- 功能
- 輸出
- 實例
- 運行環境
- 使用說明
- 下載腳本
- 安裝依賴
- 程序設置
- 設置數據庫(可選)
- 運行腳本
- 按需求修改腳本(可選)
- 如何獲取user_id
- 添加cookie與不添加cookie的區別(可選)
- 如何獲取cookie(可選)
- 如何檢測cookie是否有效(可選)
功能
連續爬取一個或多個新浪微博用戶(如Dear-迪麗熱巴、郭碧婷)的數據,并將結果信息寫入文件。寫入信息幾乎包括了用戶微博的所有數據,主要有用戶信息和微博信息兩大類,前者包含用戶昵稱、關注數、粉絲數、微博數等等;后者包含微博正文、發布時間、發布工具、評論數等等,因為內容太多,這里不再贅述,詳細內容見輸出部分。具體的寫入文件類型如下:
- 寫入csv文件(默認)
- 寫入json文件(可選)
- 寫入MySQL數據庫(可選)
- 寫入MongoDB數據庫(可選)
- 下載用戶原創微博中的原始圖片(可選)
- 下載用戶轉發微博中的原始圖片(可選)
- 下載用戶原創微博中的視頻(可選)
- 下載用戶轉發微博中的視頻(可選)
- 下載用戶原創微博Live Photo中的視頻(可選)
- 下載用戶轉發微博Live Photo中的視頻(可選)
輸出
用戶信息
- 用戶id:微博用戶id,如"1669879400"
- 用戶昵稱:微博用戶昵稱,如"Dear-迪麗熱巴"
- 性別:微博用戶性別
- 微博數:用戶的全部微博數(轉發微博+原創微博)
- 粉絲數:用戶的粉絲數
- 關注數:用戶關注的微博數量
- 簡介:用戶簡介
- 主頁地址:微博移動版主頁url,如https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400
- 頭像url:用戶頭像url
- 高清頭像url:用戶高清頭像url
- 微博等級:用戶微博等級
- 會員等級:微博會員用戶等級,普通用戶該等級為0
- 是否認證:用戶是否認證,為布爾類型
- 認證類型:用戶認證類型,如個人認證、企業認證、政府認證等
- 認證信息:為認證用戶特有,用戶信息欄顯示的認證信息
微博信息
- 微博id:微博的id,為一串數字形式
- 微博bid:微博的bid,與cookie版中的微博id是同一個值
- 微博內容:微博正文
- 原始圖片url:原創微博圖片和轉發微博轉發理由中圖片的url,若某條微博存在多張圖片,則每個url以英文逗號分隔,若沒有圖片則值為’’
- 視頻url: 微博中的視頻url和Live Photo中的視頻url,若某條微博存在多個視頻,則每個url以英文分號分隔,若沒有視頻則值為’’
- 微博發布位置:位置微博中的發布位置
- 微博發布時間:微博發布時的時間,精確到天
- 點贊數:微博被贊的數量
- 轉發數:微博被轉發的數量
- 評論數:微博被評論的數量
- 微博發布工具:微博的發布工具,如iPhone客戶端、HUAWEI Mate 20 Pro等,若沒有則值為’’
- 話題:微博話題,即兩個#中的內容,若存在多個話題,每個url以英文逗號分隔,若沒有則值為’’
- @用戶:微博@的用戶,若存在多個@用戶,每個url以英文逗號分隔,若沒有則值為’’
- 原始微博:為轉發微博所特有,是轉發微博中那條被轉發的微博,存儲為字典形式,包含了上述微博信息中的所有內容,如微博id、微博內容等等
- 結果文件:保存在當前目錄weibo文件夾下以用戶昵稱為名的文件夾里,名字為"user_id.csv"形式
- 微博圖片:微博中的圖片,保存在以用戶昵稱為名的文件夾下的img文件夾里
- 微博視頻:微博中的視頻,保存在以用戶昵稱為名的文件夾下的video文件夾里
實例
以爬取迪麗熱巴的微博為例,我們需要修改config.json文件,文件內容如下:
{"user_id_list": ["1669879400"],"filter": 1,"since_date": "1900-01-01","write_mode": ["csv"],"original_pic_download": 1,"retweet_pic_download": 0,"original_video_download": 1,"retweet_video_download": 0,"cookie": "your cookie"
}
對于上述參數的含義以及取值范圍,這里僅作簡單介紹,詳細信息見程序設置。
user_id_list代表我們要爬取的微博用戶的user_id,可以是一個或多個,也可以是文件路徑,微博用戶Dear-迪麗熱巴的user_id為1669879400,具體如何獲取user_id見如何獲取user_id;
filter的值為1代表爬取全部原創微博,值為0代表爬取全部微博(原創+轉發);
since_date代表我們要爬取since_date日期之后發布的微博,因為我要爬迪麗熱巴的全部原創微博,所以since_date設置了一個非常早的值;
write_mode代表結果文件的保存類型,我想要把結果寫入csv文件和json文件,所以它的值為[“csv”, “json”],如果你想寫入數據庫,具體設置見設置數據庫;
original_pic_download值為1代表下載原創微博中的圖片,值為0代表不下載;
retweet_pic_download值為1代表下載轉發微博中的圖片,值為0代表不下載;
original_video_download值為1代表下載原創微博中的視頻,值為0代表不下載;
retweet_video_download值為1代表下載轉發微博中的視頻,值為0代表不下載;
cookie是可選參數,可填可不填,具體區別見添加cookie與不添加cookie的區別。
配置完成后運行程序:
$ python weibo.py
程序會自動生成一個weibo文件夾,我們以后爬取的所有微博都被存儲在weibo文件夾里。然后程序在該文件夾下生成一個名為"Dear-迪麗熱巴"的文件夾,迪麗熱巴的所有微博爬取結果都在這里。"Dear-迪麗熱巴"文件夾里包含一個csv文件、一個img文件夾和一個video文件夾,img文件夾用來存儲下載到的圖片,video文件夾用來存儲下載到的視頻。如果你設置了保存數據庫功能,這些信息也會保存在數據庫里,數據庫設置見設置數據庫部分。
csv文件結果如下所示:
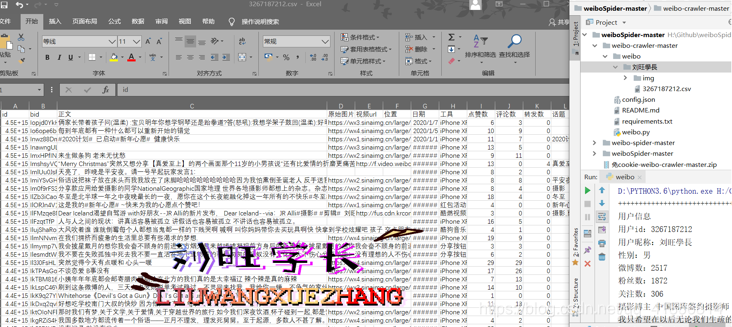 3267187212.csv
3267187212.csv
本csv文件是爬取“全部微博”(原創微博+轉發微博)的結果文件。因為迪麗熱巴很多微博本身都沒有圖片、發布工具、位置、話題和@用戶等信息,所以當這些內容沒有時對應位置為空。“是否原創"列用來標記是否為原創微博,
當為轉發微博時,文件中還包含轉發微博的信息。為了簡便起見,姑且將轉發微博中被轉發的原始微博稱為源微博,它的用戶id、昵稱、微博id等都在名稱前加上源字,以便與目標用戶自己發的微博區分。對于轉發微博,程序除了獲取用戶原創部分的信息,還會獲取源用戶id、源用戶昵稱、源微博id、源微博正文、源微博原始圖片url、源微博位置、源微博日期、源微博工具、源微博點贊數、源微博評論數、源微博轉發數、源微博話題、源微博@用戶等信息。原創微博因為沒有這些轉發信息,所以對應位置為空。若爬取的是"全部原創微博”,則csv文件中不會包含"是否原創"及其之后的轉發屬性列;
為了說明json結果文件格式,這里以迪麗熱巴2019年12月27日到2019年12月28日發的2條微博為例。
json結果文件格式如下:
{"user": {"id": "1669879400","screen_name": "Dear-迪麗熱巴","gender": "f","statuses_count": 1085,"followers_count": 65585238,"follow_count": 248,"description": "一只喜歡默默表演的小透明。工作聯系jaywalk@jaywalk.com.cn 🍒","profile_url": "https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400","profile_image_url": "https://tvax1.sinaimg.cn/crop.0.0.996.996.180/63885668ly8fjf57kfmgfj20ro0ro0u7.jpg?KID=imgbed,tva&Expires=1578329741&ssig=3jZYwOBVPM","avatar_hd": "https://wx1.sinaimg.cn/orj480/63885668ly8fjf57kfmgfj20ro0ro0u7.jpg","urank": 44,"mbrank": 7,"verified": true,"verified_type": 0,"verified_reason": "嘉行傳媒簽約演員 "},"weibo": [{"user_id": 1669879400,"screen_name": "Dear-迪麗熱巴","id": 4454572602912349,"bid": "ImTGkcdDn","text": "今天的#星光大賞# ","pics": "https://wx3.sinaimg.cn/large/63885668ly1gacppdn1nmj21yi2qp7wk.jpg,https://wx4.sinaimg.cn/large/63885668ly1gacpphkj5gj22ik3t0b2d.jpg,https://wx4.sinaimg.cn/large/63885668ly1gacppb4atej22yo4g04qr.jpg,https://wx2.sinaimg.cn/large/63885668ly1gacpn0eeyij22yo4g04qr.jpg","video_url": "","location": "","created_at": "2019-12-28","source": "","attitudes_count": 551894,"comments_count": 182010,"reposts_count": 1000000,"topics": "星光大賞","at_users": ""},{"user_id": 1669879400,"screen_name": "Dear-迪麗熱巴","id": 4454081098040623,"bid": "ImGTzxJJt","text": "我最愛用的嬌韻詩雙萃精華穿上限量“金”裝啦,希望阿絲兒們跟我一起在新的一年更美更年輕,喜笑顏開沒有細紋困擾!限定新春禮盒還有祝福悄悄話,大家了解一下~","pics": "","video_url": "","location": "","created_at": "2019-12-27","source": "","attitudes_count": 190840,"comments_count": 43523,"reposts_count": 1000000,"topics": "","at_users": "","retweet": {"user_id": 1684832145,"screen_name": "法國嬌韻詩","id": 4454028484570123,"bid": "ImFwIjaTF","text": "#點萃成金 年輕煥新# 將源自天然的植物力量,轉化為滴滴珍貴如金的雙萃精華。這份點萃成金的獨到匠心,只為守護嬌粉們的美麗而來。點擊視頻,與@Dear-迪麗熱巴 一同邂逅新年限量版黃金雙萃,以閃耀開運金,送上新春寵肌臻禮。 跟著迪迪選年貨,還有雙重新春驚喜,愛麗絲們看這里! 第一重參與微淘活動邀請好友關注嬌韻詩天貓旗艦店,就有機會贏取限量款熱巴新年禮盒,打開就能聆聽仙女迪親口送出的新春祝福哦!點擊網頁鏈接下單曬熱巴同款黃金雙萃,并且@法國嬌韻詩,更有機會獲得熱巴親筆簽名的禮盒哦! 第二重轉評說出新年希望嬌韻詩為你解決的肌膚愿望,截止至1/10,小嬌將從鐵粉中抽取1位嬌粉送出限量版熱巴定制禮盒,抽取3位嬌粉送出熱巴明信片1張~ #迪麗熱巴代言嬌韻詩#養成同款御齡美肌,就從現在開始。法國嬌韻詩的微博視頻","pics": "","video_url": "http://f.video.weibocdn.com/003vQjnRlx07zFkxIMjS010412003bNx0E010.mp4?label=mp4_hd&template=852x480.25.0&trans_finger=62b30a3f061b162e421008955c73f536&Expires=1578322522&ssig=P3ozrNA3mv&KID=unistore,video","location": "","created_at": "2019-12-27","source": "微博 weibo.com","attitudes_count": 18389,"comments_count": 3201,"reposts_count": 1000000,"topics": "點萃成金 年輕煥新,迪麗熱巴代言嬌韻詩","at_users": "Dear-迪麗熱巴,法國嬌韻詩"}}]
}
1669879400.json
下載的圖片如下所示:
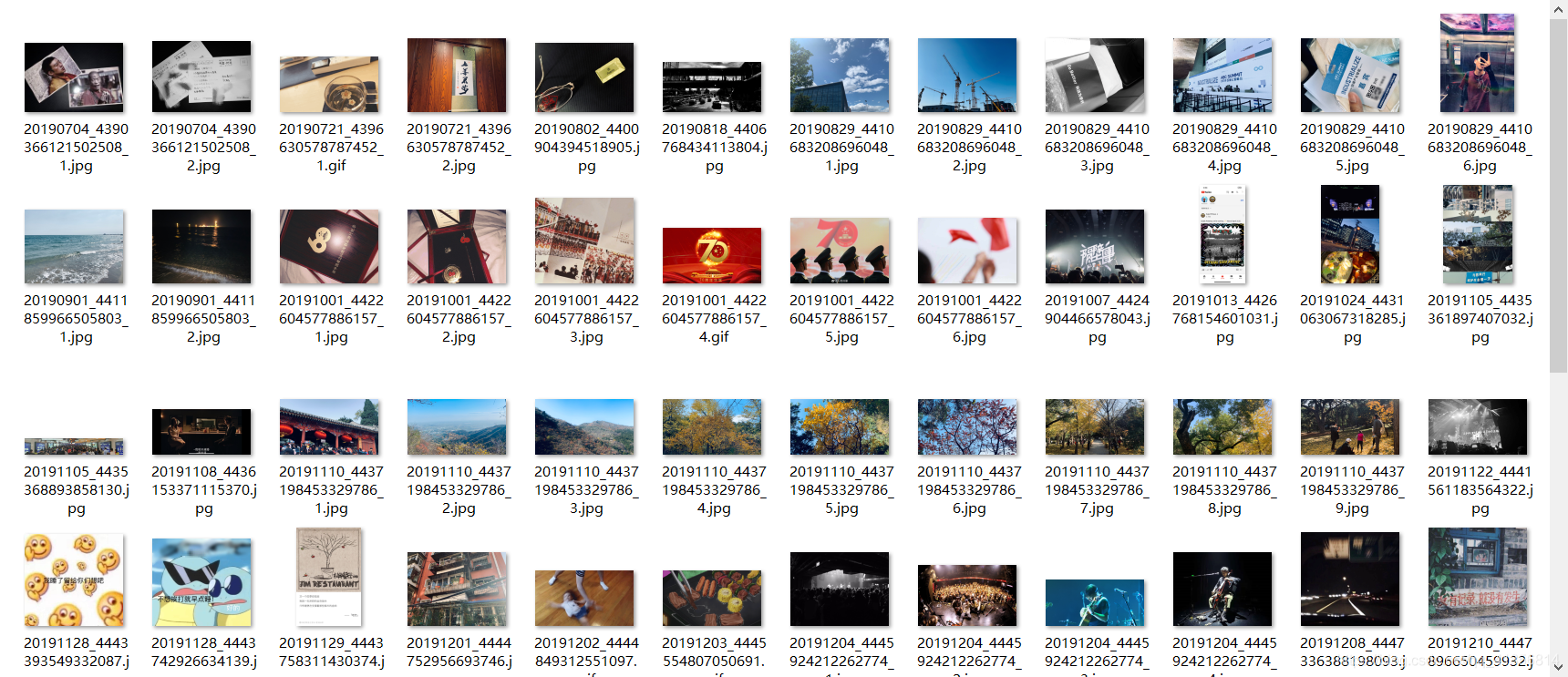 )img文件夾
)img文件夾
本次下載了788張圖片,大小一共1.21GB,包括她原創微博中的所有圖片。圖片名為yyyymmdd+微博id的形式,若某條微博存在多張圖片,則圖片名中還會包括它在微博圖片中的序號。若某圖片下載失敗,程序則會以“weibo_id:pic_url”的形式將出錯微博id和圖片url寫入同文件夾下的not_downloaded.txt里;若圖片全部下載成功則不會生成not_downloaded.txt;
下載的視頻如下所示:
video文件夾
本次下載了66個視頻,是她原創微博中的視頻和原創微博Live Photo中的視頻,視頻名為yyyymmdd+微博id的形式。有三個視頻因為網絡原因下載失敗,程序將它們的微博id和視頻url分別以“weibo_id:video_url”的形式寫到了同文件夾下的not_downloaded.txt里。
因為我本地沒有安裝MySQL數據庫和MongoDB數據庫,所以暫時設置成不寫入數據庫。如果你想要將爬取結果寫入數據庫,只需要先安裝數據庫(MySQL或MongoDB),再安裝對應包(pymysql或pymongo),然后將mysql_write或mongodb_write值設置為1即可。寫入MySQL需要用戶名、密碼等配置信息,這些配置如何設置見設置數據庫部分。
運行環境
- 開發語言:python2/python3
- 系統: Windows/Linux/macOS
使用說明
1.下載腳本
$ git clone https://github.com/dataabc/weibo-crawler.git
運行上述命令,將本項目下載到當前目錄,如果下載成功當前目錄會出現一個名為"weibo-crawler"的文件夾;
2.安裝依賴
$ pip install -r requirements.txt
3.程序設置
打開config.json文件,你會看到如下內容:
{"user_id_list": ["1669879400"],"filter": 1,"since_date": "2018-01-01","write_mode": ["csv"],"original_pic_download": 1,"retweet_pic_download": 0,"original_video_download": 1,"retweet_video_download": 0,"mysql_config": {"host": "localhost","port": 3306,"user": "root","password": "123456","charset": "utf8mb4"}
}
下面講解每個參數的含義與設置方法。
設置user_id_list
user_id_list是我們要爬取的微博的id,可以是一個,也可以是多個,例如:
"user_id_list": ["1223178222", "1669879400", "1729370543"],
上述代碼代表我們要連續爬取user_id分別為“1223178222”、 “1669879400”、 “1729370543”的三個用戶的微博,具體如何獲取user_id見如何獲取user_id。
user_id_list的值也可以是文件路徑,我們可以把要爬的所有微博用戶的user_id都寫到txt文件里,然后把文件的位置路徑賦值給user_id_list。
在txt文件中,每個user_id占一行,也可以在user_id后面加注釋(可選),如用戶昵稱等信息,user_id和注釋之間必需要有空格,文件名任意,類型為txt,位置位于本程序的同目錄下,文件內容示例如下:
1223178222 胡歌
1669879400 迪麗熱巴
1729370543 郭碧婷
假如文件叫user_id_list.txt,則user_id_list設置代碼為:
"user_id_list": "user_id_list.txt",
設置filter
filter控制爬取范圍,值為1代表爬取全部原創微博,值為0代表爬取全部微博(原創+轉發)。例如,如果要爬全部原創微博,請使用如下代碼:
"filter": 1,
設置since_date
since_date值可以是日期,也可以是整數。如果是日期,代表爬取該日期之后的微博,格式應為“yyyy-mm-dd”,如:
"since_date": "2018-01-01",
代表爬取從2018年1月1日到現在的微博。
如果是整數,代表爬取最近n天的微博,如:
"since_date": 10,
代表爬取最近10天的微博,這個說法不是特別準確,準確說是爬取發布時間從10天前到本程序開始執行時之間的微博。
設置write_mode
write_mode控制結果文件格式,取值范圍是csv、json、mongo和mysql,分別代表將結果文件寫入csv、json、MongoDB和MySQL數據庫。write_mode可以同時包含這些取值中的一個或幾個,如:
"write_mode": ["csv", "json"],
代表將結果信息寫入csv文件和json文件。特別注意,如果你想寫入數據庫,除了在write_mode添加對應數據庫的名字外,還應該安裝相關數據庫和對應python模塊,具體操作見設置數據庫部分。
設置original_pic_download
original_pic_download控制是否下載原創微博中的圖片,值為1代表下載,值為0代表不下載,如
"original_pic_download": 1,
代表下載原創微博中的圖片。
設置retweet_pic_download
retweet_pic_download控制是否下載轉發微博中的圖片,值為1代表下載,值為0代表不下載,如
"retweet_pic_download": 0,
代表不下載轉發微博中的圖片。特別注意,本設置只有在爬全部微博(原創+轉發),即filter值為0時生效,否則程序會跳過轉發微博的圖片下載。
設置original_video_download
original_video_download控制是否下載原創微博中的視頻和原創微博Live Photo中的視頻,值為1代表下載,值為0代表不下載,如
"original_video_download": 1,
代表下載原創微博中的視頻和原創微博Live Photo中的視頻。
設置retweet_video_download
retweet_video_download控制是否下載轉發微博中的視頻和轉發微博Live Photo中的視頻,值為1代表下載,值為0代表不下載,如
"retweet_video_download": 0,
代表不下載轉發微博中的視頻和轉發微博Live Photo中的視頻。特別注意,本設置只有在爬全部微博(原創+轉發),即filter值為0時生效,否則程序會跳過轉發微博的視頻下載。
設置cookie(可選)
cookie為可選參數,即可填可不填,具體區別見添加cookie與不添加cookie的區別。cookie默認配置如下:
"cookie": "your cookie"
如果想要設置cookie,可以按照如何獲取cookie中的方法,獲取cookie,并將上面的"your cookie"替換成真實的cookie即可。
設置mysql_config(可選)
mysql_config控制mysql參數配置。如果你不需要將結果信息寫入mysql,這個參數可以忽略,即刪除或保留都無所謂;如果你需要寫入mysql且config.json文件中mysql_config的配置與你的mysql配置不一樣,請將該值改成你自己mysql中的參數配置。
4.設置數據庫(可選)
本部分是可選部分,如果不需要將爬取信息寫入數據庫,可跳過這一步。本程序目前支持MySQL數據庫和MongoDB數據庫,如果你需要寫入其它數據庫,可以參考這兩個數據庫的寫法自己編寫。
MySQL數據庫寫入
要想將爬取信息寫入MySQL,請根據自己的系統環境安裝MySQL,然后命令行執行:
$ pip install pymysql
MongoDB數據庫寫入
要想將爬取信息寫入MongoDB,請根據自己的系統環境安裝MongoDB,然后命令行執行:
$ pip install pymongo
MySQL和MongDB數據庫的寫入內容一樣。程序首先會創建一個名為"weibo"的數據庫,然后再創建"user"表和"weibo"表,包含爬取的所有內容。爬取到的微博用戶信息或插入或更新,都會存儲到user表里;爬取到的微博信息或插入或更新,都會存儲到weibo表里,兩個表通過user_id關聯。如果想了解兩個表的具體字段,請點擊"詳情"。
詳情user表
id:微博用戶id,如"1669879400";
screen_name:微博用戶昵稱,如"Dear-迪麗熱巴";
gender:微博用戶性別,取值為f或m,分別代表女和男;
statuses_count:微博數;
followers_count:粉絲數;
follow_count:關注數;
description:微博簡介;
profile_url:微博主頁,如https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400;
profile_image_url:微博頭像url;
avatar_hd:微博高清頭像url;
urank:微博等級;
mbrank:微博會員等級,普通用戶會員等級為0;
verified:微博是否認證,取值為true和false;
verified_type:微博認證類型,沒有認證值為-1,個人認證值為0,企業認證值為2,政府認證值為3,這些類型僅是個人猜測,應該不全,大家可以根據實際情況判斷;
verified_reason:微博認證信息,只有認證用戶擁有此屬性。
weibo表
user_id:存儲微博用戶id,如"1669879400";
screen_name:存儲微博昵稱,如"Dear-迪麗熱巴";
id:存儲微博id;
text:存儲微博正文;
pics:存儲原創微博的原始圖片url。若某條微博有多張圖片,則存儲多個url,以英文逗號分割;若該微博沒有圖片,則值為’’;
video_url:存儲原創微博的視頻url和Live Photo中的視頻url。若某條微博有多個視頻,則存儲多個url,以英文分號分割;若該微博沒有視頻,則值為’’;
location:存儲微博的發布位置。若某條微博沒有位置信息,則值為’’;
created_at:存儲微博的發布時間;
source:存儲微博的發布工具;
attitudes_count:存儲微博獲得的點贊數;
comments_count:存儲微博獲得的評論數;
reposts_count:存儲微博獲得的轉發數;
topics:存儲微博話題,即兩個#中的內容。若某條微博沒有話題信息,則值為’’;
at_users:存儲微博@的用戶。若某條微博沒有@的用戶,則值為’’;
retweet_id:存儲轉發微博中原始微博的微博id。若某條微博為原創微博,則值為’’。
5.運行腳本
大家可以根據自己的運行環境選擇運行方式,Linux可以通過
$ python weibo.py
運行;
6.按需求修改腳本(可選)
本部分為可選部分,如果你不需要自己修改代碼或添加新功能,可以忽略此部分。
本程序所有代碼都位于weibo.py文件,程序主體是一個Weibo類,上述所有功能都是通過在main函數調用Weibo類實現的,默認的調用代碼如下:
if not os.path.isfile('./config.json'):sys.exit(u'當前路徑:%s 不存在配置文件config.json' %(os.path.split(os.path.realpath(__file__))[0] + os.sep))with open('./config.json') as f:config = json.loads(f.read())wb = Weibo(config)wb.start() # 爬取微博信息
用戶可以按照自己的需求調用或修改Weibo類。
通過執行本程序,我們可以得到很多信息:
wb.user:存儲目標微博用戶信息;
wb.user包含爬取到的微博用戶信息,如用戶id、用戶昵稱、性別、微博數、粉絲數、關注數、簡介、主頁地址、頭像url、高清頭像url、微博等級、會員等級、是否認證、認證類型、認證信息等,大家可以點擊"詳情"查看具體用法。
id:微博用戶id,取值方式為wb.user[‘id’],由一串數字組成;
screen_name:微博用戶昵稱,取值方式為wb.user[‘screen_name’];
gender:微博用戶性別,取值方式為wb.user[‘gender’],取值為f或m,分別代表女和男;
statuses_count:微博數,取值方式為wb.user[‘statuses_count’];
followers_count:微博粉絲數,取值方式為wb.user[‘followers_count’];
follow_count:微博關注數,取值方式為wb.user[‘follow_count’];
description:微博簡介,取值方式為wb.user[‘description’];
profile_url:微博主頁,取值方式為wb.user[‘profile_url’];
profile_image_url:微博頭像url,取值方式為wb.user[‘profile_image_url’];
avatar_hd:微博高清頭像url,取值方式為wb.user[‘avatar_hd’];
urank:微博等級,取值方式為wb.user[‘urank’];
mbrank:微博會員等級,取值方式為wb.user[‘mbrank’],普通用戶會員等級為0;
verified:微博是否認證,取值方式為wb.user[‘verified’],取值為true和false;
verified_type:微博認證類型,取值方式為wb.user[‘verified_type’],沒有認證值為-1,個人認證值為0,企業認證值為2,政府認證值為3,這些類型僅是個人猜測,應該不全,大家可以根據實際情況判斷;
verified_reason:微博認證信息,取值方式為wb.user[‘verified_reason’],只有認證用戶擁有此屬性。
wb.weibo:存儲爬取到的所有微博信息;
wb.weibo包含爬取到的所有微博信息,如微博id、正文、原始圖片url、視頻url、位置、日期、發布工具、點贊數、轉發數、評論數、話題、@用戶等。如果爬的是全部微博(原創+轉發),除上述信息之外,還包含原始用戶id、原始用戶昵稱、原始微博id、原始微博正文、原始微博原始圖片url、原始微博位置、原始微博日期、原始微博工具、原始微博點贊數、原始微博評論數、原始微博轉發數、原始微博話題、原始微博@用戶等信息。wb.weibo是一個列表,包含了爬取的所有微博信息。wb.weibo[0]為爬取的第一條微博,wb.weibo[1]為爬取的第二條微博,以此類推。當filter=1時,wb.weibo[0]為爬取的第一條原創微博,以此類推。wb.weibo[0][‘id’]為第一條微博的id,wb.weibo[0][‘text’]為第一條微博的正文,wb.weibo[0][‘created_at’]為第一條微博的發布時間,還有其它很多信息不在贅述,大家可以點擊下面的"詳情"查看具體用法。
user_id:存儲微博用戶id。如wb.weibo[0][‘user_id’]為最新一條微博的用戶id;
screen_name:存儲微博昵稱。如wb.weibo[0][‘screen_name’]為最新一條微博的昵稱;
id:存儲微博id。如wb.weibo[0][‘id’]為最新一條微博的id;
text:存儲微博正文。如wb.weibo[0][‘text’]為最新一條微博的正文;
pics:存儲原創微博的原始圖片url。如wb.weibo[0][‘pics’]為最新一條微博的原始圖片url,若該條微博有多張圖片,則存儲多個url,以英文逗號分割;若該微博沒有圖片,則值為’’;
video_url:存儲原創微博的視頻url和原創微博Live Photo中的視頻url。如wb.weibo[0][‘video_url’]為最新一條微博的視頻url,若該條微博有多個視頻,則存儲多個url,以英文分號分割;若該微博沒有視頻,則值為’’;
location:存儲微博的發布位置。如wb.weibo[0][‘location’]為最新一條微博的發布位置,若該條微博沒有位置信息,則值為’’;
created_at:存儲微博的發布時間。如wb.weibo[0][‘created_at’]為最新一條微博的發布時間;
source:存儲微博的發布工具。如wb.weibo[0][‘source’]為最新一條微博的發布工具;
attitudes_count:存儲微博獲得的點贊數。如wb.weibo[0][‘attitudes_count’]為最新一條微博獲得的點贊數;
comments_count:存儲微博獲得的評論數。如wb.weibo[0][‘comments_count’]為最新一條微博獲得的評論數;
reposts_count:存儲微博獲得的轉發數。如wb.weibo[0][‘reposts_count’]為最新一條微博獲得的轉發數;
topics:存儲微博話題,即兩個#中的內容。如wb.weibo[0][‘topics’]為最新一條微博的話題,若該條微博沒有話題信息,則值為’’;
at_users:存儲微博@的用戶。如wb.weibo[0][‘at_users’]為最新一條微博@的用戶,若該條微博沒有@的用戶,則值為’’;
retweet:存儲轉發微博中原始微博的全部信息。假如wb.weibo[0]為轉發微博,則wb.weibo[0][‘retweet’]為該轉發微博的原始微博,它存儲的屬性與wb.weibo[0]一樣,只是沒有retweet屬性;若該條微博為原創微博,則wb[0]沒有"retweet"屬性,大家可以點擊"詳情"查看具體用法。
假設爬取到的第i條微博為轉發微博,則它存在以下信息:
user_id:存儲原始微博用戶id。wb.weibo[i-1][‘retweet’][‘user_id’]為該原始微博的用戶id;
screen_name:存儲原始微博昵稱。wb.weibo[i-1][‘retweet’][‘screen_name’]為該原始微博的昵稱;
id:存儲原始微博id。wb.weibo[i-1][‘retweet’][‘id’]為該原始微博的id;
text:存儲原始微博正文。wb.weibo[i-1][‘retweet’][‘text’]為該原始微博的正文;
pics:存儲原始微博的原始圖片url。wb.weibo[i-1][‘retweet’][‘pics’]為該原始微博的原始圖片url,若該原始微博有多張圖片,則存儲多個url,以英文逗號分割;若該原始微博沒有圖片,則值為’’;
video_url:存儲原始微博的視頻url和原始微博Live Photo中的視頻url。如wb.weibo[i-1][‘retweet’][‘video_url’]為該原始微博的視頻url,若該原始微博有多個視頻,則存儲多個url,以英文分號分割;若該微博沒有視頻,則值為’’;
location:存儲原始微博的發布位置。wb.weibo[i-1][‘retweet’][‘location’]為該原始微博的發布位置,若該原始微博沒有位置信息,則值為’’;
created_at:存儲原始微博的發布時間。wb.weibo[i-1][‘retweet’][‘created_at’]為該原始微博的發布時間;
source:存儲原始微博的發布工具。wb.weibo[i-1][‘retweet’][‘source’]為該原始微博的發布工具;
attitudes_count:存儲原始微博獲得的點贊數。wb.weibo[i-1][‘retweet’][‘attitudes_count’]為該原始微博獲得的點贊數;
comments_count:存儲原始微博獲得的評論數。wb.weibo[i-1][‘retweet’][‘comments_count’]為該原始微博獲得的評論數;
reposts_count:存儲原始微博獲得的轉發數。wb.weibo[i-1][‘retweet’][‘reposts_count’]為該原始微博獲得的轉發數;
topics:存儲原始微博話題,即兩個#中的內容。wb.weibo[i-1][‘retweet’][‘topics’]為該原始微博的話題,若該原始微博沒有話題信息,則值為’’;
at_users:存儲原始微博@的用戶。wb.weibo[i-1][‘retweet’][‘at_users’]為該原始微博@的用戶,若該原始微博沒有@的用戶,則值為’’。
如何獲取user_id
1.打開網址https://weibo.cn,搜索我們要找的人,如"迪麗熱巴",進入她的主頁;
2.按照上圖箭頭所指,點擊"資料"鏈接,跳轉到用戶資料頁面;
如上圖所示,迪麗熱巴微博資料頁的地址為"https://weibo.cn/1669879400/info",其中的"1669879400"即為此微博的user_id。
事實上,此微博的user_id也包含在用戶主頁(https://weibo.cn/u/1669879400?f=search_0)中,之所以我們還要點擊主頁中的"資料"來獲取user_id,是因為很多用戶的主頁不是"https://weibo.cn/user_id?f=search_0"的形式,而是"https://weibo.cn/個性域名?f=search_0"或"https://weibo.cn/微號?f=search_0"的形式。其中"微號"和user_id都是一串數字,如果僅僅通過主頁地址提取user_id,很容易將"微號"誤認為user_id。
添加cookie與不添加cookie的區別(可選)
對于大部分微博用戶,不添加cookie也可以獲取其用戶信息和大部分微博,不同的微博獲取比例不同。以2020年1月2日迪麗熱巴的微博為例,此時她共有1085條微博,在不添加cookie的情況下,可以獲取到1026條微博,大約占全部微博的94.56%,而在添加cookie后,可以獲取全部微博。其他用戶類似,大部分都可以在不添加cookie的情況下獲取到90%以上的微博,在添加cookie后可以獲取全部微博。具體原因是,大部分微博內容都可以在移動版匿名獲取,少量微博需要用戶登錄才可以獲取,所以這部分微博在不添加cookie時是無法獲取的。
有少部分微博用戶,不添加cookie可以獲取其微博,無法獲取其用戶信息。對于這種情況,要想獲取其用戶信息,是需要cookie的。
如何獲取cookie(可選)
1.用Chrome打開https://passport.weibo.cn/signin/login;
2.輸入微博的用戶名、密碼,登錄,如圖所示:
登錄成功后會跳轉到https://m.weibo.cn;
3.按F12鍵打開Chrome開發者工具,在地址欄輸入并跳轉到https://weibo.cn,跳轉后會顯示如下類似界面:
4.依此點擊Chrome開發者工具中的Network->Name中的weibo.cn->Headers->Request Headers,"Cookie:"后的值即為我們要找的cookie值,復制即可,如圖所示:
如何檢測cookie是否有效(可選)
因為對于大部分微博用戶,本程序添不添加cookie,cookie正確與否都可以運行并獲取微博信息,所以使用者很難通過觀察檢測cookie是否有效。目前有兩種方式檢測cookie值是否有效,大家從下面兩種方法中選擇一種就可以:
1.爬取特定用戶,將user_id設置為2218081121,即
"user_id_list": ["2218081121"],
運行程序,如果程序提示cookie無效等類似信息,說明cookie無效,否則cookie是有效的;
2.將獲取的cookie填到cookie版的config.json中,運行程序。如果程序提示cookie無效等相關信息,說明cookie無效,否則cookie是有效的。因為cookie版中cookie為必需項,且cookie版與免cookie版的cookie通用。



)
)















