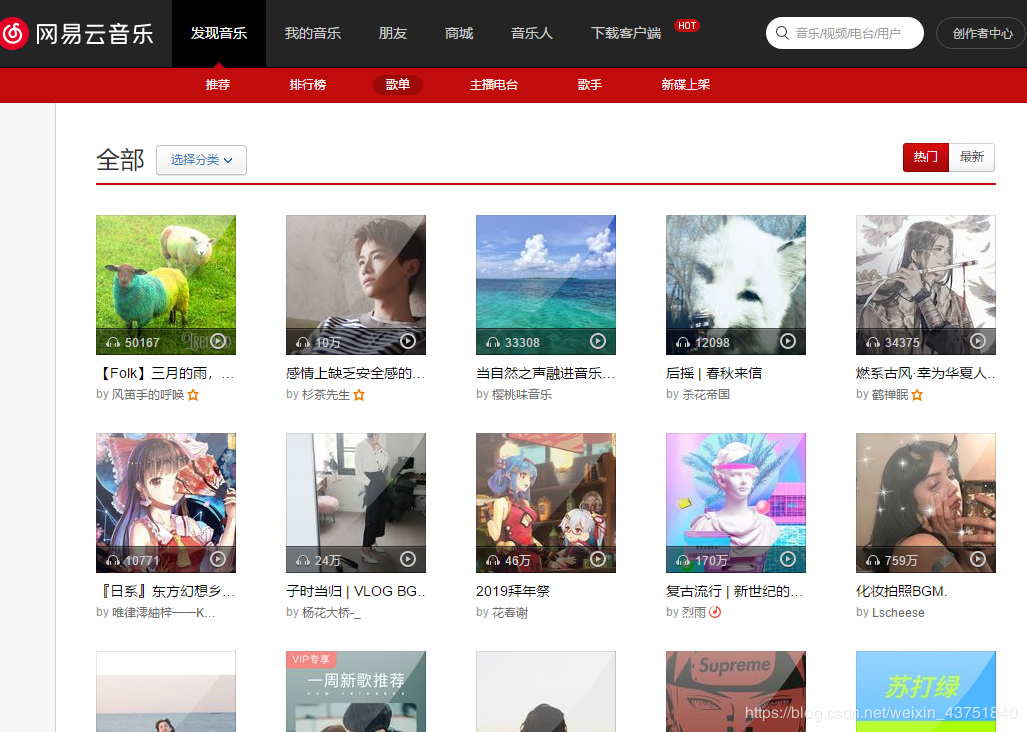
目標網站:
首先獲取第一頁的數據,這里關鍵要切換到iframe里
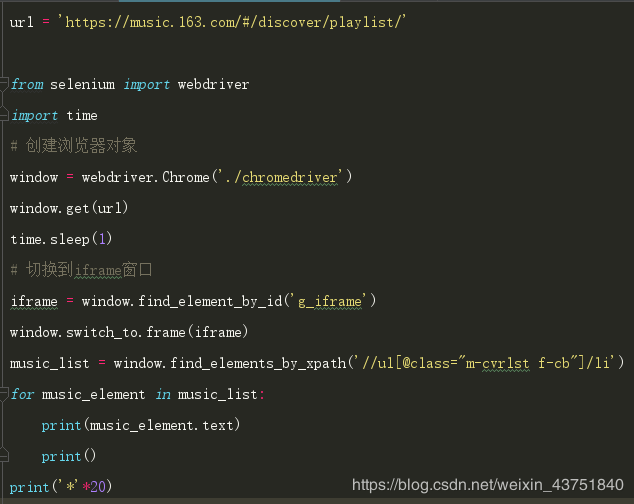
打印一下

獲取剩下的頁數,這里在點擊下一頁之前需要設置一個延遲,不然會報錯。
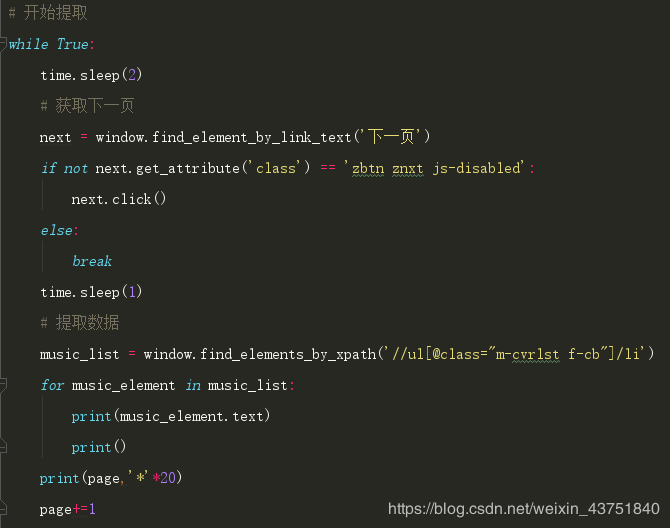
結果:

一共37頁,爬取完畢后關閉瀏覽器
完整代碼:
url = 'https://music.163.com/#/discover/playlist/'
from selenium import webdriver
import time
# 創建瀏覽器對象
window = webdriver.Chrome('./chromedriver')
window.get(url)
time.sleep(1)
# 切換到iframe窗口
iframe = window.find_element_by_id('g_iframe')
window.switch_to.frame(iframe)
music_list = window.find_elements_by_xpath('//ul[@class="m-cvrlst f-cb"]/li')
for music_element in music_list:
print(music_element.text)
print()
print('*'*20)
page = 1
# 開始提取
while True:
time.sleep(2)
# 獲取下一頁
next = window.find_element_by_link_text('下一頁')
if not next.get_attribute('class') == 'zbtn znxt js-disabled':
next.click()
else:
break
time.sleep(1)
# 提取數據
music_list = window.find_elements_by_xpath('//ul[@class="m-cvrlst f-cb"]/li')
for music_element in music_list:
print(music_element.text)
print()
print(page,'*'*20)
page+=1
# 退出瀏覽器
window.quit()
以上所述是小編給大家介紹的python selenium爬取網易云音樂歌單名詳解整合,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對腳本之家網站的支持!






)












