Scrapy 框架
-
Scrapy是用純Python實現一個為了爬取網站數據、提取結構性數據而編寫的應用框架,用途非常廣泛。
-
框架的力量,用戶只需要定制開發幾個模塊就可以輕松的實現一個爬蟲,用來抓取網頁內容以及各種圖片,非常之方便。
-
Scrapy 使用了 Twisted
['tw?st?d](其主要對手是Tornado)異步網絡框架來處理網絡通訊,可以加快我們的下載速度,不用自己去實現異步框架,并且包含了各種中間件接口,可以靈活的完成各種需求。
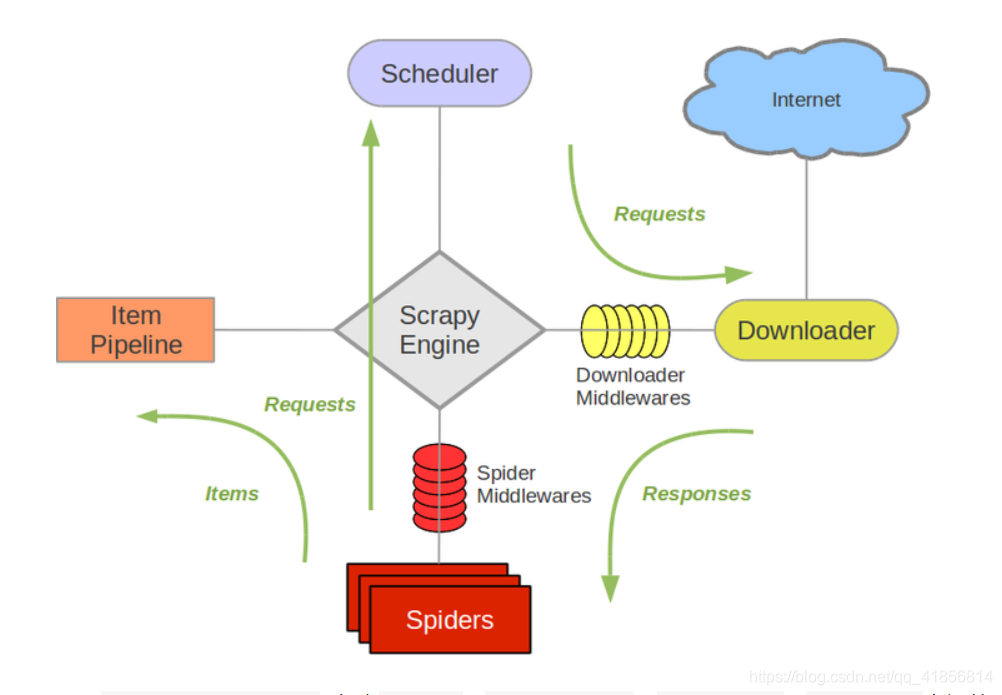
Scrapy架構圖(綠線是數據流向):

-
Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、數據傳遞等。 -
Scheduler(調度器): 它負責接受引擎發送過來的Request請求,并按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。 -
Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理, -
Spider(爬蟲):它負責處理所有Responses,從中分析提取數據,獲取Item字段需要的數據,并將需要跟進的URL提交給引擎,再次進入Scheduler(調度器), -
Item Pipeline(管道):它負責處理Spider中獲取到的Item,并進行進行后期處理(詳細分析、過濾、存儲等)的地方. -
Downloader Middlewares(下載中間件):你可以當作是一個可以自定義擴展下載功能的組件。 -
Spider Middlewares(Spider中間件):你可以理解為是一個可以自定擴展和操作引擎和Spider中間通信的功能組件(比如進入Spider的Responses;和從Spider出去的Requests)
Scrapy的運作流程
代碼寫好,程序開始運行...
-
引擎:Hi!Spider, 你要處理哪一個網站? -
Spider:老大要我處理xxxx.com。 -
引擎:你把第一個需要處理的URL給我吧。 -
Spider:給你,第一個URL是xxxxxxx.com。 -
引擎:Hi!調度器,我這有request請求你幫我排序入隊一下。 -
調度器:好的,正在處理你等一下。 -
引擎:Hi!調度器,把你處理好的request請求給我。 -
調度器:給你,這是我處理好的request -
引擎:Hi!下載器,你按照老大的下載中間件的設置幫我下載一下這個request請求 -
下載器:好的!給你,這是下載好的東西。(如果失敗:sorry,這個request下載失敗了。然后引擎告訴調度器,這個request下載失敗了,你記錄一下,我們待會兒再下載) -
引擎:Hi!Spider,這是下載好的東西,并且已經按照老大的下載中間件處理過了,你自己處理一下(注意!這兒responses默認是交給def parse()這個函數處理的) -
Spider:(處理完畢數據之后對于需要跟進的URL),Hi!引擎,我這里有兩個結果,這個是我需要跟進的URL,還有這個是我獲取到的Item數據。 -
引擎:Hi !管道?我這兒有個item你幫我處理一下!調度器!這是需要跟進URL你幫我處理下。然后從第四步開始循環,直到獲取完老大需要全部信息。 -
管道``調度器:好的,現在就做!
注意!只有當調度器中不存在任何request了,整個程序才會停止,(也就是說,對于下載失敗的URL,Scrapy也會重新下載。)
制作 Scrapy 爬蟲 一共需要4步:
- 新建項目 (scrapy startproject xxx):新建一個新的爬蟲項目
- 明確目標 (編寫items.py):明確你想要抓取的目標
- 制作爬蟲 (spiders/xxspider.py):制作爬蟲開始爬取網頁
- 存儲內容 (pipelines.py):設計管道存儲爬取內容




)





)



)




)