轉載請注明出處:http://www.cnblogs.com/Peyton-Li/
樸素貝葉斯法是機器學習模型中一個比較簡單的模型,實現簡單,比較常用。
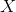 是定義在輸入空間
是定義在輸入空間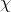 上的隨機向量,
上的隨機向量,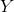 是定義在輸出空間
是定義在輸出空間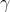 上的隨機變量。
上的隨機變量。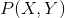 是
是 和
和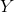 的聯合概率分布。訓練數據集
的聯合概率分布。訓練數據集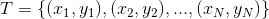 由
由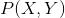 獨立同分布產生。
獨立同分布產生。
樸素貝葉斯法通過訓練數據集學習聯合概率分布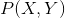 。具體地,學習一下先驗概率分布及條件概率分布。
。具體地,學習一下先驗概率分布及條件概率分布。
先驗概率分布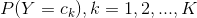 ,條件概率分布
,條件概率分布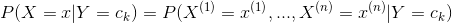 ,
,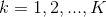 ,于是學習到聯合概率分布
,于是學習到聯合概率分布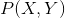 。
。
條件概率分布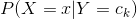 有指數級數量的參數,其估計實際是不可行的。事實上,假設
有指數級數量的參數,其估計實際是不可行的。事實上,假設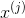 可取值有
可取值有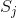 個,
個,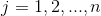 ,
, 可取值有
可取值有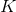 個,那么參數個數為
個,那么參數個數為 。
。
樸素貝葉斯法對條件概率分布作了條件獨立性的假設。由于這是一個較強的假設,樸素貝葉斯法也由此得名。具體的,條件獨立性假設是
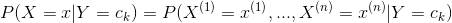
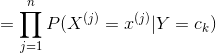 (4.3)
(4.3)
樸素貝葉斯法實際上學習到生成數據的機制,所以屬于生成模型。條件獨立假設等于是說用于分類的特征在類確定的條件下都是條件獨立的。這一假設使樸素貝葉斯法變得簡單,但有時會犧牲一定的分類準確率。
樸素貝葉斯法分類時,對給定的輸入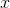 ,通過學習得到的模型計算后驗概率分布
,通過學習得到的模型計算后驗概率分布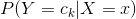 ,將后驗概率最大的類作為
,將后驗概率最大的類作為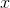 的類輸出。后驗概率計算根據貝葉斯定理進行:
的類輸出。后驗概率計算根據貝葉斯定理進行:
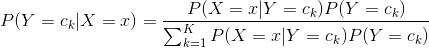 (4.4)
(4.4)
將式(4.3)帶入(4.4)有
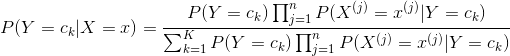 (4.5)
(4.5)
這是樸素貝葉斯法分類的基本公式。于是,樸素貝葉斯分類器可表示為
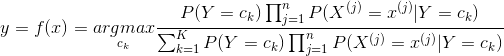 (4.6)
(4.6)
注意到,在式(4.6)中分母對所有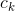 都是相同的,所以,
都是相同的,所以,
 (4.7)
(4.7)
樸素貝葉斯法將實例分到后驗概率最大的類中。這等價于期望風險最小化。假設選擇0-1損失函數:
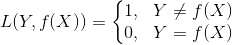
式中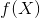 是分類決策函數。這時,期望風險函數為
是分類決策函數。這時,期望風險函數為
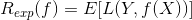
期望是對聯合分布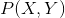 取的。由此取條件期望
取的。由此取條件期望
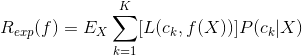
為了使期望風險最小化,只需對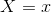 逐個極小化,由此得到:
逐個極小化,由此得到:

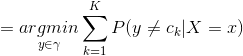
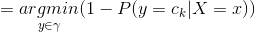
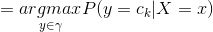
這樣一來,根據期望風險最小化準則就得到了后驗概率最大化準則:
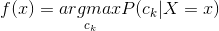 (4.8)
(4.8)
即樸素貝葉斯法所采用的原理。(注意將4.7式和4.8式對比)
?
在樸素貝葉斯法中,學習意味著估計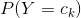 和
和 。可以應用極大似然估計法估計相應的概率。先驗概率
。可以應用極大似然估計法估計相應的概率。先驗概率 的極大似然估計是
的極大似然估計是
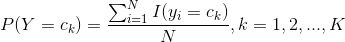
?
設第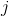 個特征
個特征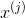 可能取值的集合為
可能取值的集合為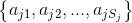 ,條件概率
,條件概率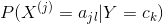 的極大似然估計是
的極大似然估計是

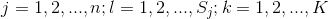
式中,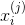 是第
是第 個樣本的第
個樣本的第 個特征;
個特征;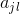 是第
是第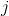 個特征可能取的第
個特征可能取的第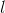 個值;
個值; 為指示函數。
為指示函數。
對于給定的實例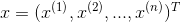 ,計算
,計算
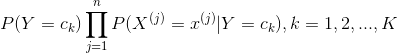
確定實例 的類
的類

?
用極大似然估計可能會出現所要估計的概率值為0的情況。這是會影響到后驗概率的計算結果,使分類產生偏差。解決這一問題的方法是采用貝葉斯估計。具體地,條件概率的貝葉斯估計是
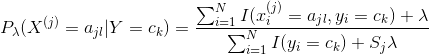 (4.10)
(4.10)
式中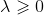 。等價于在隨機變量各個取值的頻數上賦予一個正數
。等價于在隨機變量各個取值的頻數上賦予一個正數 。當
。當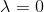 時就是極大似然估計。常取
時就是極大似然估計。常取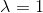 ,這是稱為拉普拉斯平滑(Laplace smoothing)。顯然,對任何
,這是稱為拉普拉斯平滑(Laplace smoothing)。顯然,對任何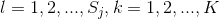 ,有
,有
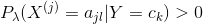
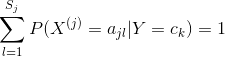
表明式(4.10)確為一種概率分布。同樣,先驗概率的貝葉斯估計是
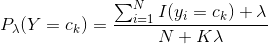
樸素貝葉斯分類有一個限制條件,就是特征屬性必須有條件獨立或基本獨立(實際上在現實應用中幾乎不可能做到完全獨立)。
優點:
1、樸素貝葉斯模型發源于古典數學理論,有穩定的分類效率。
2、對小規模的數據表現很好,能個處理多分類任務,適合增量式訓練,尤其是數據量超出內存時,我們可以一批批的去增量訓練。
3、對缺失數據不太敏感,算法也比較簡單,常用于文本分類。
缺點:
1、理論上,樸素貝葉斯模型與其他分類方法相比具有最小的誤差率。但是實際上并非總是如此,這是因為樸素貝葉斯模型假設屬性之間相互獨立,這個假設在實際應用中往往是不成立的,在屬性個數比較多或者屬性之間相關性較大時,分類效果不好。而在屬性相關性較小時,樸素貝葉斯性能最為良好。對于這一點,有半樸素貝葉斯之類的算法通過考慮部分關聯性適度改進。
2、需要知道先驗概率,且先驗概率很多時候取決于假設,假設的模型可以有很多種,因此在某些時候會由于假設的先驗模型的原因導致預測效果不佳。
3、由于我們是通過先驗和數據來決定后驗的概率從而決定分類,所以分類決策存在一定的錯誤率。對輸入數據的表達形式很敏感。
?














)



...)
