- 目錄
- 前言:
- 1、Kafka整體結構
- 2、Consumer與topic關系
- 3、Kafka消息的分發
- 4、Consumer的負載均衡
- 5、kafka文件存儲機制
- 總結:
目錄
前言:
本篇文章所介紹的內容還是以了解為主,主要目的還是為了對Kafka有一個更深入的理解。主要介紹了以下幾個知識點:Kafka的負載均衡、Producer生產數據、Kafka文件存儲機制等(不過總感覺這篇文章總結的亂七八糟。。請大家多多包涵,隨著后面的學習,自己會再回過頭來進行修改)
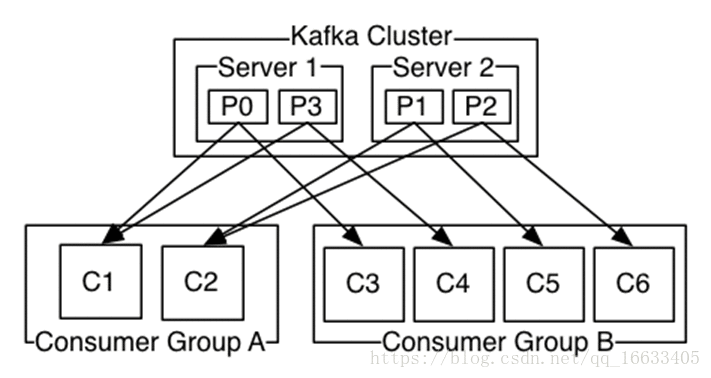
1、Kafka整體結構
Kafka名詞解釋和工作方式
- kafka:是一個生產-消費模型。類JMS消息隊列,結合JMS中的兩種模式,可以有多個消費者主動拉取數據,在JMS中只有點對點模式才有消費者主動拉取數據。
- Producer :消息生產者,就是向kafka broker發消息的客戶端。數據的分發策略由producer決定,默認是defaultPartition Utils.abs(key.hashCode) % numPartitions
- Consumer :消息消費者,向kafka broker取消息的客戶端
- Topic :可以理解為一個隊列或者目標發送的目的地,這是一個邏輯上的概念,落到磁盤上是一個partition的目錄。partition的目錄中有多個segment組合(index,log),一個Topic對應多個partition[0,1,2,3],一個partition對應多個segment組合。一個segment有默認的大小是1G。每個partition可以設置多個副本(replication-factor 1),會從所有的副本中選取一個leader出來。所有讀寫操作都是通過leader來進行的。特別強調,和mysql中主從有區別,mysql做主從是為了讀寫分離,在kafka中讀寫操作都是leader。
- Consumer Group(CG):數據消費者組,ConsumerGroup可以有多個,每個ConsumerGroup消費的數據都是一樣的。可以把多個consumer線程劃分為一個組,組里面所有成員共同消費一個topic的數據,組員之間不能重復消費。
- Broker :一臺kafka服務器就是一個broker。一個集群由多個broker組成。一個broker可以容納多個topic。只管數據存儲,不管是誰生產,不管是誰消費。
- Partition:為了實現擴展性,一個非常大的topic可以分布到多個broker(即服務器)上,一個topic可以分為多個partition,每個partition是一個有序的隊列。partition中的每條消息都會被分配一個有序的id(offset)。kafka只保證按一個partition中的順序將消息發給consumer,不保證一個topic的整體(多個partition間)的順序。
- Offset:kafka的存儲文件都是按照offset.kafka來命名,用offset做名字的好處是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。當然the first offset就是00000000000.kafka。
2、Consumer與topic關系
本質上kafka只支持Topic;
- 每個group中可以有多個consumer,每個consumer屬于一個consumer group;
通常情況下,一個group中會包含多個consumer,這樣不僅可以提高topic中消息的并發消費能力,而且還能提高”故障容錯”性,如果group中的某個consumer失效那么其消費的partitions將會有其他consumer自動接管。 - 對于Topic中的一條特定的消息,只會被訂閱此Topic的每個group中的其中一個consumer消費,此消息不會發送給一個group的多個consumer;那么一個group中所有的consumer將會交錯的消費整個Topic,每個group中consumer消息消費互相獨立,我們可以認為一個group是一個”訂閱”者。
- 在kafka中,一個partition中的消息只會被group中的一個consumer消費(同一時刻);
一個Topic中的每個partions,只會被一個”訂閱者”中的一個consumer消費,不過一個consumer可以同時消費多個partitions中的消息。 - kafka的設計原理決定,對于一個topic,同一個group中不能有多于partitions個數的consumer同時消費,否則將意味著某些consumer將無法得到消息。
kafka只能保證一個partition中的消息被某個consumer消費時是順序的;事實上,從Topic角度來說,當有多個partitions時,消息仍不是全局有序的。
3、Kafka消息的分發
Producer客戶端負責消息的分發
- kafka集群中的任何一個broker都可以向producer提供metadata信息,這些metadata中包含”集群中存活的servers列表”/”partitions leader列表”等信息;
- 當producer獲取到metadata信息之后, producer將會和Topic下所有partition
leader保持socket連接; - 消息由producer直接通過socket發送到broker,中間不會經過任何”路由層”,事實上,消息被路由到哪個partition上由producer客戶端決定;
比如可以采用”random”“key-hash”“輪詢”等,如果一個topic中有多個partitions,那么在producer端實現”消息均衡分發”是必要的。
在producer端的配置文件中,開發者可以指定partition路由的方式。
Producer消息發送的應答機制
ack機制:broker表示發來的數據已確認接收無誤,表示數據已經保存到磁盤。
設置發送數據是否需要服務端的反饋,有三個值0,1,-1
0: producer不會等待broker發送ack
1: 當leader接收到消息之后發送ack
-1: 當所有的follower都同步消息成功后發送ack
request.required.acks=0
4、Consumer的負載均衡
當一個group中,有consumer加入或者離開時,會觸發partitions均衡.均衡的最終目的,是提升topic的并發消費能力,步驟如下:
- 假如topic1,具有如下partitions: P0,P1,P2,P3
- 加入group中,有如下consumer: C1,C2
- 首先根據partition索引號對partitions排序: P0,P1,P2,P3
- 根據consumer.id排序: C0,C1
- 計算倍數: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
- 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1)
- M -1)]
5、kafka文件存儲機制
5.1、Kafka文件存儲基本結構
- 在Kafka文件存儲中,同一個topic下有多個不同partition,每個partition為一個目錄,partiton命名規則為topic名稱+有序序號,第一個partiton序號從0開始,序號最大值為partitions數量減1。
- 每個partition(目錄)相當于一個巨型文件被平均分配到多個大小相等segment(段)數據文件中。但每個段segment file消息數量不一定相等,這種特性方便old segment file快速被刪除。默認保留7天的數據。
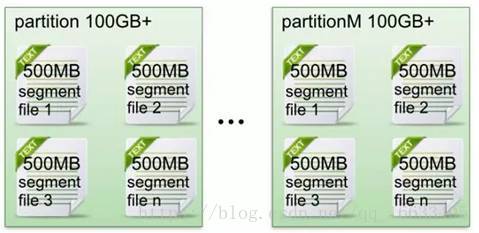
- 每個partiton只需要支持順序讀寫就行了,segment文件生命周期由服務端配置參數決定。(什么時候創建,什么時候刪除)
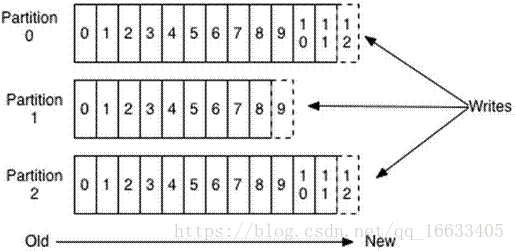
5.2、Kafka Partition Segment
- Segment file組成:由2大部分組成,分別為index file和data file,此2個文件一一對應,成對出現,后綴”.index”和“.log”分別表示為segment索引文件、數據文件。

- Segment文件命名規則:partion全局的第一個segment從0開始,后續每個segment文件名為上一個segment文件最后一條消息的offset值。數值最大為64位long大小,19位數字字符長度,沒有數字用0填充。
- 索引文件存儲大量元數據,數據文件存儲大量消息,索引文件中元數據指向對應數據文件中message的物理偏移地址。
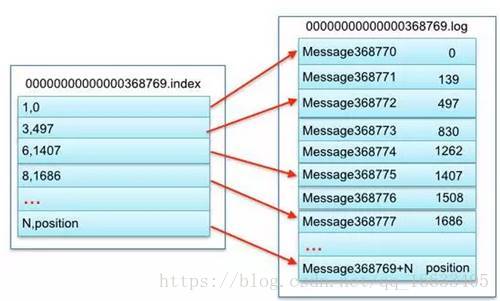
上述圖中索引文件存儲大量元數據,數據文件存儲大量消息,索引文件中元數據指向對應數據文件中message的物理偏移地址。
其中以索引文件中元數據3,497為例,依次在數據文件中表示第3個message(在全局partiton表示第368772個message)、以及該消息的物理偏移地址為497。
5.3、Kafka 查找message
讀取offset=368776的message,需要通過下面2個步驟查找。

5.3.1、查找segment file
00000000000000000000.index表示最開始的文件,起始偏移量(offset)為0
00000000000000368769.index的消息量起始偏移量為368770 = 368769 + 1
00000000000000737337.index的起始偏移量為737338=737337 + 1
其他后續文件依次類推。
以起始偏移量命名并排序這些文件,只要根據offset 二分查找文件列表,就可以快速定位到具體文件。當offset=368776時定位到00000000000000368769.index和對應log文件。
5.3.2、通過segment file查找message
當offset=368776時,依次定位到00000000000000368769.index的元數據物理位置和00000000000000368769.log的物理偏移地址
然后再通過00000000000000368769.log順序查找直到offset=368776為止。
總結:
需要了解的知識點有以下幾個:
1、Kafka的內部名詞及各個名詞的含義及作用。
2、Kafka消息分發的機制。
3、Consumer的負載均衡機制。
4、Kafka文件存儲機制。
總感覺這篇文章總結的比較亂,也許可以把其中的模塊拆開來寫吧。Anyway,就先總結成這樣吧,以后有機會會再修改。







詳解)




)
)





