詢、對比和分析,如果最后比對結果是數據一致、性能也一致,那就認為該索引在高低版本中遷移是成功的。如果遷移成功,會在網關層完成用戶查詢的向高版本的切換,如果切換完成后,業務方運行沒有問題就會將低版本的索引下線掉,最終就完成了索引由低版本向高版本升級的過程。
③ GateWay兼容性
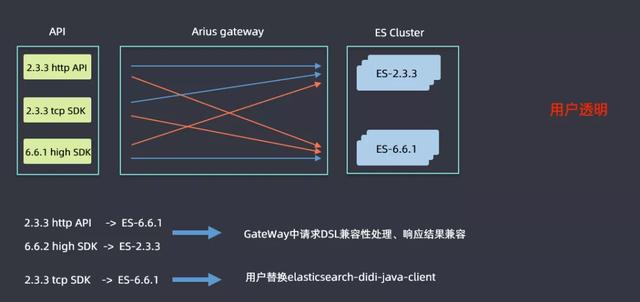
升級是一個比較漫長的過程,高低版本集群會并行運行一段時間,用戶使用的SDK也會高低版本共存,這樣就需要解決高低版本兼容性的問題。查詢可能會分為上圖六條線標識的六種情況,藍色線表明不需要進行改造直接進行查詢的,2.3.3的http和tcp sdk查詢2.3.3ES集群,6.6.1 high sdk查詢6.6.1的ES集群都是沒有問題的;紅色線表明是需要考慮兼容性問題進行改造的,例如2.3.3的sdk查詢6.6.1的ES集群時候語法的差異性問題等,然后ES高版本中會逐漸取消掉tcp的查詢接口,但是滴滴內部還是有很多用戶是使用tcp方式查詢的,如果需要用戶進行代碼改造的話流程會非常漫長,因此在Gateway層面做了一些兼容性處理:在2.3.3http api和6.6.1 high sdk查詢6.6.1集群和2.3.3集群時候,做了請求DSL的兼容性處理和響應結果兼容,解決了用戶的痛點;對于使用tcp方式查詢的用戶,開發了一個elasticsearch-didi-java-client的sdk,用戶替換一下pom即可,表面上還是使用tcp的方式,但是在網關層面已經將其轉換為了http查詢的方式。這樣就做到了用戶透明。
④ ES集群管控平臺
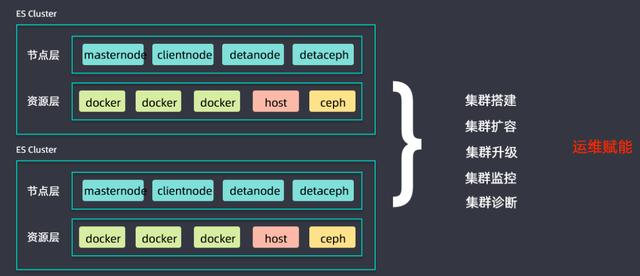
同時搭建了一套ES集群管控平臺,用于進行集群搭建、集群擴容、集群升級、集群監控以及集群診斷等工作,為升級過程中的運維賦能,提升升級推進進度。
⑤ 元數據服務
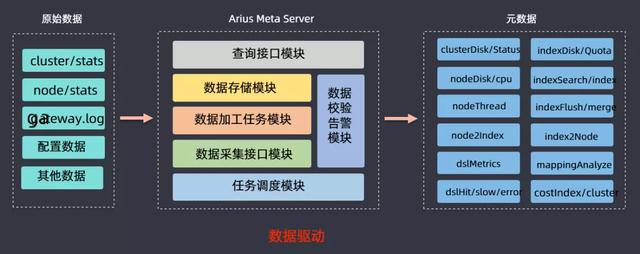
前面介紹的時候有講到元數據服務,該模塊的作用就是提供一個ES集群和業務方的數據的分析,然后獲取cluster/stats、node/stats、日志、監控數據等信息進行分析,最后可以得到節點磁盤使用狀況、DSL查詢情況(慢查、錯誤查詢),基于此來做容量規劃、分級存儲、查詢回放等數據驅動型工作。
⑥ DSL服務
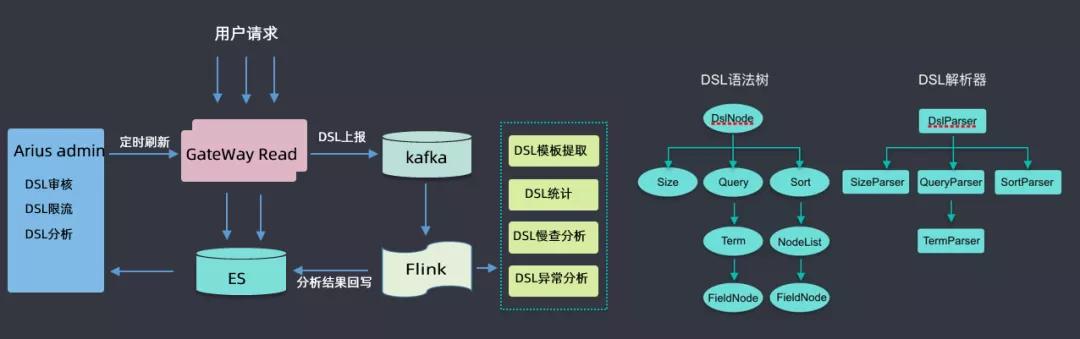
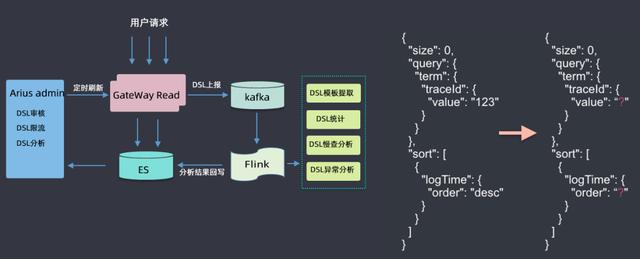
此處著重介紹一下DSL服務,用戶所有請求都會通過網關,經過網關時會收集到kafka,然后用flink做一些分析,如DSL模板提取(具體查詢參數去掉,抽象為模板)、DSL統計、DSL慢查分析、DSL異常分析等,然后將分析結果回寫到ES集群中;然后根據這些分析的數據來做DSL審核(用戶可能會查詢滴滴的核心索引,此處需要審核才能查詢)、DSL限流(有的DSL里面會有大量的聚合查詢,此處會進行一定限流)、DSL分析(首先會對DSL語句進行語法樹的解析,解析后會生成一個無參的查詢模板)等。
2. 資源
① 容量規劃
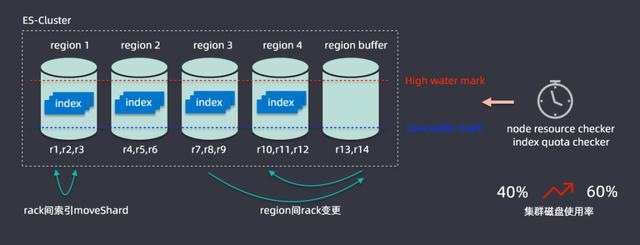
接下來將一些如何在升級過程中解決資源問題,為此開發了一個容量規劃的算法,ES缺乏一個多節點之間索引均勻分布的功能;在滴滴內部最大的集群是在兩百多個節點,承載容量在PB級別,索引有上千個,在寫入索引時候可能流量分布式不均勻的,很有可能有索引節點的熱點存在。
解決思路為將兩百多個節點進行劃分為五個region,一個region都會有很多節點組成,如r1、r2、r3組成,劃分之后就可以計算每個region中節點磁盤的使用情況,設置一個高水位線和低水位線,通過分析每個region的數據情況,region超過高水位就會通過rack變更進行擴容,region內部會監控不同節點的使用情況,通過rack建索引mockShard進行均衡,從而整體提升資源利用率,通過該算法后集群磁盤的使用率從百分之四十提升到百分之六十,這樣就節省了大量的資源。
② 分級存儲
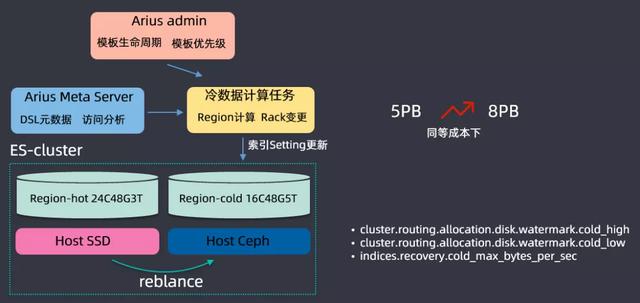
基于用戶查詢和保存的操作進行一個數據分析,開發了一個ES分級存儲的體系,搭建ES集群時候主要基于兩種磁盤進行搭建的,一種是SSD磁盤,另一種是Ceph(可以理解為HDD磁盤組成的網絡磁盤);SSD磁盤非常貴,但是查詢性能特別好,會存儲一些查詢頻繁的數據,Ceph磁盤比較便宜,但是查詢IO性能比較低,存儲查詢不是那么頻繁的數據;根據用戶查詢的頻率,將數據區分為冷數據和熱數據,根絕查詢的DSL來分析索引的保留期限,在滴滴內部基本上索引都是按天保存的(舉個例子:日志都是按天建索引保存的),三天之內的放到SSD上保存,三天之前的數據會放到Ceph上存儲,這樣可以大量存儲的成本,同等成本情況下,把集群存儲容量從5PB提升到了8PB。
在分級存儲之上,還開發了一些特性,專門開發了high level和low level的水位線,這是基于冷存和熱存系統消耗是不一樣的,冷存的時候high level可能會更高一點,以上就是分級存儲的內容。
③ FastIndex
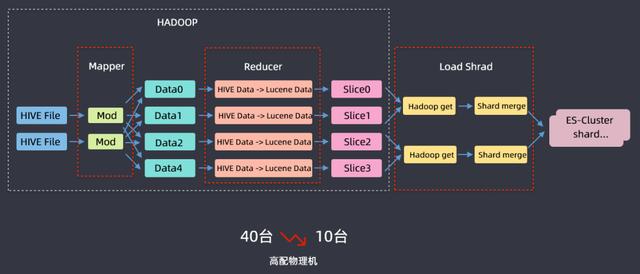
另外還為離線數據導入ES開發了一個FastIIndex的組件,該組件開發主要是基于滴滴內部用于分析乘客的標簽系統,從離線系統導入ES集群而開發的;標簽系統每天都會重新計算,數據總量在40TB左右,原始數據在hadoop上,計算好之后通過kafka然后實時鏈路寫入到ES,以前把40TB數據導入到ES需要40臺高配物理機,基于這樣一個案例開發了FastIndex組件,利用hive進行一個mapreduce的過程,在reduce階段使用FastIndex組件啟用ES local這樣的模式將數據寫到lucene data中,然后再把lucene文件加載到ES集群中,這樣就完成了把離線數據導入ES集群的操作,資源從40臺下降到10臺高配物理機,時間也從6小時下降到1.5小時,節省了大量的成本。
3. 升級
① 查詢回放
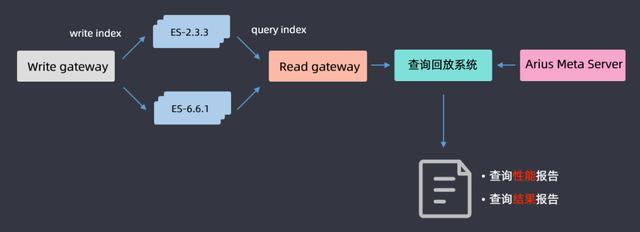
機器資源優化好了之后,開始升級,升級過程前面有講過了,這里主要介紹一下查詢回放流程,因為要保證升級后對用戶的查詢是沒有影響的;基于gateway網關層DSL的分析,將用戶查詢的DSL全部在高低版本上進行一個回放,最后得出一份查詢性能報告和查詢結果報告,通過分析兩篇報告,如果是一致的就認為升級完成;如果不一致,就分析2.3.3和6.6.1哪些查詢導致的問題,然后做兼容性適配,適配完成后再進行查詢回放,循環往復直至最后所有的報告都一致,這樣就認為ES集群升級成功。
② 采坑
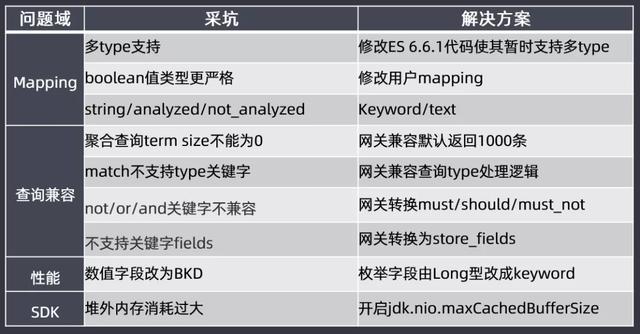
接下來介紹一下升級過程中遇到的坑:
- Mapping:選擇6.6.1的理由是代碼里面暫時還是支持多type的;還有就是布爾類型數據的兼容,分詞不分詞的mapping修改,這些內容都會提前幫助用戶修改好mapping。
- 查詢兼容:聚合查詢term size不能為0,網關兼容默認返回1000條;match不支持type關鍵字,網關兼容查詢type處理邏輯;not/or/and關鍵字不兼容,網關轉換must/should/must_not;不支持關鍵字fields,網關轉換為store_fields
- 性能:數值字段改為BKD,枚舉字段會從Long類型改為keyword類型;否則long類型在BKD查詢時候還有問題的
- SDK:使用高版本ES會有堆外內存消耗過大的問題,需要開啟jdk,nio.maxCachedBudderSize參數來保障堆外內存不會消耗過大。
04
升級收益
1. 平臺升級
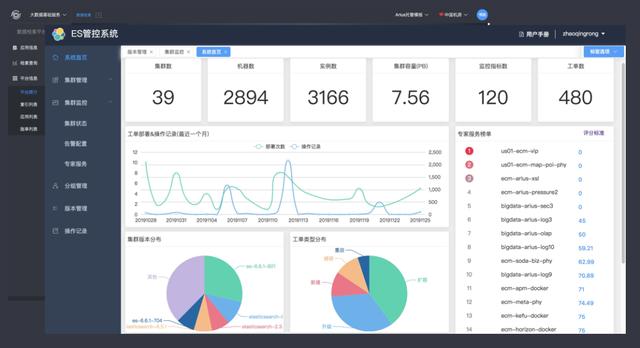
構建了一個完善的管控的平臺,大大降低了使用成本。
2. 成本下降
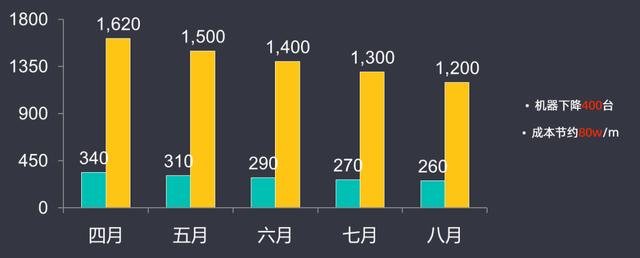
機器數量下降了400臺,每月成本節約了80萬左右。
3. 性能提升
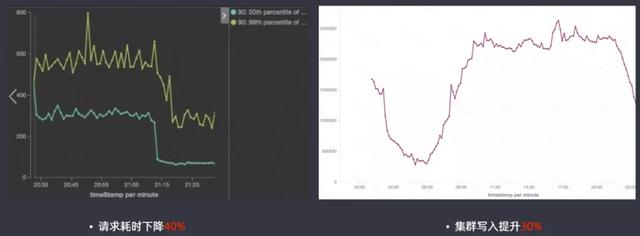
高版本的ES查詢性能提升還是很明顯的,請求耗時下降40%,集群寫入提升30%。
4. 特性應用
使用了高版本特性帶來的一些優勢:
- Sequence Number提升了集群升級速度
- Ingest Node索引模板和限流從網關層下放到引擎層
- DCDR滴滴跨集群數據同步,相比CCR性能提升2倍
- Cluster reroute冷熱節點shard搬遷更均勻
- Cluster allocation explain降低集群狀態運維成本
05
總結與展望
1. 總結

針對搜索平臺進行大版本的升級時,一定要做到:
- 架構要可控:服務化(網關服務、管控服務、元數據服務、FastIndex服務)、高內聚、一定優先保證穩定性
- 平臺要易用:平臺化、自動化、可視化
- 成本要低廉:數據驅動、技術改造、業務配合
- 引擎要深入:深入理解版本差異、深入理解ES原理、深入定位問題根因
2. 規劃

最后對滴滴搜索平臺做一個整體的規劃:
- 更大的集群:在滴滴現有的目前40多個集群的規模下,做得更大,由于master元數據管理的限制導致對集群的管控是無法做到非常大的,目前滴滴希望做到單集群支持50萬下載、1500節點的支撐;同時需要做好多租戶能力的支持
- 更易用的平臺:ES云平臺建設、ES專家服務
- 更強的引擎:CBO/RBO查詢優化、提升寫入性能
- 更多的貢獻:加強和開源社區的互動、深入引擎開發
作者:趙情融 滴滴出行專家工程師,負責滴滴搜索平臺建設工作,曾在阿里工作多年,有豐富平臺建設經驗。

)

















