文章目錄
- 前言
- 一、工行業務背景
- 1.1、工行云計算架構組成
- 1.2、工行云平臺技術棧
- 1.3、工行金融云成效
- 1.3.1、入云規模同業最大
- 1.3.2、業務如云場景廣
- 1.4、容災及高可用保障
- 1.5、PaaS 層多集群現狀
- 1.5.1、集群種類多
- 1.5.2、k8s 集群 node 數量限制
- 1.5.3、業務擴展快
- 1.5.4、故障域分區多
- 1.6、針對多集群現狀的解決方案
- 1.7、解決方案下存在的問題
- 二、架構選型
- 2.1、實現目標
- 2.2、為什么希望部分模塊是具有社區支持度的開源項目?
- 2.3、Kubefed 的優勢與不足
- 2.4、RHACM 的優勢與不足
- 2.5、Karmada 現真身
- 三、為什么選擇 Karmada?
- 3.1、技術架構.
- 3.2、技術優勢
- 3.3、Karmada Resources 如何分發?
- 3.4、Propagation 機制
- 3.5、Work 機制
- 3.6、Karmada 優勢
- 3.6.1、資源調度
- 3.6.2、容災
- 3.6.3、集群管理
- 3.6.4、資源管理
- 四、落地展望
- 4.1、云平臺集成
- 4.2、跨集群調度
- 4.3、跨集群伸縮
- 4.4、跨集群故障恢復與高可用
- 總結
前言
華為云 AI 主打智慧園區、智慧物流兩個行業數字化轉型的解決方案。AI 開發的難點較多,在未接觸 ModelArts 之前,首先在數據的預處理方面,標注會花費大量的時間;在訓練的時候需要購置很多的 GPU 的一些設備,這是價值不菲的;在部署方面非常的困難、繁瑣。近年來隨著云原生技術的不斷成熟,越來越多的企業選擇云原生作為數字化轉型的核心支撐,華為云率先提出云原生 2.0 的理念,將引領企業云化建設從“On Cloud”邁向“In Cloud”,進入智能升級新階段。
一、工行業務背景
近幾年互聯網的崛起對金融領域的金融模式、服務模式產生了巨大的沖擊,迫使行業不得不做出巨大的革新。銀行業務系統“入云”已經是大勢所趨,在這方面工商銀行已經處于行業一線,截止目前已經形成了基礎設施云(Iaas)、應用平臺云(Paas)、金融生態云(SaaS)以及具有工行特色的分行云(BCloud)四位一體的云平臺架構。
1.1、工行云計算架構組成
工行云平臺具體架構如下圖所示:

以上四大模塊各自分發所負責的內容如下:
- 基礎設施云(IaaS):面向基礎設施運維人員,提供計算、存儲、網絡等底層資源快速供給的能力。
- 應用平臺云(PaaS):面向應用運維人員,提供軟件資源(環境、中間件和應用程序)快速供給及快速部署的能力。
- 金融生態云(SaaS):面向企業客戶,聯合合作伙伴,提供與工行金融服務緊密集成的行業解決方案,同時為合作伙伴提供 SaaS 軟件托管及運營管理服務。
- 分行云(BCloud):面向工行的“公有云”,提供分行應用軟件托管、DevOps、運維管理能力并輸出總行新的一些云計算建設成果。
1.2、工行云平臺技術棧
工行云平臺基于業界領先云產品和開源主流技術,結合工行特色實現金融級自主定制,技術棧如下圖所示:

- 基于華為云 Stark 8.0 產品結合運營運維需求進行客戶化定制,構建新一代基礎設施云。
- 通過引入開源容器技術 Docker、容器集群調度技術 Kubernetes 等,自主研發建設應用平臺云。
- 基于 HaProxy、Dubbo、ElasticSerch 等建立負載均衡、微服務、全息監控、日志中心等周邊配套云生態。
1.3、工行金融云成效
1.3.1、入云規模同業最大
應用平臺云容器規模超 20w,業務容器規模 55000+,核心應用基本全面入容器云,入云情況如下圖所示:

1.3.2、業務如云場景廣
應用入云涉及業務廣,并支撐多個關鍵領域,如以個人金融、線上渠道為代表的核心業務應用;以分布式服務框架、MySQL 數據庫為代表的技術支撐應用;以物聯網、區塊鏈、機器學習、大數據為代表的新技術領域應用,綜合情況如下圖所示:

1.4、容災及高可用保障
- 云平臺支持多層次故障保護機制,確保同一業務的不同實例會均衡分發到兩地三中心的不同資源域,在低粒度下細分故障域,確保單個存儲、單個集群甚至單個數據中心發生故障時,不會影響業務的整體可用性,調度情況如下圖所示:

- 在故障情況下,基于 k8s 自身優勢,云平臺通過容器重啟及自動漂移,實現故障的自動恢復,如下圖所示:

1.5、PaaS 層多集群現狀
k8s 集群總數近百個,并且在不斷地擴張中,細究主要原因我們將其分為以下四點。
1.5.1、集群種類多
由于業務場景較為廣泛,支持 GPU 的設備、中間件、數據庫、底層的容器網絡,不同的需求導致產生不同的解決方案,所以需要為不同的業務場景定制不同的集群,如下圖所示:

1.5.2、k8s 集群 node 數量限制
受到 k8s 本身性能的限制,每個集群都有自己數量的上限。
1.5.3、業務擴展快
截至目前,包括傳統應用在內的各個業務在源源不斷地切入到容器云內。
1.5.4、故障域分區多
以上述 1.4 內容為例,兩地三中心的設計,包括三個 DC,每個 DC 內部又通過不同的網絡區域防火墻進行隔離,以實現故障域分發,如下圖所示:

1.6、針對多集群現狀的解決方案

- 容器云云管平臺超級管理員接納、運維多集群。
- 上層業務應用自主選擇集群,包括網絡區域在內的等等內容。
- 集群內同一模版故障域自動打散。
1.7、解決方案下存在的問題
- 無跨集群自動伸縮。上了容器云之后,在業務峰值時集群內部缺乏自動伸縮能力。
- 無跨集群調度能力。
- 集群對上層用戶不透明。
- 無跨集群故障自動遷移能力,整體上依靠“兩地三中心”架構上的冗余,在自動化恢復上的高可用能力存在缺失。
二、架構選型
2.1、實現目標
基于以上存在的問題,我們定下了相應的目標,并對目前業界所采用的方案進行了技術選型,五個多云的集群模塊目標如下表所示:

2.2、為什么希望部分模塊是具有社區支持度的開源項目?
- 希望整體的方案是在企業內部自主可控的。
- 不希望花費更多的能力去重復“造輪子”。
- 希望整體管理的多集群模塊是從云管平臺中隔離出來,下沉到下面的多集群管理模塊之中。
基于以上的目標,社區做了相當多的調研,包括但不局限于社區中眾多的項目。
2.3、Kubefed 的優勢與不足
優勢:本身可以解決部分問題,具有集群生命周期管理,具有部分 Override,以及一些基礎調度的能力,其能力如下圖所示:

不足:調度層面太過于基礎,且 Kubefed 負責的社區團隊不準備在調度方面下更大的精力以支持如自定義的調度,包括不支持按資源余量的調度;最為人所詬病的一點——本身不支持原生 k8s 對象,需要在管理集群中使用其所新定義的一些 CRD,對于已經使用了很久原生 k8s 資源對象的上層應用,包括云管平臺在內對接的一些 API 則需要進行重新開發,而這部分的成本是非常巨大的;整體上不具備故障自動遷移能力。基于以上不足,綜合考量,Kubefed 我們暫不考慮。
2.4、RHACM 的優勢與不足
RHACM 是紅帽與 IBM 主導的項目,其功能架構如下圖所示:

- 功能比較健全,但僅支持 Openshift,對于存量大量 k8s 集群的現狀而言,改造的成本是巨大的。
- 暫未開源,社區支持力度不夠。
2.5、Karmada 現真身
Karmada 整體的功能視圖如下圖所示:
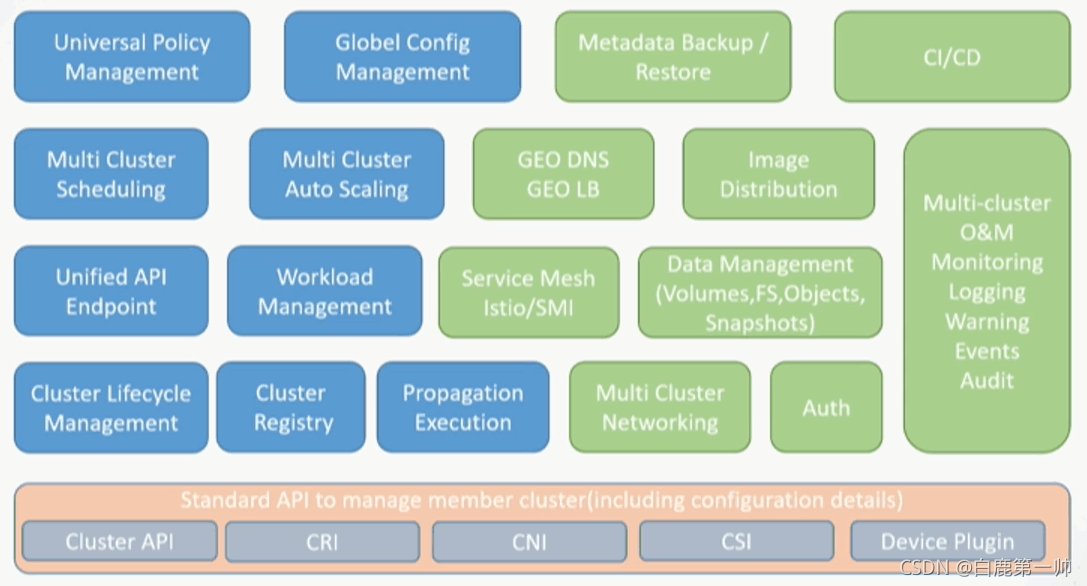
Karmada 相當契合我們在上述 2.1 小節中的實現目標要求,具有整體的集群生命周期管理、集群注冊,包括多集群的伸縮、調度、統一的 API、底層的標準 API 支持,并且 CNI、CSI 在其整體的功能視圖中,對 CI/CD 有整體上的規劃與考慮,所以工行最終決定投入到該項目中,與華為在內的一系列伙伴共建該項目并回饋到社區中。
三、為什么選擇 Karmada?
3.1、技術架構.
Karmada 目前經在社區中開源,相關信息及技術架構大家可以移步社區查看,主要架構如下圖所示:

3.2、技術優勢
- Karmada 以類 k8s 的形式部署,以作為管理面集群,改造成本較低。
- Karmada-Controller-Manager 管理包括 cluster、policy、binding、works 等多種 CRD 資源作為管理端資源對象,沒有侵入到原生的 k8s 資源對象。
- Karmada 僅管理資源在集群間的調度,子集群內分配高度自治,這對于分布式系統是必須的。
3.3、Karmada Resources 如何分發?
Karmada Resources 分發流程示意圖如下圖所示:
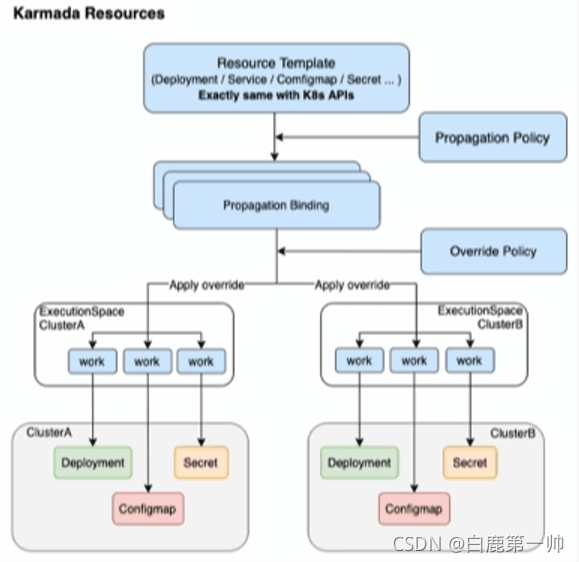
Karmada Resources 分發流程如下:
- 集群注冊到 Karmada。
- 定義 Resource Template。
- 制定分發策略 Propagation Policy。
- 制定 Override 策略。
- 看 Karmada 干活。
3.4、Propagation 機制
Propagation 機制分發如下:

Propagation Policy 信息配置如下圖所示:

- 集群親和性。
- 集群容忍。
- 按集群標簽、故障域分發。
Resource Binding/Cluster Resource Binding 信息配置如下圖所示:

- 支持 cluster\namespace scope。
3.5、Work 機制
具體的 Work 分發機制如下圖所示:

Work 信息配置如下圖所示:

- Works 僅是 k8s Resource 的封裝。
- Works 的 status 作為子集群 resource 的反饋。
3.6、Karmada 優勢
經過驗證我們將 Karmada 的優勢分為以下四塊。
3.6.1、資源調度
- 自定義跨集群調度策略。
- 對上層應用透明。
- 支持兩種資源綁定調度。
3.6.2、容災
- 動態 binding 調整。
- 按照集群標簽或故障域自動分發資源對象。
3.6.3、集群管理
- 支持集群注冊。
- 全生命周期管理。
- 統一標準的 API。
3.6.4、資源管理
- 支持 k8s 原生對象。
- works 支持子集群資源部署狀態獲取。
- 資源對象分發既支持 pull 也支持 push 方式。
四、落地展望
4.1、云平臺集成
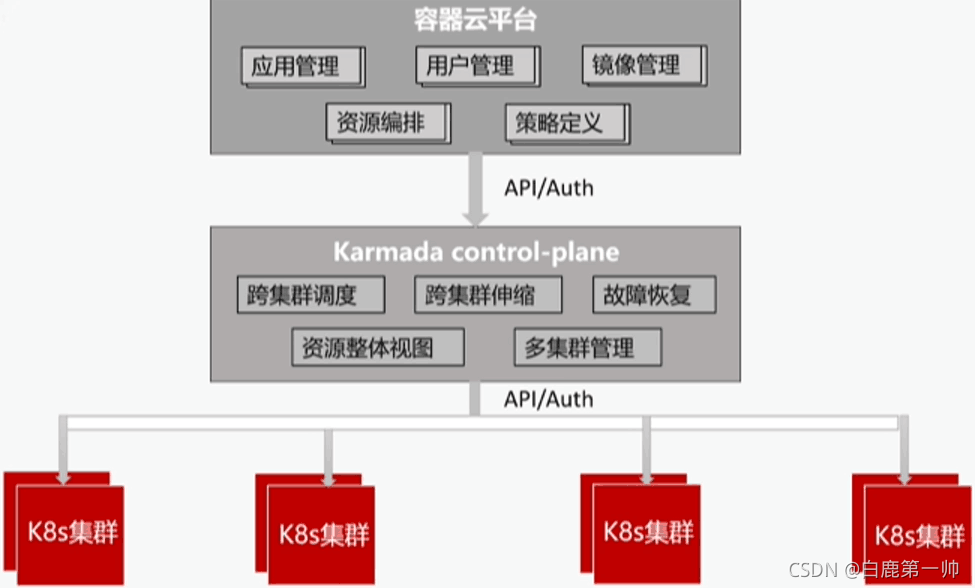
目前為止,在工行的測試環境中,Karmada 已經對現存集群進行了納管,存在的問題是如何與整體云平臺進行集成。
4.2、跨集群調度
- 故障域打散。
- 應用偏好設置、權重。
- 集群資源余量調度。
我們最終的期望實現效果如下圖所示:

4.3、跨集群伸縮

- 跨集群伸縮與子集群伸縮之間的關系。
- 跨集群伸縮與跨集群調度間的關系。
4.4、跨集群故障恢復與高可用
- 子集群健康狀態的判斷策略。可能只是與管理集群失聯,子集群本身業務容器均無損。
- 自定義的故障恢復策略。Like RestartPolicy、Always、Never、OnFailure。
- 重新調度和跨集群伸縮的關系。
總結
本文介紹了工行云平臺的現狀,包括容災和多 k8s 集群,調研了業界多集群管理方案及選型,從而確定選擇 Karmada,介紹了包括其優勢、技術架構以及具體的機制,最后介紹了 Karmada 在工行的落地情況以及在未來中希望產生和應用的場景。從 Karmada 近日宣布開源之后,我們希望有越來越多的開發者加入到社區中,共建多云管理的社區生態。
我是白鹿,一個不懈奮斗的程序猿。望本文能對你有所裨益,歡迎大家的一鍵三連!若有其他問題、建議或者補充可以留言在文章下方,感謝大家的支持!


















類的設計與應用分析)
