圖上的機器學習是一項艱巨的任務,由于高度復雜但信息量豐富,本文是關于如何利用圖卷積網絡(GCN)進行深度學習的系列文章中的第二篇。我將簡要回顧一下上一篇文章:
- 圖形卷積網絡的高級介紹
- 具有譜圖卷積的半監督學習(本文)
簡要回顧一下
在上一篇關于GCNs的文章中,我們看到了在GCNs中表達傳播的一個簡單的數學框架。總之,給定一個N×F?特征矩陣X和一個圖的矩陣表示結構,例如,N × N鄰接矩陣A的G,在GCN每個隱藏層可以表示為H? = f(H??1, A) ,其中? ?= X和?F是傳播規則。在H?= X和f是一個傳播規則。每層H? 對應一個N×F? 特征矩陣,其中每一行是一個節點的特征表示。
我們看到了這種形式的傳播規則
- f(H?, A) = σ(AH?W?)和
- f(H?, A) = σ(D?1?H?W?)其中? = A + I,I是單位矩陣,以及D?1是?的度矩陣。
這些規則在通過應用權重W?和激活函數σ進行變換之前,將節點的特征表示計算為其鄰居的特征表示的集合。通過將上面的傳播規則1和2表示為f(H?,A)=變換(聚合(A,H?),W?),我們可以使聚合和變換步驟更加明確,其中變換(M,W?)= σ(MW?)和規則1和聚合(A,H?)= AH?集合體(A,H?)= D?1? H? 對于規則2。
正如我們在上一篇文章中所討論的,規則1中的聚合將節點表示為其鄰居特征表示的和,其具有兩個顯著缺點:
- 節點的聚合表示不包含其自身的特征
- 具有較大度的節點將在其特征表示中具有較大值,而具有較小度的節點將具有較小值,這使得可能導致梯度爆炸問題的出現并且使用對特征縮放敏感的隨機梯度下降算法進行訓練變得更加困難。
為了解決這兩個問題,規則2首先通過向A 添加單位矩陣來強制執行自循環,并使用變換后的鄰接矩陣?= A + I進行聚合。接下來,通過乘以逆度矩陣D?1來對特征表示進行歸一化,將聚合轉換為聚合特征表示的比例對節點度不變的均值。
下面我將把規則1稱為求和規則,將規則2稱為均值規則。
譜圖卷積
Kipf和Welling最近的一篇論文提出了使用光譜傳播規則進行快速近似譜圖卷積:

與前一篇文章中討論的總和均值規則相比,譜規則僅在聚合函數的選擇上有所不同。雖然它有點類似于均值規則,因為它使用負冪的度矩陣D對聚合進行歸一化,但歸一化是不對稱的。
作為加權和的聚合
到目前為止,我們可以理解所呈現的聚合函數作為加權和,其中每個聚合規則僅在它們的權重選擇上不同。我們先來看看如何用加權和來表示相對簡單的總和和均值規則表示為加權和。
求和規則
為了了解如何使用求和規則計算第i個節點的聚合特征表示,我們看到如何計算聚合中的第i行。

求和規則作為加權和
如上面在等式1a中所示,我們可以將第i個節點的聚合特征表示計算為向量矩陣乘積。我們可以把這個向量矩陣乘積寫成一個簡單的加權和,如公式1b所示,我們對X中的每N行求和。
等式1b中j節點對集合的貢獻由A第i行第j列的值決定。由于A是鄰接矩陣,如果第j個節點是第i個節點的鄰居,則該值為1 ,否則為0。因此,等式1b對應于對第i個節點的鄰居的特征表示求和。
總之,每個鄰域的貢獻僅取決于鄰接矩陣A所定義的鄰域。
均值規則
為了了解均值規則如何聚合節點表示,我們再次看到如何計算聚合中的第i行,現在使用均值規則。為簡單起見,我們只考慮“raw”鄰接矩陣的均值規則,而不考慮A和單位矩陣I之間的加法,這相當于向圖中添加自循環。

加權和的均值規則
如上面的等式所示,推導現在略長。在等式2a中,我們首先將鄰接矩陣A與逆度矩陣D相乘進行變換。在等式2b中更明確地進行該計算。逆度矩陣是對角線矩陣,其中沿對角線的值是節點的逆度,而位置(i, i)的值是第i個節點的逆度,位置(i,i)處的值是第i個節點的逆度。因此,我們可以移除其中一個求和符號,得到等式2c。在等式2d和2e中可以進一步減少等式2c。
如等式2e所示,我們現在再次對鄰接矩陣A中的每N行求和。如在求和規則的討論中所提到的,這對應于對每個第i個節點的鄰居求和。但是,等式2e中加權和的權值現在保證與第i個節點的次數之和為1。因此,等式2e對應于第i個節點的鄰居的特征表示的均值。
總和規則僅取決于鄰接矩陣A定義的鄰域,而均值規則也取決于節點度。
譜規則
我們現在有一個有用的框架來分析譜規則。

作為加權和的譜規則
與均值規則一樣,我們使用度矩陣D對鄰接矩陣A進行變換。但是,如等式3a所示,我們將度矩陣提高到-0.5的冪并將其乘以A的每一邊。該操作可以如等式3b所示進行細分。度矩陣(及其冪)是對角線的。因此,我們可以進一步簡化等式3b,直到達到等式3e中的表達式。
等式3e顯示了在計算第i個節點的聚合特征表示時,我們不僅要考慮第i個節點的度,還要考慮第j個節點的度。
與平均規則類似,譜規則對聚合進行歸一化,聚合特征表示保持與輸入特征大致相同的度。然而,譜規則在加權和中鄰居的度越高權值越低,鄰居的權值度越低權值越高。當低度鄰居比高度鄰居提供更多信息時可能會更有用。
GCN的半監督分類
除譜規則外,Kipf和Welling還證明了GCNs如何用于半監督分類。到目前為止,我們已經隱式地假設整個圖表是可用的,即我們處于轉換環境中。換句話說,我們知道所有節點,但不知道所有節點標簽。
在我們看到的所有規則中,我們聚合在節點鄰域上,因此共享鄰居的節點往往具有相似的特征表示。如果圖表具有同質性,則此屬性非常有用,連接的節點往往是相似的(例如,具有相同的標簽)。同質性發生在許多真實網絡中,尤其是社交網絡表現出很強的同質性。
正如我們在上一篇文章中看到的那樣,即使是隨機初始化的GCN也可以通過使用圖結構,在同質圖中實現節點的特征表示之間的良好分離。通過在標記節點上訓練GCN,我們可以更進一步,有效地將節點標簽信息傳播到未標記的節點。這可以通過以下方式完成:
- 通過GCN執行前向傳播。
- 在GCN的最后一層逐行應用sigmoid函數。
- 計算已知節點標簽上的交叉熵損失。
- 反向傳播損失并更新每層中的權重矩陣W.
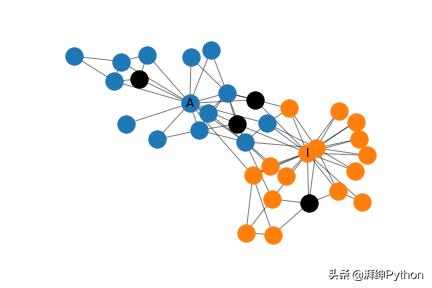
Zachary空手道俱樂部的社區預測
讓我們看看譜規則如何使用半監督學習將節點標簽信息傳播到未標記的節點。正如在以前的文章中,我們將使用Zachary空手道俱樂部作為一個例子。
Zachary空手道俱樂部
簡而言之,Zachary空手道俱樂部是一個小型的社交網絡,管理員和空手道俱樂部的教練之間會發生沖突。任務是預測空手道俱樂部的每個成員選擇的沖突的哪一方。網絡的圖形表示可以在下面看到。每個節點代表空手道俱樂部的成員,并且成員之間的連接指示他們在俱樂部外進行交互。管理員和教練分別標有A和I。

Zachary空手道俱樂部
MXNet中的譜圖卷積
我在MXNet中實現了譜規則,這是一個易于使用和高效的深度學習框架。實施如下:
class SpectralRule(HybridBlock): def __init__(self, A, in_units, out_units, activation, **kwargs): super().__init__(**kwargs) I = nd.eye(*A.shape) A_hat = A.copy() + I D = nd.sum(A_hat, axis=0) D_inv = D**-0.5 D_inv = nd.diag(D_inv) A_hat = D_inv * A_hat * D_inv self.in_units, self.out_units = in_units, out_units with self.name_scope(): self.A_hat = self.params.get_constant('A_hat', A_hat) self.W = self.params.get( 'W', shape=(self.in_units, self.out_units) ) if activation == 'ident': self.activation = lambda X: X else: self.activation = Activation(activation) def hybrid_forward(self, F, X, A_hat, W): aggregate = F.dot(A_hat, X) propagate = self.activation( F.dot(aggregate, W)) return propagate
__init__以鄰接矩陣A為輸入,以圖卷積層各節點特征表示的輸入和輸出維數為輸入; in_units和out_units分別為輸入和輸出維數。通過與單位矩陣I相加,將鄰接矩陣A加入自循環,計算度矩陣D,和鄰接矩陣變換A到A_hat由譜規則的規定。這種變換不是嚴格必需的,但是計算效率更高,因為在層的每次向前傳遞過程中都會執行轉換。
最后,在__init__的with子句中,我們存儲了兩個模型參數——A_hat存儲為常量,權矩陣W存儲為可訓練參數。
hybrid_forward是個奇跡發生的地方。在向前傳遞中,我們使用以下輸入執行此方法:X,上一層的輸出,以及我們在構造函數__init__中定義的參數A_hat和W。
構建圖卷積網絡
現在我們已經實現了譜規則,我們可以將這些層疊加在一起。我們使用類似于前一篇文章中的兩層架構,其中第一個隱藏層有4個單元,第二個隱藏層有2個單元。這種架構可以輕松地顯示最終的二維嵌入。它與前一篇文章中的架構有不同之處:
- 我們使用譜規則而不是平均規則。
- 我們使用不同的激活函數:tanh激活函數用于第一層,否則死亡神經元的概率會很高,而第二層使用identity 函數,因為我們使用最后一層來對節點進行分類。
最后,我們在GCN頂部添加邏輯回歸層以進行節點分類。
上述體系結構的Python實現如下。
def build_model(A, X): model = HybridSequential() with model.name_scope(): features = build_features(A, X) model.add(features) classifier = LogisticRegressor() model.add(classifier) model.initialize(Uniform(1)) return model, features
我已將包含圖卷積層的網絡的特征學習部分分離為features成分,將分類部分分離為classifier成分。單獨的features成分使以后更容易可視化這些層的激活。作為分類器的Logistic回歸器是一個分類層,它對最后一個圖卷積層提供的每個節點的特征進行求和,并對這個求和應用sigmoid函數進行Logistic回歸。
為了完整起見,構造features成分的代碼是
def build_features(A, X): hidden_layer_specs = [(4, 'tanh'), (2, 'tanh')] in_units = in_units=X.shape[1] features = HybridSequential() with features.name_scope(): for layer_size, activation_func in hidden_layer_specs: layer = SpectralRule( A, in_units=in_units, out_units=layer_size, activation=activation_func) features.add(layer) in_units = layer_size return features
Logistic回歸的代碼是
class LogisticRegressor(HybridBlock): def __init__(self, in_units, **kwargs): super().__init__(**kwargs) with self.name_scope(): self.w = self.params.get( 'w', shape=(1, in_units) ) self.b = self.params.get( 'b', shape=(1, 1) ) def hybrid_forward(self, F, X, w, b): # Change shape of b to comply with MXnet addition API b = F.broadcast_axis(b, axis=(0,1), size=(34, 1)) y = F.dot(X, w, transpose_b=True) + b return F.sigmoid(y)
訓練GCN
訓練GCN模型的代碼如下所示。初始化二進制交叉熵損失函數cross_entropy和SGD優化器,訓練器來學習網絡參數。然后對模型進行指定次數的訓練,其中計算每個訓練示例的損失,并使用loss.backward()對錯誤進行反向傳播。然后調用trainer.step來更新模型參數。在每個周期之后,由GCN層構造的特征表示形式存儲在feature_representations列表中,稍后我們將對該列表進行檢查。
def train(model, features, X, X_train, y_train, epochs): cross_entropy = SigmoidBinaryCrossEntropyLoss(from_sigmoid=True) trainer = Trainer( model.collect_params(), 'sgd', {'learning_rate': 0.001, 'momentum': 1}) feature_representations = [features(X).asnumpy()] for e in range(1, epochs + 1): for i, x in enumerate(X_train): y = array(y_train)[i] with autograd.record(): preds = model(X)[x] loss = cross_entropy(preds, y) loss.backward() trainer.step(1) feature_representations.append(features(X).asnumpy()) return feature_representations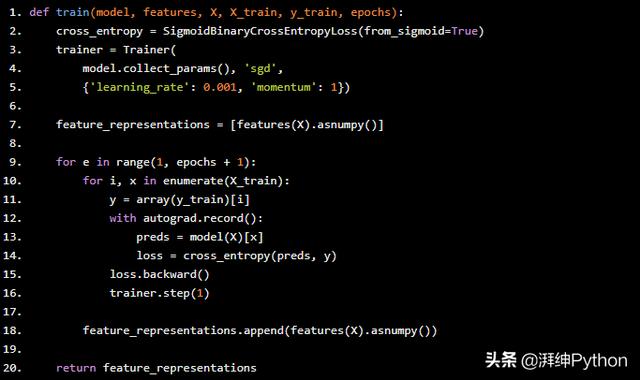
關鍵的是,只標記了教練和管理員的標簽,并且網絡中剩余的節點是已知的,但沒有標記。GCN可以在圖卷積過程中找到標記節點和未標記節點的表示形式,并可以在訓練過程中利用這兩個信息源進行半監督學習。
可視化功能
如上所述,存儲每個時期的特征表示,這允許我們在訓練期間看到特征表示如何改變。在下面我考慮兩個輸入特征表示。
表示1
在第一個表示中,我們簡單地使用稀疏34×34 的單位矩陣,I,作為特征矩陣X表示。該表示具有可以在任何圖中使用的優點,但是導致網絡中的每個節點的輸入參數,其需要大量的存儲器和計算能力用于大型網絡上的訓練并且可能導致過度擬合。不過,空手道俱樂部網絡非常小。使用該表示對網絡進行5000個周期的訓練。

使用表示法1分析空手道俱樂部的分類錯誤
通過對網絡中的所有節點進行集合分類,我們可以獲得上面顯示的網絡中的錯誤分布。黑色表示錯誤分類。盡管近一半(41%)的節點被錯誤分類,但與管理員或教練(但不是兩者)緊密相連的節點往往被正確分類。

在使用表征1的訓練過程中特征表征的變化
我已經說明了在訓練期間特征表示如何變化。節點最初是緊密集群的,但隨著訓練的進行,教練和管理員被拉開,用它們拖動一些節點。
雖然管理員和教練的表示方式完全不同,但他們拖動的節點不一定屬于他們的社區。這是因為圖卷積在特征空間中嵌入了共享鄰居的節點,但是共享鄰居的兩個節點可能無法同等地連接到管理員和教練。具體地,使用單位矩陣作為特征矩陣導致每個節點的高度局部表示,即,屬于圖的相同區域的節點可能緊密地嵌入在一起。這使得網絡難以以歸納方式在遠程區域之間共享公共知識。
表示2
我們將通過添加兩個不特定于網絡的任何節點或區域的特征來改進表示1。為此,我們計算從網絡中的每個節點到管理員和教練的最短路徑距離,并將這兩個特征連接到先前的表示。
可能會認為這有點欺騙,因為我們注入了關于圖中每個節點位置的全局信息; 理想情況下由features成分中的圖卷積層捕獲的信息。但是,圖卷積層始終具有局部視角,并且捕獲此類信息的能力有限。盡管如此,它仍然是理解GCNs的有用工具。
使用表示法1分析空手道俱樂部的分類錯誤
和前面一樣,我們對網絡中的所有節點進行分類,并繪制出錯誤在網絡中的分布。這次,只有四個節點被錯誤分類;相對于表示1的顯著改進。仔細檢查特征矩陣后,這些節點要么與教練和管理員等距(在最短路徑意義上),要么離管理員更近,但屬于教練社區。使用表示1對GCN進行250個周期的訓練。
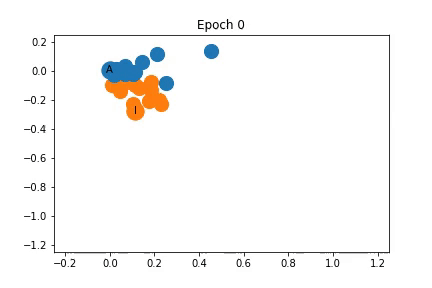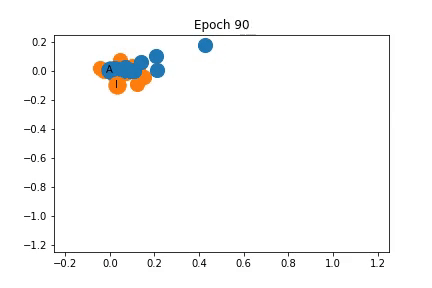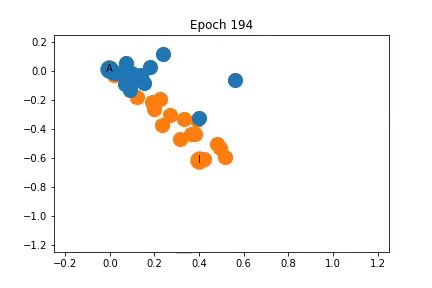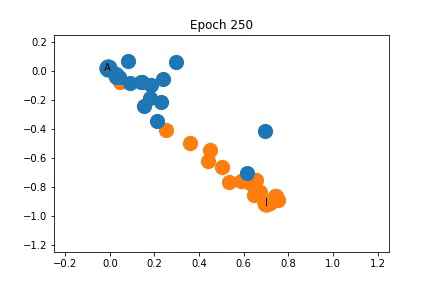
使用表征2的訓練過程中特征表征的變化
如圖所示,這些節點在開始時再次非常緊密地聚集在一起,但在訓練開始之前,它們在某種程度上分成了不同社區。隨著訓練的進行,社區之間的距離也會增加。
結論
在本文中,我對如何在GCNs中執行聚合進行了深入的解釋,并展示了如何使用平均值、總和和譜規則來將其表示為加權和。希望您會發現,在您自己的圖卷積網絡中,這個框架可以幫助您考慮在聚合過程中可能需要的權重。
我還展示了如何在MXNet中實現和訓練一個GCN,使用Zachary的空手道俱樂部的譜圖卷積對圖形執行半監督分類,這是一個簡單的示例網絡。我們看到僅僅使用兩個標記的節點,GCN仍然可以在表示空間中實現兩個網絡社區之間的高度分離。







)


...)


)
)




