- 目錄
- 1、Spark集群安裝
- 1.1. 安裝
- 2、啟動Spark Shell
- 2.1、啟動spark shell
- 2.2、在spark shell中編寫WordCount程序
目錄
1、Spark集群安裝
1.1. 安裝
1.1.1. 機器部署
準備兩臺以上Linux服務器,安裝好JDK1.7
1.1.2. 下載Spark安裝包
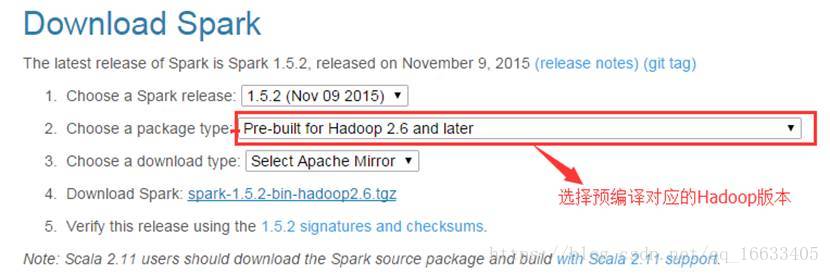
下載地址:http://www.apache.org/dyn/closer.lua/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz
上傳解壓安裝包
上傳spark-1.5.2-bin-hadoop2.6.tgz安裝包到Linux上
解壓安裝包到指定位置
tar -zxvf spark-1.5.2-bin-hadoop2.6.tgz -C /usr/local
1.1.3. 配置Spark
進入到Spark安裝目錄
cd /usr/local/spark-1.5.2-bin-hadoop2.6
進入conf目錄并重命名并修改spark-env.sh.template文件
cd conf/
mv spark-env.sh.template spark-env.sh
vi spark-env.sh
在該配置文件中添加如下配置
export JAVA_HOME=/usr/java/jdk1.7.0_45
export SPARK_MASTER_IP=node1
export SPARK_MASTER_PORT=7077
保存退出
重命名并修改slaves.template文件
mv slaves.template slaves
vi slaves
在該文件中添加子節點所在的位置(Worker節點)
node2
node3
node4
保存退出
將配置好的Spark拷貝到其他節點上
scp -r spark-1.5.2-bin-hadoop2.6/ node2:/usr/local/
scp -r spark-1.5.2-bin-hadoop2.6/ node3:/usr/local/
scp -r spark-1.5.2-bin-hadoop2.6/ node4:/usr/local/
Spark集群配置完畢,目前是1個Master,3個Work,在node1.itcast.cn上啟動Spark集群
/usr/local/spark-1.5.2-bin-hadoop2.6/sbin/start-all.sh
啟動后執行jps命令,主節點上有Master進程,其他子節點上有Work進行,登錄Spark管理界面查看集群狀態(主節點):http://node1:8080/
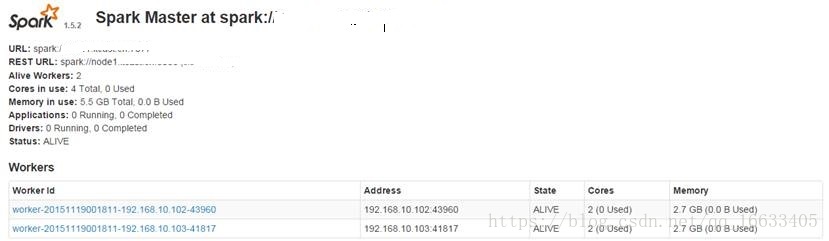
到此為止,Spark集群安裝完畢,但是有一個很大的問題,那就是Master節點存在單點故障,要解決此問題,就要借助zookeeper,并且啟動至少兩個Master節點來實現高可靠,配置方式比較簡單:
Spark集群規劃:node1,node2是Master;node3,node4,node5是Worker
安裝配置zk集群,并啟動zk集群
停止spark所有服務,修改配置文件spark-env.sh,在該配置文件中刪掉SPARK_MASTER_IP并添加如下配置
export SPARK_DAEMON_JAVA_OPTS=”-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk1,zk2,zk3 -Dspark.deploy.zookeeper.dir=/spark”
1.在node1節點上修改slaves配置文件內容指定worker節點
2.在node1上執行sbin/start-all.sh腳本,然后在node2上執行sbin/start-master.sh啟動第二個Master
2、啟動Spark Shell
spark-shell是Spark自帶的交互式Shell程序,方便用戶進行交互式編程,用戶可以在該命令行下用scala編寫spark程序。
2.1、啟動spark shell
這里需要先啟動對應的Spark集群
/root/apps/spark/bin/spark-shell –master spark://shizhan:7077 –executor-memory 2g –total-executor-cores 2
參數說明:
–master spark://shizhan:7077 指定Master的地址
–executor-memory 2g 指定每個worker可用內存為2G
–total-executor-cores 2 指定整個集群使用的cup核數為2個
注意:
如果啟動spark shell時沒有指定master地址,但是也可以正常啟動spark shell和執行spark shell中的程序,其實是啟動了spark的local模式,該模式僅在本機啟動一個進程,沒有與集群建立聯系。
Spark Shell中已經默認將SparkContext類初始化為對象sc。用戶代碼如果需要用到,則直接應用sc即可
2.2、在spark shell中編寫WordCount程序
1.首先啟動hdfs
2.向hdfs上傳一個文件到hdfs://192.168.112.200:9000/words.txt
3.在spark shell中用scala語言編寫spark程序
sc.textFile("hdfs://192.168.112.200:9000/wordcount/input/README.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://192.168.112.200:9000/out1")
4.使用hdfs命令查看結果
hdfs dfs -ls hdfs://node1.itcast.cn:9000/out/p*說明:
sc是SparkContext對象,該對象時提交spark程序的入口
textFile(hdfs://node1.itcast.cn:9000/words.txt)是hdfs中讀取數據
flatMap(_.split(” “))先map在壓平
map((_,1))將單詞和1構成元組
reduceByKey(+)按照key進行reduce,并將value累加
saveAsTextFile(“hdfs://node1.itcast.cn:9000/out”)將結果寫入到hdfs中
對于SparkSQL及SparkRDD的介紹請參考以下兩篇文章:
SparkSQL:https://blog.csdn.net/qq_16633405/article/details/79844593
SparkRDD:https://blog.csdn.net/qq_16633405/article/details/79843539


詳解)




)
)






![[轉] dpkg-deb命令](http://pic.xiahunao.cn/[轉] dpkg-deb命令)



