本發明涉及語義網絡技術領域,具體涉及新的小世界網絡模型實現文本特征的提取方法。
背景技術:
目前常用的文本特征提取方法,包括詞頻-反文檔頻率方法—TF-IDF、信息增益方法、互信息等方法;TF-IDF的簡單結構并不能有效地反映詞匯或短語的重要程度和特征值的分布情況,所以TF-IDF的精度并不是很高。信息增益方法只適合用來提取一個類別的文本特征,而無法用于提取多個類別的文本特征。互信息方法考慮了類別出現概率與集合出現概率之比,那么會造成一個缺陷,那就是類別集合中文本的數量差異會很大程度上影響文本特征提取的準確性。面對海量文本,如何快速掌握某篇文章的主題、把握作者思想,成為節約讀者時間、提高閱讀速度的關鍵問題。文本特征指的是最能代表文本主旨的詞匯集合,文本特征不僅可以很好的概括文本主要內容和主旨,而且可以降低文本處理的復雜程度。然而目前常用的文本特征提取方法沒有考慮特征詞匯的語義地位和其對文本主旨表達所做的貢獻、忽略文檔的語義信息和結構信息,導致關鍵詞語義和結構信息的缺失。為了滿足上述需求,本發明提供了一種新的小世界網絡模型實現文本特征的提取方法。
技術實現要素:
針對于常用的文本特征提取方法沒有考慮特征詞匯的語義地位和其對文本主旨表達所做貢獻的不足,本發明提供了一種新的小世界網絡模型實現文本特征的提取方法。
為了解決上述問題,本發明是通過以下技術方案實現的:
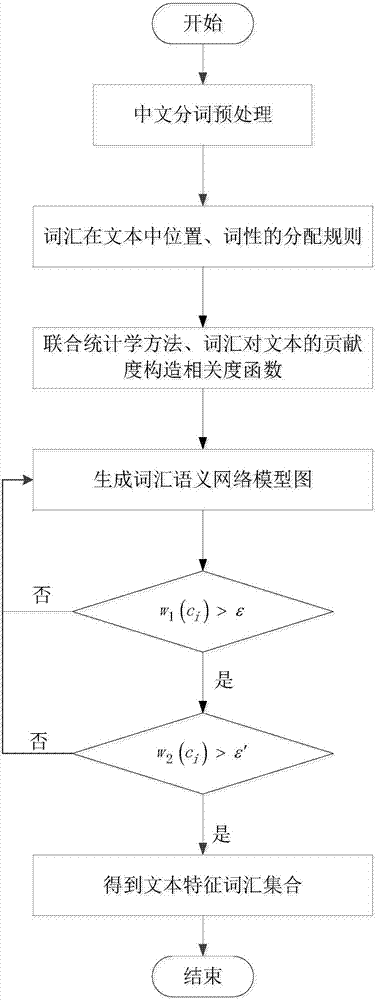
步驟1:初始化文本語料庫模塊,對文本W的進行中文分詞預處理。
步驟2:給步驟1中分詞結果的文本進行位置、詞性加權處理。
步驟3:得到的文本詞匯集合依據其語義相關度R(c1,c2)會出現聚合現象,構建詞匯語義網絡模型圖。
步驟4:根據圖中詞匯在整個語義網絡圖中的重要度構造兩函數參數w1(ci)、w2(ci),即可得詞匯在整個文本中的地位和貢獻度。
步驟5:根據步驟4中的兩參數設置合適閾值提取文本中的特征詞匯,即為代表文本主旨的特征詞匯向量。
本發明有益效果是:
1、此方法比傳統的詞頻-反文檔頻率方法得到的特征詞匯集合的準確度更高。
2、克服了信息增益方法只適合用來提取一個類別的文本特征的不足。
3、此算法具有更大的利用價值。
4、此方法精確地計算了特征詞匯中不同詞匯對文本思想的貢獻度。
5、計算特征詞匯中不同詞匯對文本思想的貢獻度具有更高的精確度。
6、為后續的文本相似度與文本聚類技術提供良好的理論基礎。
7、此方法著重在語義分析的角度來提取文本中的特征詞匯,更符合人們的經驗值。
8、融合了統計學方法,又綜合了關鍵詞在文本中的貢獻度,構建的詞匯語義網絡模型圖準確度更高。
9、在詞匯語義網絡模型中提取關鍵詞,既考慮了鄰近節點的密度,又考慮鄰近節點邊的權重,關鍵詞的提取更好的符合經驗值。
9、數據處理更加規范,易于詞匯語義網絡模型的生成。
10、在關鍵詞的相關度計算過程中,設定了更加嚴苛的約束條件,構成的詞
匯語義網絡模型圖更加符合實際情況。
附圖說明
圖1新的小世界網絡模型實現文本特征的提取方法的結構流程圖
圖2中文文本預處理過程流程圖
圖3 n元語法分詞算法圖解
圖4詞匯語義網絡模型圖
具體實施方式
為了解決常用的文本特征提取方法沒有考慮特征詞匯的語義地位和其對文本主旨表達所做貢獻的問題,結合圖1-圖4對本發明進行了詳細說明,其具體實施步驟如下:
步驟1:初始化文本語料庫模塊,對文本W的進行中文分詞預處理,其具體描述過程如下:
綜合分詞和刪除停用詞技術,中文文本預處理過程流程圖如圖2。。
這里分詞方法利用一種基于信息論中文自動分詞算法,其具體分詞和去停用詞步驟如下:
步驟1.1:利用停用表對文本進行去停用詞處理。
步驟1.2:根據《分詞詞典》找到待分詞句子中與詞典中匹配的詞,其具體描述如下:
把待分詞的漢字串完整的掃描一遍,在系統的詞典里進行查找匹配,遇到字典里有的詞就標識出來;如果詞典中不存在相關匹配,就簡單地分割出單字作為詞;直到漢字串為空。
步驟1.3:依據概率統計學,將待分詞句子拆分為網狀結構,即得n個可能組合的句子結構,把此結構每條順序節點依次規定為SM1M2M3M4M5E,其結構圖如圖3所示。
步驟1.4:基于信息論方法,給上述網狀結構每條邊賦予一定的權值,其具體計算過程如下:
根據《分詞詞典》匹配出的字典詞與未匹配的單個詞,第i條路徑包含詞的個數為ni。即n條路徑詞的個數集合為(n1,n2,…,nn)。
得min()=min(n1,n2,…,nn)
在上述留下的剩下的(n-m)路徑中,求解每條相鄰路徑的權重大小。
在統計語料庫中,計算每個詞的信息量X(Ci),再求解路徑相鄰詞的共現信
息量X(Ci,Ci+1)。既有下式:
X(Ci)=|x(Ci)1-x(Ci)2|
上式x(Ci)1為文本語料庫中詞Ci的信息量,x(Ci)2為含詞Ci的文本信息量。
x(Ci)1=-p(Ci)1lnp(Ci)1
上式p(Ci)1為Ci在文本語料庫中的概率,n為含詞Ci的文本語料庫的個數。
x(Ci)2=-p(Ci)2lnp(Ci)2
上式p(Ci)2為含詞Ci的文本數概率值,N為統計語料庫中文本總數。
同理X(Ci,Ci+1)=|x(Ci,Ci+1)1-x(Ci,Ci+1)2|
x(Ci,Ci+1)1為在文本語料庫中詞(Ci,Ci+1)的共現信息量,x(Ci,Ci+1)2為相鄰詞(Ci,Ci+1)共現的文本信息量。
同理x(Ci,Ci+1)1=-p(Ci,Ci+1)1lnp(Ci,Ci+1)1
上式p(Ci,Ci+1)1為在文本語料庫中詞(Ci,Ci+1)的共現概率,m為在文本庫中詞(Ci,Ci+1)共現的文本數量。
X(Ci,Ci+1)2=-P(Ci,Ci+1)2lnp(Ci,Ci+1)2
p(Ci,Ci+1)2為文本庫中相鄰詞(Ci,Ci+1)共現的文本數概率。
綜上可得每條相鄰路徑的權值為
w(Ci,Ci+1)=X(Ci)+X(Ci+1)-2X(Ci,Ci+1)
步驟1.5:找到權值最大的一條路徑,即為待分詞句子的分詞結果,其具體計算過程如下:
有n條路徑,每條路徑長度不一樣,假設路徑長度集合為(L1,L2,…,Ln)。
假設經過取路徑中詞的數量最少操作,排除了m條路徑,m
則每條路徑權重為:
上式分別為第1,2到路徑邊的權重值,根據步驟1.4可以一一計算得出,為剩下(n-m)路徑中第Sj條路徑的長度。
權值最大的一條路徑:
步驟2:給步驟1中分詞結果的文本進行位置、詞性加權處理,其具體描述如下:
αj代表位置權重,其賦值規則為:文本第一行是標題,賦予權值5;段首第一個詞等于“摘要”,則賦予權值3;段首第一個詞等于“關鍵字”或“關鍵詞”,則賦予權值5;段首第一個詞等于“結論”,賦予權值3;其它,每段首賦予權值1;
βk代表詞性權重,其賦值規則為:現代漢語語法中,一個句子主要由主語、謂語、賓語、定語和狀語等成分構成。從詞性的角度看,名詞一般擔當主語和賓語的角色,動詞一般擔當謂語的角色,形容詞和副詞一般擔當定語的角色。詞性的不同,造成了它們對文本或者句子的表示內容的能力的不一樣。根據調查統計得出名詞、動詞、形容詞、副詞的權重值依次為β1、β2、β3和β4,且β1>β2>β3>β4,其值可以由專家指出。
步驟3:得到的文本詞匯集合依據其語義相關度R(c1,c2)會出現聚合現象,構建詞匯語義網絡模型圖,其具體計算過程如下:
基于《知網》的詞匯相關度計算方法,文本特征詞匯集合中的兩兩詞匯間相關度計算公式為:
上式ρ(ICN)為兩詞匯本體概念共同的父節點密度,d(ICN)為兩詞匯本體概念共同的父節點深度,ρmax(S)為義原網狀結構中對應父節點所在的樹狀結構中的最大節點密度值,dmax(S)為義原網狀結構中對應父節點所在的樹狀結構中的樹的度。N′=0為兩詞匯(c1,c2)間無特殊關系,N′>0為兩詞匯(c1,c2)間有特殊關系,a為由專家給定的特殊關系權重,a∈(0,1),α、β分別為對應的影響系數,α、β∈(0,1),這個可以由實驗測出,α+β=1。
聯合詞匯在文本中的重要度、基于統計方法,構造詞匯對文本影響函數y(ci),根據R1(c1,c2)的值,y(ci)需歸一化處理:
即為
ni為詞匯ci在文本中出現的頻數,為文本詞匯的總頻數,NK為在滿足下式約束條件下庫中含有詞匯ci的文本數,為庫中所有文本的數量。
約束條件為:
ni·j為第j文本中詞匯ci出現的頻數,為第j文本中所有詞匯出現的總頻數。
綜合y(ci)、R1(c1,c2),即可得語義相關度R(c1,c2)
ρ、σ分別為對應因子的影響系數,ρ、σ∈(0,1),ρ+σ=1,其指可以根據實驗測出,一般ρ>σ,同理w、w′,不一樣的是,也許w′≥w,這個要視具體情況而定。
利用上式構建詞匯語義網絡模型圖,如圖4。
步驟4:根據圖中詞匯在整個語義網絡圖中的重要度構造兩函數參數w1(ci)、w2(ci),即可得詞匯在整個文本中的地位和貢獻度,其具體計算過程如下:
特征詞匯的分支越多,詞匯在整個文本中的地位和貢獻度越大,可以通過下式計算詞匯在整個語義網絡圖中的重要度;
為特征詞匯ci直接子節點的個數,Nt為整個語義網絡圖中總節點個數。
計算特征詞匯相鄰邊的平均權重w2(ci)
R(ci,cm)為ci與相鄰詞匯cm的相關度值,L為鄰邊數。
步驟5:根據步驟4中的兩參數設置合適閾值提取文本中的特征詞匯,即為代表文本主旨的特征詞匯向量,其具體計算過程如下:
相關專家設定w1(ci)、w2(ci)能夠滿足合適閾值ε、ε′∈(0,1),提取滿足下式關系的特征詞匯;
wl(Ci)>ε
w2(ci)>ε′
只有同時滿足上式兩條件,則提取該關鍵詞作為文本特征詞匯。



)









中,“:hover”樣式的設置問題?)

)


等方式接入Internet。...)
一種納米硅質絕熱材料及其制備方法...)