- 目錄
- 1.上傳tar包
- 2.解壓
- 3. 設置環境變量
- 4.設置Hive的配置文件
- 5.啟動Hive
- 6.安裝MySQL
- 7.下載MySQL的驅動包
- 8.修改Hive的配置文件
- 9.啟動Hive
- 10.查看MySQL數據庫
目錄
1.上傳tar包
jar包地址:http://hive.apache.org/downloads.html
2.解壓
tar -zxvf apache-hive-2.1.1-bin.tar.gz -C /usr/local/ 進入到/usr/local目錄下,將解壓后的文件重命名為hive-2.1.1
mv apache-hive-2.1.1-bin/ hive-2.1.13. 設置環境變量
export HIVE_HOME=/usr/local/hive-2.1.1
export PATH=$PATH:$HIVE_HOME/bin使配置立即生效
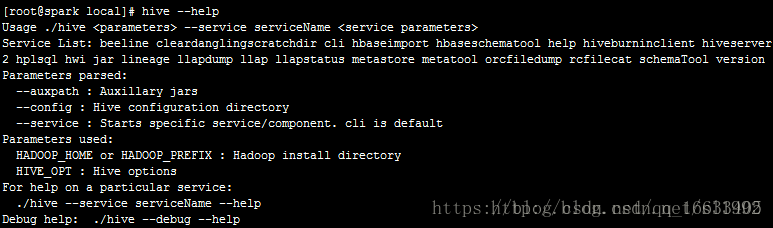
source /etc/profile hive沒有提供hive –version這種方式查看版本,執行hive –help查看
4.設置Hive的配置文件
在目錄$HIVE_HOME/conf/下,執行命令
cp hive-log4j2.properties.template hive-log4j2.properties拷貝一份重命名 ,并修改property.hive.log.dir = /usr/local/hive-2.1.1/logs/
暫時只配置這些
5.啟動Hive
Hadoop集群要先啟動
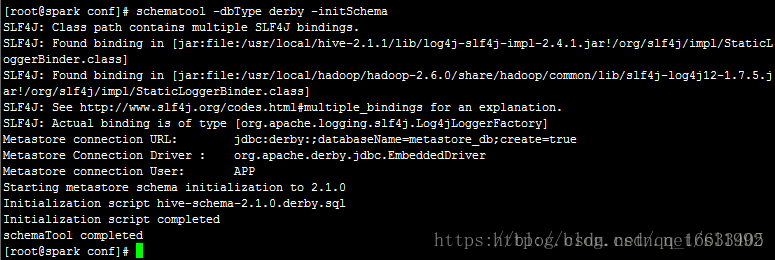
Starting from Hive 2.1, we need to run the schematool command below as an initialization step. For example, we can use “derby” as db type.$ $HIVE_HOME/bin/schematool -dbType <db type> -initSchema
這是Hive的官方文檔上描述的,Hive2.1的啟動需要先執行schematool命令
由于Hive默認內嵌的是derby數據庫,先使用默認的數據庫運行
執行schematool -dbType derby -initSchema進行初始化
執行命令hive進入到Hive Shell操作
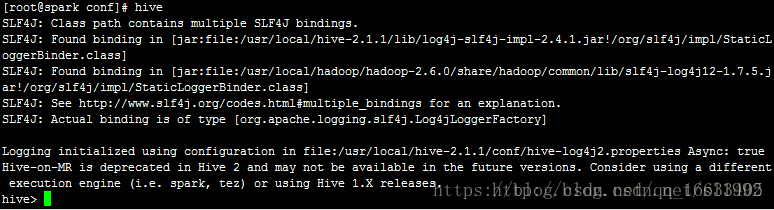
此時Hive安裝成功。
默認情況下,Hive的元數據保存在了內嵌的derby數據庫里,但一般情況下生產環境使用MySQL來存放Hive元數據。
6.安裝MySQL
參考:https://blog.csdn.net/qq_16633405/article/details/81872456
7.下載MySQL的驅動包
下載MySQL的驅動包放置到$HIVE_HOME/lib目錄下,本機使用的版本是mysql-connector-Java-5.1.36-bin.jar。
8.修改Hive的配置文件
在目錄$HIVE_HOME/conf/下,執行命令cp hive-default.xml.template hive-site.xml拷貝重命名
將hive-site.xml里面的property屬性配置全部刪除,Hive會加載默認配置。
添加如下內容(只需要將最后兩個屬性更改為你mysql的用戶名和對應的登錄密碼就OK了,其他全部照搬):
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property><property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property><property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property><property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>9.啟動Hive
Hadoop集群要先啟動
9.1 執行命令hive
出現不能實例化metadata的錯誤
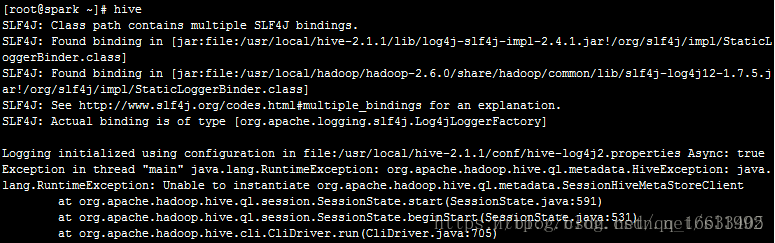
以及MySQL連接被拒絕的錯誤

9.2 首先解決MySQL連接被拒絕問題
mysql -uroot -proot
grant all privileges on *.* to root@'spark' identified by 'root';
flush privileges;
exit;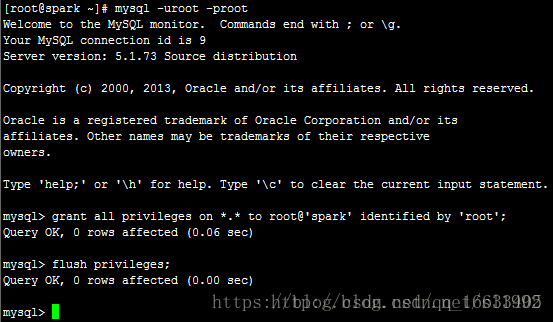
*.*代表全部數據庫的全部表授權,也可以指定數據庫授權,如test_db.*;
all privileges代表全部權限,也可以insert,update,delete,create,drop等;
允許root用戶在spark(Linux系統的主機名,IP映射)進行遠程登陸,并設置root用戶的密碼為root。
flush privileges告訴服務器重新加載授權表。
9.3 解決不能實例化metadata的錯誤
Hive2.1的啟動需要先執行schematool命令進行初始化
schematool -dbType mysql -initSchema 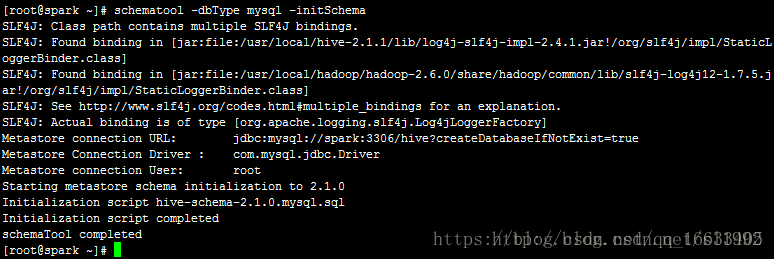
9.4 再次執行hive,進入到Hive Shell
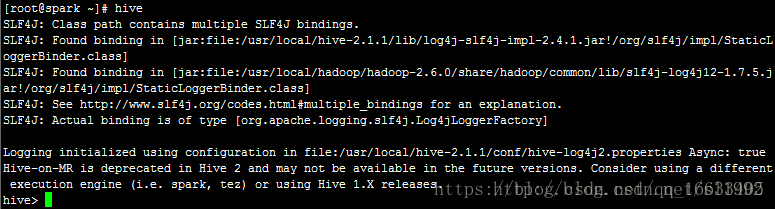
此時Hive和MySQL連接安裝部署成功。
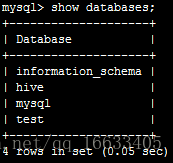
10.查看MySQL數據庫
hive-site.xml配置的是jdbc:mysql://spark:3306/hive?createDatabaseIfNotExist=true,即如果不存在hive數據庫會創建
默認MySQL里的數據庫
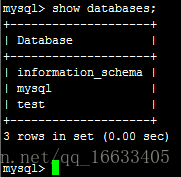
此時在MySQL里查看數據庫,多出了hive數據庫

)
)






)





)



