點擊上方“CVer”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
為了優化進化算法在神經網絡結構搜索時候選網絡訓練過長的問題,參考ENAS和NSGA-III,論文提出連續進化結構搜索方法(continuous evolution architecture search, CARS),最大化利用學習到的知識,如上一輪進化的結構和參數。首先構造用于參數共享的超網,從超網中產生子網,然后使用None-dominated排序策略來選擇不同大小的優秀網絡,整體耗時僅需要0.5 GPU day
論文: CARS: Continuous Evolution for Efficient Neural Architecture Search

- 論文地址:https://arxiv.org/abs/1909.04977
Introduction
? 目前神經網絡結構搜索的網絡性能已經超越了人類設計的網絡,搜索方法大致可以分為強化學習、進化算法以及梯度三種,有研究表明進化算法能比強化學習搜索到更好的模型,但其搜索耗時較多,主要在于對個體的訓練驗證環節費事。可以借鑒ENSA的權重共享策略進行驗證加速,但如果直接應用于進化算法,超網會受到較差的搜索結構的影響,因此需要修改目前神經網絡搜索算法中用到的進化算法。為了最大化上一次進化過程學習到的知識的價值,論文提出了連續進化結構搜索方法(continuous evolution architecture search, CARS)
? 首先初始化一個有大量cells和blocks的超網(supernet),超網通過幾個基準操作(交叉、變異等)產生進化算法中的個體(子網),使用Non-dominated 排序策略來選取幾個不同大小和準確率的優秀模型,然后訓練子網并更新子網對應的超網中的cells,在下一輪的進化過程會繼續基于更新后的超網以及non-dominated排序的解集進行。另外,論文提出一個保護機制來避免小模型陷阱問題
Approach
? 論文使用基因算法(GA)來進行結構進化,GA能提供很大的搜索空間,對于結構集,為種群大小。在結構優化階段,種群內的結構根據論文提出的pNSGA-III方法逐步更新。為了加速,使用一個超網用來為不同的結構共享權重,能夠極大地降低個體訓練的計算量
Supernet of CARS
? 從超網中采樣不同的網絡,每個網絡可以表示為浮點參數集合以及二值連接參數集合,其中0值表示網絡不包含此連接,1值則表示使用該連接,即每個網絡可表示為對
? 完整的浮點參數集合是在網絡集合中共享,如果這些網絡結構是固定的,最優的可通過標準反向傳播進行優化,優化的參數適用于所有網絡以提高識別性能。在參數收斂后,通過基因算法優化二值連接,參數優化階段和結構優化階段是CARS的主要核心
Parameter Optimization
? 參數為網絡中的所有參數,參數,為mask操作,只保留對應位置的參數。對于輸入,網絡的結果為,為-th個網絡,為其參數
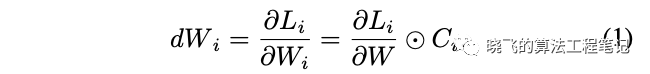
? 給定GT?,預測的損失為,則的梯度計算如公式1
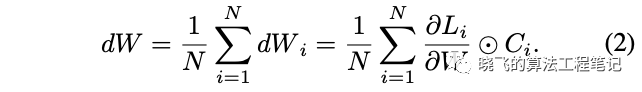
? 由于參數應該適用于所有個體,因此使用所有個體的梯度來計算的梯度,計算如公式2,最終配合SGD進行更新
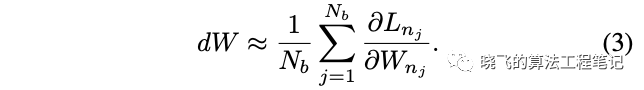
? 由于已經得到大量帶超網共享參數的結構,每次都集合所有網絡梯度進行更新會相當耗時,可以借鑒SGD的思想進行min-batch更新。使用個不同的網絡進行參數更新,編號為。計算如公式3,使用小批量網絡來接近所有網絡的梯度,能夠極大地減少優化時間,做到效果和性能間的平衡
Architecture Optimization
? 對于結構的優化過程,使用NSGA-III算法的non-dominated排序策略進行。標記為個不同的網絡,為希望優化的個指標,一般這些指標都是有沖突的,例如參數量、浮點運算量、推理時延和準確率,導致同時優化這些指標會比較難

? 首先定義支配(dominate)的概念,假設網絡的準確率大于等于網絡,并且有一個其它指標優于網絡,則稱網絡支配網絡,在進化過程網絡可被網絡代替。利用這個方法,可以在種群中挑選到一系列優秀的結構,然后使用這些網絡來優化超網對應部分的參數
? 盡管non-dominated排序能幫助選擇的更好網絡,但搜索過程仍可能會存在小模型陷阱現象。由于超網的參數仍在訓練,所以當前輪次的模型不一定為其最優表現,如果存在一些參數少的小模型但有比較高的準確率,則會統治了整個搜索過程。因此,論文基于NSGA-III提出pNSGA-III,加入準確率提升速度作為考慮
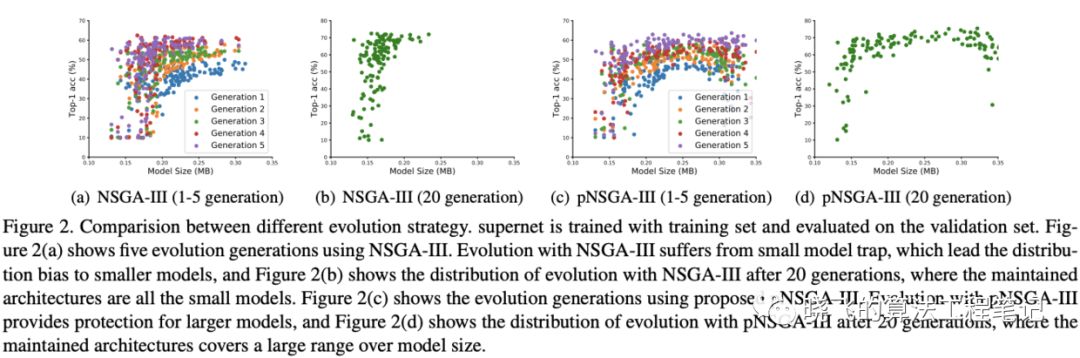
? 假設優化目標為模型參數和準確率,對于NSGA-III,會根據兩個不同的指標進行non-dominated排序,然后根據帕累托圖進行選擇。而對于pNSGA-III,額外添加考慮準確率的增長速度的non-dominated排序,最后結合兩種排序進行選擇。這樣,準確率增長較慢的大模型也能得到保留。如圖2所示,pNSGA-III很明顯保留的模型大小更廣,且準確率與NSGA-III相當
Continuous Evolution for CARS

? CARS算法的優化包含兩個步驟,分別是網絡結構優化和參數優化,另外,在初期也會使用參數warmup
- Parameter Warmup,由于超網的共享權重是隨機初始化的,如果結構集合也是隨機初始化,那么出現最多的block的訓練次數會多于其它block。因此,使用均分抽樣策略來初始化超網的參數,公平地覆蓋所有可能的網絡,每條路徑都有平等地出現概率,每種層操作也是平等概率,在最初幾輪使用這種策略來初始化超網的權重
- Architecture Optimization,在完成超網初始化后,隨機采樣個不同的結構作為父代,為超參數,后面pNSGA-III的篩選也使用。在進化過程中生成個子代,是用于控制子代數的超參,最后使用pNSGA-III從中選取個網絡用于參數更新
- Parameter Optimization,給予網絡結構合集,使用公式3進行小批量梯度更新
Search Time Analysis
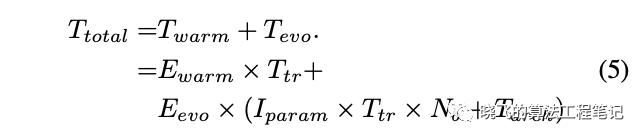
? CARS搜索時,將數據集分為數據集和驗證集,假設單個網絡的訓練耗時為,驗證耗時,warmup共周期,共需要時間來初始化超網的參數。假設進化共輪,每輪參數優化階段對超網訓練周期,所以每輪進化的參數優化耗時,為mini-batch大小。結構優化階段,所有個體是并行的,所以搜索耗時為。CARS的總耗時如公式5
Experiments
Experimental Settings
supernet Backbones
? 超網主干基于DARTS的設置,DARTS搜索空間包含8個不同的操作,包含4種卷積、2種池化、skip連接和無連接,搜索normal cell和reduction cell,分別用于特征提取以及下采樣,搜索結束后,根據預設將cell堆疊起來
Evolution Details
? 在DARTS中,每個中間節點與之前的兩個節點連接,因此每個節點有其獨立的搜索空間,而交叉和變異在搜索空間相對應的節點中進行,占總數的比例均為0.25,其余0.5為隨機生成的新結構。對于交叉操作,每個節點有0.5的概率交叉其連接,而對于變異,每個節點有0.5的概率隨機賦予新操作
Experiments on CIFAR-10
Small Model Trap
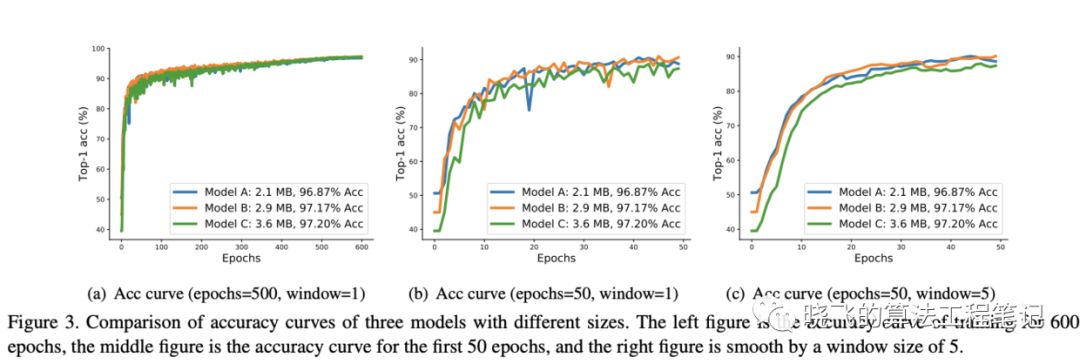
? 圖3訓練了3個不同大小的模型,在訓練600輪后,模型的準確率與其大小相關,從前50輪的曲線可以看出小模型陷阱的原因:
- 小模型準確率上升速度較快
- 小模型準確率的波動較大
? 在前50輪模型C一直處于下風,若使用NSGA算法,模型C會直接去掉了,這是需要使用pNSGA-III的第一個原因。對于模型B和C,準確率增長類似,但由于訓練導致準確率波動,一旦模型A的準確率高于B,B就會被去掉,這是需要使用pNSGA-III的第二個原因
NSGA-III vs. pNSGA-III
? 如圖2所示,使用pNSGA-III能避免小模型陷阱,保留較大的有潛力的網絡
Search on CIFAR-10
? 將CIFAR分為25000張訓練圖和25000張測試圖,共搜索500輪,參數warmup共50輪,之后初始化包含128個不同網絡的種群,然后使用pNSGA-III逐漸進化,參數優化階段每輪進化訓練10周期,結構優化階段根據pNSGA-III使用測試集進行結構更新
Search Time analysis
? 對于考量模型大小和準確率的實驗,訓練時間為1分鐘,測試時間為5秒,warmup階段共50輪,大約耗費1小時。而連續進化算法共輪,對于每輪結構優化階段,并行測試時間為,對于每輪的參數優化階段,設定,大約為10分鐘,大約為9小時,所以為0.4 GPU day,考慮結構優化同時要計算時延,最終時間大約為0.5 GPU day
Evaluate on CIFAR-10
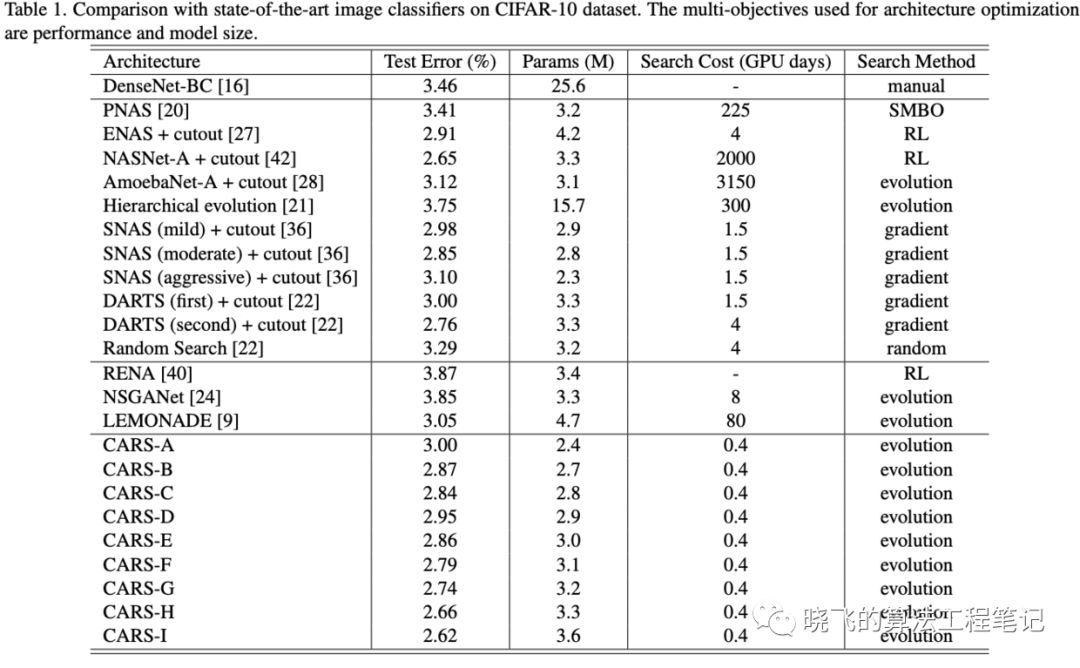
? 在完成CARS算法搜索后,保留128個不同的網絡,進行更長時間的訓練,然后測試準確率
Comparison on Searched Block
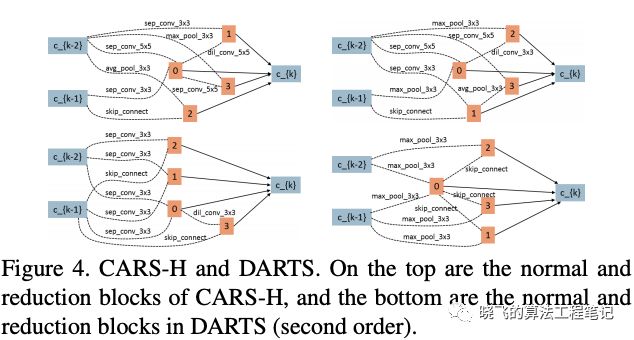
? CARS-H與DARTS參數相似,但準確率更高,CARS-H的reduction block包含更多的參數,而normal block包含更少的參數,大概由于EA有更大的搜索空間,而基因操作能更有效地跳出局部最優解,這是EA的優勢
Evaluate on ILSVRC2012
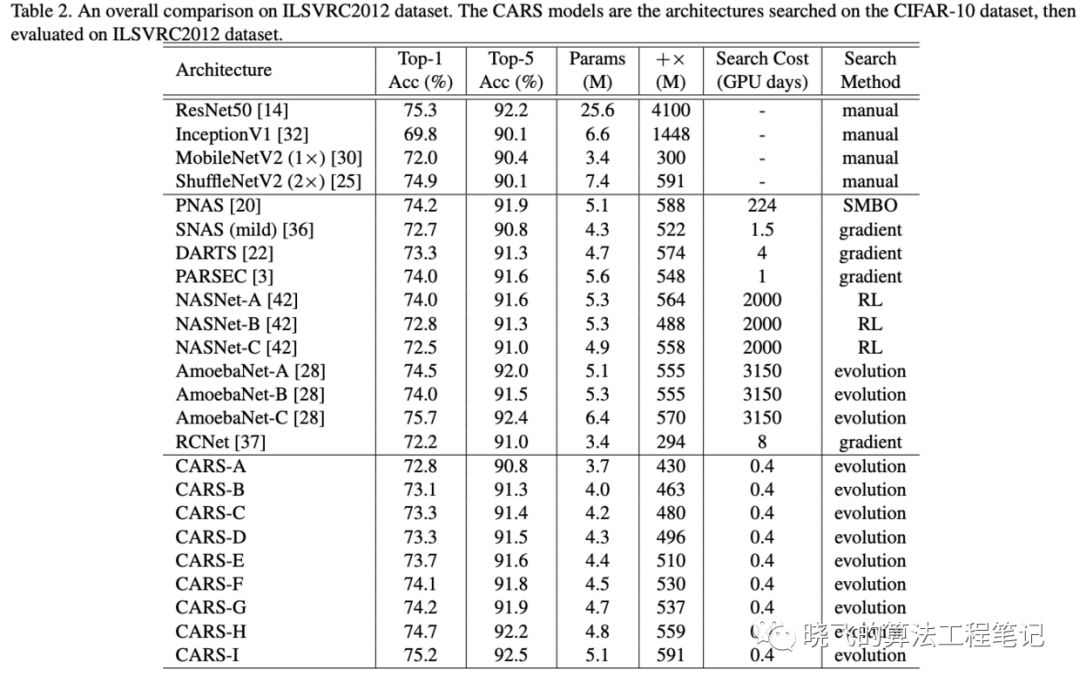
? 將在CIFAR-10上搜索到網絡遷移到ILSVRC22012數據集,結果表明搜索到的結構具備遷移能力
CONCLUSION
? 為了優化進化算法在神經網絡結構搜索時候選網絡訓練過長的問題,參考ENAS和NSGA-III,論文提出連續進化結構搜索方法(continuous evolution architecture search, CARS),最大化利用學習到的知識,如上一輪進化的結構和參數。首先構造用于參數共享的超網,從超網中產生子網,然后使用None-dominated排序策略來選擇不同大小的優秀網絡,整體耗時僅需要0.5 GPU day
參考內容
- Pareto相關理論 (https://blog.csdn.net/qq_34662278/article/details/91489077)
推薦閱讀
2020年AI算法崗求職群來了(含準備攻略、面試經驗、內推和學習資料等)
重磅!CVer-NAS交流群已成立
掃碼添加CVer助手,可申請加入CVer-NAS微信交流群,旨在交流AutoML(NAS)等的學習、科研、工程項目等內容。
一定要備注:研究方向+地點+學校/公司+昵稱(如NAS+上海+上交+卡卡),根據格式備注,可更快被通過且邀請進群

▲長按加群

▲長按關注我們
麻煩給我一個在看!


方法詳解)


)



需要掌握這些命令行(就還行了))






![deepfakes怎么用_[mcj]deepfakesApp使用說明(1)](http://pic.xiahunao.cn/deepfakes怎么用_[mcj]deepfakesApp使用說明(1))
![alert 標題_[SwiftUI 知識碎片] Button、Image 和 Alert](http://pic.xiahunao.cn/alert 標題_[SwiftUI 知識碎片] Button、Image 和 Alert)

