from:https://blog.csdn.net/carson2005/article/details/6539192
?鑒于libSVM中的readme文件有點長,而且,都是采用英文書寫,這里,我把其中重要的內容提煉出來,并給出相應的例子來說明其用法,大家可以直接參考我的代碼來調用libSVM庫。
第一部分,利用libSVM自帶的簡易工具來演示SVM的兩類分類過程。(以下內容只是利用libSVM自帶的一個簡易的工具供大家更好的理解SVM,如果你對SVM已經有了一定的了解,可以直接跳過這部分內容)
首先,你要了解的是libSVM只是眾多SVM實現版本中的其中之一。而SVM是一種進行兩類分類的分類器,在libSVM最新版(libSVM3.1)里面,已經自帶了簡單的工具,可以對二分類進行演示。以windows平臺為例,將libSVM.zip解壓之后,有一個名為windows的子文件夾,里面有一個名為svm-toy.exe的可執行文件。直接雙擊,運行該可執行文件,顯示如下的界面
?
點擊第二個按鈕“Run”,然后,在左上部分,用鼠標左鍵隨機點幾下,代表你選擇的第一類模式的數據分布,下圖是我隨即點了幾下的結果:

?
之后,點擊“Change”,接著,用鼠標左鍵在窗口右下方隨便點擊幾下,代表你選擇的第二類模式的數據分布,如下圖所示:
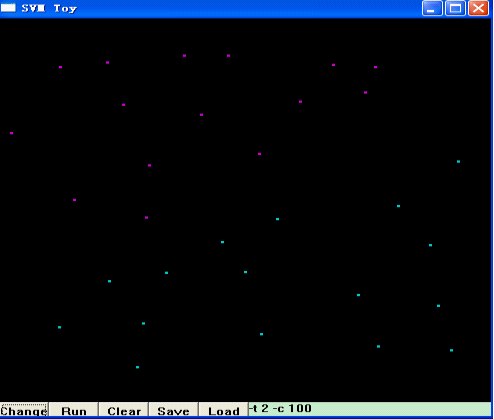
?
接著,點擊“Run”,libSVM就幫你把這兩類模式分開了,并用兩種不同的顏色區域來代表兩類不同的模式,如下圖所示:

?
圖中左上方紫色的區域,是第一類模式所在的區域,右下方的藍色區域,是你選擇的第二類模式所在的的區域,而兩者的分界面,也就是SVM的最優分類面。當然,SVM是通過核函數將原始數據映射到高維空間,在高維空間進行線性分類。換句話說,在高維空間,這兩類數據應該是線性可分的,即:最優分類面應該是一條直線,而這里看到的,是將高維空間分類的結果又映射回原始空間所呈現的分類結果,即:非線性的分類面。細心的朋友可能已經發現,在上述界面的右下角,有一個編輯框,里面寫著“-t?2?-c?100”,顯然,這是libSVM的一些參數,你也可以試著更改這些參數,來選擇不同的核函數、不同的SVM類型等來達到最好的分類效果。
?
?
第二部分:libSVM中的小工具
libSVM中包含以下可執行程序文件(小工具):
(1)svm-scale:一個用于對輸入數據進行歸一化的簡易工具
(2)svm-toy:一個帶有圖形界面的交互式SVM二分類功能演示小工具;
(3)svm-train:對用戶輸入的數據進行SVM訓練。其中,訓練數據是按照以下格式輸入的:
<類別號>?<索引1>:<特征值1>?<索引2>:<特征值2>...
(4)svm-predict:根據SVM訓練得到的模型,對輸入數據進行預測,即分類。
?
?
第三部分:libSVM用法介紹:`
? ? ? libSVM的所有函數申明及結構體定義均包含在libSVM.h文件當中,在使用過程中,你必須要包含該頭文件,并且,對libSVM.cpp進行相應的鏈接。在對libSVM中的函數用法進行詳細介紹之前,我們不妨先簡單了解一下libSVM.h中一些結構體的含義。
struct?svm_node
{
int?index;
double?value;
};
該結構體,定義了一個“SVM節點”,即:索引i及其所對應的第i個特征值。這樣n個相同類別號的SVM節點,就構成了一個SVM輸入向量。即:一個SVM輸入向量可以表示為如下的形式:
類別標簽?索引1:特征值1?索引2:特征值2?索引3:特征值3...
我們可以將若干個這樣的輸入向量輸入到libSVM進行訓練,或者,輸入一個類別標簽未知的向量對其進行預測。
struct?svm_problem
{
int?l;
double?*y;
struct?svm_node?**x;
};
該結構體中的l代表訓練樣本的個數;double型指針y代表l個訓練樣本中每個訓練樣本的類別號,也就是我們常說的“標簽”;而"SVM節點"x,則是一個指針的指針(如果你對指針的指針不熟悉,完全可以把x理解為一個矩陣),x所指向的內容就是所有訓練樣本所有的特征值數據。
假如我們有下面的訓練樣本數據:
類別標簽???特征值1??特征值2?特征值3?特征值4?特征值5
???1???????0?????0.1?????0.2??????0???????0
???2??????0?????0.1?????0.3?????-1.2???????0
???1????????0.4??????0??????0??????0???????0
???2??????0?????0.1???????0??????1.4??????0.5
??1????-0.1????-0.2???????0.1??????1.1??????0.1
那么,svm_problem結構體中的l=5(共有5個訓練樣本),y=[1,2,1,2,1];指針x所指向的內容可以視為5個行向量,每個行向量有5列,即:x指代一個5*5的矩陣,其值為:
(1,0)(2,0.1)(3,0.2)(4,0)(5,0)(-1,?)
(1,0)(2,0.1)(3,0.3)(4,-1.2)(5,0)(-1,?)
(1,0.4)(2,0)(3,0)(4,0)(5,0)(-1,?)
(1,0)(2,0.1)(3,0)(4,1.4)(5,0.5)(-1,?)
(1,-0.1)(2,-0.2)(3,0.1)(4,1.1)(5,0.1)(-1,?)?
需要提醒的是,這里,每一行最后一列都是以“-1”開頭,這是libSVM規定的特征值向量的結束標識;此外,索引應該按照升序方式進行排列。
???????
enum?{?C_SVC,?NU_SVC,?ONE_CLASS,?EPSILON_SVR,?NU_SVR?};//libSVM規定的SVM類型
?
enum?{?LINEAR,?POLY,?RBF,?SIGMOID,?PRECOMPUTED?};//libSVM規定的核函數的類型
?
struct?svm_parameter
{
int?svm_type;//取值為前面提到的枚舉類型中的值
int?kernel_type;//取值為前面提到的枚舉類型中的值
int?degree;?//用于多項式核函數/
double?gamma;//用于多項式、徑向基、S型核函數
???double?coef0;//用于多項式和S型核函數
?
/*?以下參數僅僅用于訓練階段?*/
double?cache_size;?//核緩存大小,以MB為單位
double?eps;?//誤差精度小于eps時,停止訓練
double?C;?//用于C_SVC,EPSILON_SVR,NU_SVR
int?nr_weight;?//用于C_SVC
int?*weight_label;//用于C_SVC
double*?weight;//用于C_SVC
double?nu;//用于NU_SVC,ONE_CLASS,NU_SVR
double?p;//用于EPSILON_SVR
int?shrinking;?//等于1代表執行啟發式收縮
int?probability;//等于1代表模型的分布概率已知
};
該結構體定義了libSVM中的用到的SVM參數。其中svm_type可以是C_SVC,?NU_SVC,?ONE_CLASS,?EPSILON_SVR,?NU_SVR中的任意一種,代表著SVM的類型;
C_SVC:?C-SVM?classification
????NU_SVC:?nu-SVM?classification
????ONE_CLASS:?one-class-SVM
????EPSILON_SVR:?epsilon-SVM?regression
????NU_SVR:?nu-SVM?regression
kernel_type可以是LINEAR,?POLY,?RBF,?SIGMOID中的一種,代表著核函數的類型;
LINEAR:?u'*v,線性核函數;
????POLY:?(gamma*u'*v?+?coef0)^degree,多項式核函數;
????RBF:?exp(-gamma*|u-v|^2),徑向基核函數;
????SIGMOID:?tanh(gamma*u'*v?+?coef0),S型核函數;
PRECOMPUTED:?kernel?values?in?training_set_file,自定義的核函數;
nr_weight,?weight_label,?and?weight這三個參數用于改變某些類的懲罰因子。當輸入數據不平衡,或者誤分類的風險代價不對稱的時候,這三個參數將會對樣本訓練起到非常重要的調節作用。
nr_weight是weight_label和weight的元素個數,或者稱之為維數。Weight[i]與weight_label[i]之間是一一對應的,weight[i]代表著類別weight_label[i]的懲罰因子的系數是weight[i]。如果你不想設置懲罰因子,直接把nr_weight設置為0即可。
為了防止錯誤的參數設置,你還可以調用libSVM提供的接口函數svm_check_parameter()來對輸入參數進行檢查。
?
????在使用libSVM進行分類之前,你需要通過樣本學習,構建一個SVM分類模型。該分類模型也可以理解為生成一些用于分類的“數據”。當然,構建的分類模型需要保存為文件,以便后續使用。用于libSVM訓練的函數,其申明如下所示:
struct?svm_model?*svm_train(const?struct?svm_problem?*prob,?const?struct?svm_parameter?*param);
顯然,該函數的輸入,就是svm_problem結構體的prob指針所指向的內容。該結構體在前面已經介紹過,其內部,不僅包含了訓練樣本的個數,還包含每個訓練樣本的“標簽”及該訓練樣本對應的特征數據。而svm_parameter類型的param指針則指定了libSVM所用到的諸如SVM類型,核函數類型,懲罰因子之類的參數。另外,該函數的返回值是一個svm_model結構體,該結構體的定義,在libSVM.cpp當中:
struct?svm_model
{
svm_parameter?param;?//SVM參數設置
int?nr_class;?//類別數量,對于regression和ne-class?SVM這兩種情況,該值為2
int?l;?//支持向量的個數
svm_node?**SV;?//支持向量
double?**sv_coef;?//用于決策函數的支持向量系數
double?*rho;?//決策函數中的常數項
double?*probA;?//?pariwise?probability?information
double?*probB;
?
//?for?classification?only
?
int?*label;?//?每個類類別標簽
int?*nSV;?//每個類的支持向量個數
int?free_sv;?//如果svm_model已經通過svm_load_model創建,則該值為1;如果svm_model是通過svm_train創建的,該值為0
};
需要提醒的是,libSVM支持多類分類問題,當有k個待分類問題時,libSVM構建k*(k-1)/2種分類模型來進行分類,即:libSVM采用一對一的方式來構建多類分類器,如下所示:
1?vs?2,?1?vs?3,?...,?1?vs?k,?2?vs?3,?...,?2?vs?k,?...,?k-1?vs?k。
用戶在得到SVM分類模型之后,需要將其進行保存。在這里,libSVM已經提供了相應的函數接口:
int?svm_save_model(const?char?*model_file_name,?const?struct?svm_model?*model);
在調用訓練函數之后,只需要指定保存位置,直接調用該函數,就可以進行相應的保存。
在對樣本進行訓練得到分類模型之后,就可以利用該分類模型對未知輸入數據進行類別判斷了,也就是我們常說的“預測”。用于libSVM預測的函數,其申明如下所示:
double?svm_predict(const?struct?svm_model?*model,?const?struct?svm_node?*x);
該函數的第一個參數就是利用樣本訓練得到的SVM分類模型,第二個參數,是輸入的未知模式的特征數據,即:得到了表征某一類別的特征數據,根據這些數據,來判斷它所對應的類別標簽。而SVM分類模型,可以由libSVM定義的下面這個接口函數來進行加載:
struct?svm_model?*svm_load_model(const?char?*model_file_name);
此外,在使用上述函數過程中,需要對svm_model及svm_parameter申請內存,而不使用它們的時候,用戶需要調用以下兩個函數進行內存釋放:
void?svm_destroy_model(struct?svm_model?*model);
void?svm_destroy_param(struct?svm_parameter?*param);






)



| 斯坦福大學機(吳恩達)器學習筆記【匯總】)






)

