系統設計說明書(架構、概要、詳細)目錄結構
雖然這些文檔一般來說公司都是有模板的,但我寫這些文檔以來基本上是每寫一次就把目錄結構給改一次,應該說這是因為自己對這些文檔的理解開始加深,慢慢的越來越明白這些文檔的作用和其中需要闡述的東西,覺得這三份文檔主要闡述了一個系統的設計和實現過程,從系統分解為層次、層次內的模塊以及相互的接口、模塊分解為對象以及對象的接口、實現這些對象接口的方法。這次又整了一份,^_^,歡迎大家指正。XXX架構設計說明書
(架構設計重點在于將系統分層并產生層次內的模塊、闡明模塊之間的關系)
一.? 概述
描述本文的參考依據、資料以及大概內容。
二.? 目的
描述本文編寫的目的。
三.? 架構設計
闡明進行架構設計的總體原則,如對問題域的分析方法。
3.1.?????? 架構分析
對場景以及問題域進行分析,構成系統的架構級設計,闡明對于系統的分層思想。
3.2.?????? 設計思想
闡明進行架構設計的思想,可參考一些架構設計的模式,需結合當前系統的實際情況而定。
3.3.?????? 架構體系
根據架構分析和設計思想產生系統的架構圖,并對架構圖進行描述,說明分層的原因、層次的職責,并根據架構圖繪制系統的物理部署圖,描述系統的部署體系。
3.4.?????? 模塊劃分
根據架構圖進行模塊的劃分并闡明模塊劃分的理由,繪制模塊物理圖以及模塊依賴圖。
3.4.1.?????? 模塊描述
根據模塊物理圖描述各模塊的職責,并聲明其對其他模塊的接口要求。。
3.4.2.?????? 模塊接口設計
對模塊接口進行設計,并提供一定的偽代碼。
XXX概要設計說明書
(概要設計重點在于將模塊分解為對象并闡明對象之間的關系)
一.? 概述
描述本文的參考依據、資料以及大概內容。
二.? 目的
描述本文的編寫目的。
三.? 模塊概要設計
引用架構設計說明書中的模塊圖,并闡述對于模塊進行設計的大致思路。
3.1.?????? 設計思想
闡明概要設計的思想,概要設計的思想通常是涉及設計模式的。
3.2.?????? 模塊A
3.2.1.?????? 概要設計
根據該模塊的職責對模塊進行概要設計(分解模塊為對象、描述對象的職責以及聲明對象之間的接口),繪制模塊的對象圖、對象間的依賴圖以及模塊主要功能的序列圖,分別加以描述并相應的描述模塊異常的處理方法。
3.2.2.?????? 模塊接口實現
闡明對于架構設計中定義的模塊接口的實現的設計。
XXX詳細設計說明書
(詳細設計重點在于對模塊進行實現,將模塊的對象分解為屬性和方法,并闡述如何實現)
一.? 概述
闡述本文的參考依據、資料以及大概內容。
二.? 目的
闡述本文的編寫目的。
三.? 模塊詳細設計
3.1.?????? 設計思想
闡述對模塊進行詳細設計的思想。
3.2.?????? 模塊A
3.2.1.?????? 詳細設計
根據模塊概要設計詳細描述對于模塊內對象的實現,包括對象的職責、屬性、方法、對象內功能的流程圖、對象關聯的類、對象的異常。(需要繪制的主要為類圖)
在大型的項目中是有必要分開的....
架構解決系統核心用例以及關鍵性需求的設計,形成抽象的基礎結構,劃分模塊、形成模塊接口.
概要解決模塊以及模塊接口的實現,形成模塊中核心對象以及對象的接口定義..
詳細解決模塊中具體對象的實現以及對象接口的實現
演進架構中的領域驅動設計
原文鏈接:http://www.infoq.com/cn/articles/ddd-evolving-architecture
作者Mat Wall and Nik Silver譯者王麗娟發布于2009年9月21日 上午11時9分
領域驅動設計能非常容易地應用于穩定領域,其中的關鍵活動適合開發人員對用戶腦海中的內容進行記錄和建模。但在領域本身不斷變化和發展的情況下,領域驅動設計變得更具有挑戰性。這在敏捷項目中很普遍,在業務本身試圖演進的時候也會發生。本文分析了在反思、重建guardian.co.uk這一為期兩年的計劃背景下我們是如何利用DDD的。我們展示了如何確保在軟件架構中反映最終用戶演變的認知,以及怎樣實現該架構來保證以后的變化。我們提供了模型中重要項目過程、具體演進步驟的細節。
相關廠商內容
【入門】如何完成一次基于TOP的完整開發測試
【進階】通過淘寶網平臺做個淘寶客網站
【進階】通過淘寶網平臺做個外部獨立網店
【下載】淘寶開放平臺PHP SDK改進版V0.1
【 直播】淘寶開放平臺應用審核全過程
相關贊助商

參與贏在淘寶活動,解析淘寶開放平臺,讓商業創意和技術完美地合二為一!現在點擊瀏覽淘寶開發者社區
頂層標題:
- 計劃背景
- 從DDD開始
- 增量計劃中的DDD過程
- 進化的領域模型
- 代碼級別的演進
- 演進架構中DDD的一些教訓
- 附錄:具體示例
1. 計劃背景
Guardian.co.uk有相當長的新聞、評論、特性歷史記錄,目前已擁有超過1800萬的獨立用戶和每月1.8億的頁面訪問量。在此期間的大部分時間,網站都運行在原始的Java技術之上,但在2006年2月開始了一項重要的工作計劃——將網站移植到一個更現代的平臺上去,計劃的最初階段于2006年11月推出,當時推出了具有新外觀的旅游網站,接著在2007年5月推出新的主頁,之后相繼推出了更多內容。盡管在2006年2月僅有少數幾個人在做這項工作,但后來團隊最多曾達到了104人。
然而,計劃的動機遠不止是要一個新外觀。多年的經驗告訴我們有更好的辦法來組織我們的內容,有更好的方式將我們的內容商業化,以及在此背后,還有更先進的開發方法——這才是關鍵之所在。
其實,我們考慮工作的方式已超越了我們軟件可以處理的內容。這就是為什么DDD對我們來說如此有價值。
遺留軟件中阻礙我們的概念不匹配有兩個方面,我們先簡單看一下這兩方面問題,首先是我們的內部使用者,其次是我們的開發人員。這些問題都需要借助DDD予以解決。
1.1. 內部使用者的問題
新聞業是一個古老的行業,有既定的培訓、資格和職制,但對新聞方面訓練有素的新編輯來說,加入我們的行列并使用Web工具有效地工作是不可能的,尤其在剛來的幾個月里。要成為一個高效的使用者,了解我們CMS和網站的關鍵概念還遠遠不夠,還需要了解它們是如何實現的。
比如說,將緩存內容的概念(這應該完全是系統內部的技術優化)暴露給編輯人員;編輯們要將內容放置在緩存中以確保內容已準備好,還需要理解緩存工作流以用CMS工具診斷和解決問題。這顯然是對編輯人員不合理的要求。
1.2. 開發人員的問題
概念上的不匹配也體現在技術方面。舉例來說,CMS有一個概念是“制品”,這完全是所有開發人員每天工作的核心。以前團隊中的一個人坦言,在足足九個月之后他才認識到這些“制品”其實就是網頁。圍繞“制品”形成的含義模糊的語言和軟件越來越多,這些東西讓他工作的真正性質變得晦澀難懂。
再舉一個例子,生成我們內容的RSS訂閱特別耗時。盡管各個版塊的主頁都包含一個清晰的列表,里面有主要內容和附加內容,但底層軟件并不能對兩者予以區分。因此,從頁面抽取RSS訂閱的邏輯是混亂的,比如“在頁面上獲取每個條目,如果它的布局寬大約一半兒、長度比平均長度長一些,那它可能是主要內容,這樣我們就能抽取鏈接、將其作為一個訂閱”。
很顯然,對我們來說,人們對他們工作(開始、網頁和RSS訂閱)及其如何實現(緩存工作流、“制品”、混亂邏輯)的認識之間的分歧給我們的效益造成了明顯而慘重的影響。
2. 從DDD開始
本部分闡述了我們使用DDD的場景:為什么選擇它,它在系統架構中所處的位置,還有最初的領域模型。在后面的章節中,我們會看一下如何把最初的領域知識傳播給擴充的團隊,如何演進模型,以及如何以此為中心來演進我們的編碼技術。
2.1. 選擇DDD
DDD所倡導的首要方面就是統一一致的語言,以及在代碼中直接體現用戶自己的概念。這能有效地解決前面提及的概念上的不匹配問題。單獨看來,這是一個有價值的見解,但其本身價值或許并不比“正確使用面向對象技術”多很多。
使其深入的是DDD引入的技術語言和概念:實體、值對象、服務、資源庫等。這確保了在處理非常大的項目時,我們的大型開發團隊有可能一致地進行開發——長遠來看,這對維護質量是必不可少的。甚至在廢棄我們更底層的代碼時(我們稍后會進行演示),統一的技術語言能讓我們恢復到過去、改進代碼質量。
2.2. 在系統中嵌入領域模型
本節顯示了DDD在整個系統架構中的地位。
我們的系統逐漸建立了三個主要的組件:渲染應用的用戶界面網站;面向編輯、用于創建和管理內容的應用程序;跟系統交互數據的供稿系統。這些應用都是基于Spring和Hibernate構建的Java Web應用,并使用Velocity作為我們的模板語言。
我們可以看下這些應用的布局:

Hibernate層提供數據訪問,使用EHCache作為Hibernate的二級緩存。模型層包含領域對象和資源庫,服務則處于其上一層。在此之上,我們有Velocity模板層,它提供頁面渲染邏輯。最頂層則包含控制器,是應用的入口點。
看一下這個應用的分層架構,僅僅將模型當做是應用的一個自包含的層是很有意思的。這個想法大致正確,但模型層和其它層之間還是有一些細微的差別:由于我們使用領域驅動設計,所以我們需要統一語言,不僅要在我們談論領域時使用,還要在應用的任何地方使用。模型層的存在不僅是為了從渲染邏輯中分離業務邏輯,還要為使用的其它層提供詞匯表。
另外,模型層可作為代碼的獨立單元進行構建,而且可以作為JAR包導入到依賴于它的許多應用中。其它任何層則不是這樣。對構建和發布應用來說,這意味著:在我們基礎設施的模型層改變代碼一定是跨所有應用的全局變化。我們可以在前端的網站中改變Velocity模板,只用部署前端應用就可以,管理系統或供稿系統則不用。如果我們在領域模型中改變了一個對象的邏輯,我們必須更新所有依賴于模型的應用,因為我們只有(而且期望只有)一個領域視圖。
這有一種危害,就是領域建模的這種方法可能會導致單一模型,如果業務領域非常龐大,改變起來的代價會非常昂貴。我們認識到了這一點,因此隨著領域不斷增長,我們必須確保該層沒有變得太過笨重。目前,雖然領域層也是相當龐大和復雜的,但是這還沒有帶來什么問題。在敏捷環境中工作,我們希望無論如何每兩周都要推出所有系統的最新變化。但我們持續關注著該層代碼改變的成本。如果成本上升到不能接受的程度,我們可能會考慮將單一模型細分成多個更小的模型,并在每個子模型之間給出適配層。但是我們在項目開始時沒有這樣做,我們更偏向于單一模型的簡單性,而不是用多個模型時必須解決的更為復雜的依賴管理問題。
2.3. 早期的領域建模
在項目初期,大家在鍵盤上動手開始編寫代碼之前,我們就決定讓開發人員、QA、BA、業務人員在同一個房間里一起工作,以便項目能夠持續。在這個階段我們有一個由業務人員和技術人員組成的小型團隊,而且我們只要求有一個穩妥的初次發布。這確保了我們的模型和過程都相當簡單。
我們的首要目標是讓編輯(我們業務代表的關鍵組成部分)就項目最初迭代的期望有一個清楚的認識。我們跟編輯們坐在一起,就像一個整體團隊一樣,用英語與他們交流想法,允許各個功能的代表對這些想法提出質疑和澄清,直到他們認為我們正確理解了編輯需要的內容。
我們的編輯認為,項目初期優先級最高的功能是系統能生成網頁,這些網頁能顯示文章和文章分類系統。
他們最初的需求可歸納為:
- 我們應該能將一篇文章和任何給定的URL關聯起來。
- 我們要能改變選定的不同模板渲染結果頁面的方式。
- 為了管理,我們要將內容納入寬泛的版面,也就是新聞、體育、旅游。
- 系統必須能顯示一個頁面,該頁面包含指向特定分類中所有文章的鏈接。
我們的編輯需要一種非常靈活的方式來對文章進行分類。他們采用了基于關鍵字的方法。每個關鍵字定義了一個與內容相關的主題。每篇文章可以和很多關鍵字關聯,因為一篇文章可以有很多主題。
我們網站有很多編輯,每個人負責不同版塊的內容。每個版塊都要求有自己導航和特有關鍵字的所有權。
從編輯使用的語言來看,我們似乎在領域中引入了一些關鍵實體:
- 頁面 URL的擁有者。負責選擇模板來渲染內容。
- 模板 頁面布局,任何時候都有可能改變。技術人員將每個模板實現為磁盤上的一個Velocity文件。
- 版塊 頁面更寬泛的分類。每個版塊有一個編輯,還有對其中頁面共同的感官。新聞、旅游和商業都是版塊的例子。
- 關鍵字 描述存在于版塊中主題的方式。關鍵字過去用于文章分類,現在則驅動自動導航。這樣它們將與某個頁面關聯,關于給定主題所有文章的自動頁面也能生成。
- 文章 我們能發布給用戶的一段文本內容。
提取這些信息后,我們開始對領域建模。項目早期做出的一個決定:編輯擁有領域模型并負責設計,技術團隊則提供協助。對過去不習慣這種技術設計的編輯來說,這是相當大的轉變。我們發現,通過召開由編輯、開發人員、技術架構師組成的研習會,我們能用簡單、技術含量較低的方法勾畫出領域模型,并對它持續演進。討論模型的范圍,使用鋼筆、檔案卡和Blu-Tak繪制備選解決方案。每個候選模型都會進行討論,技術團隊把設計中的每個細節含義告訴給編輯。
盡管過程在最初相當緩慢,但很有趣。編輯發現這非常容易上手;他們能信手拈來、提出對象,然后及時從開發人員那里獲得反饋,以知道生成的模型是否滿足了他們的需求。對于編輯們能在過程中迅速掌握技術的要領,技術人員都感到很驚喜,而且所有人都對生成的系統是否能滿足客戶需求很有信心。
觀察領域語言的演變也很有趣。有時文章對象會被說成是“故事”。顯然對于同一實體的多個名稱,我們并沒有一種統一語言,這是一個問題。是我們的編輯發現他們描述事物時沒有使用統一的語言,也是他們決心稱該對象為文章。后來,任何時間有人說“故事”,就會有人說:“你的意思不是文章嗎?”在設計統一語言時,持續、公共的改進過程是種很強大的力量。
我們的編輯最初設計生成的模型是這樣的:

[網頁及其版塊之間的關系由應用于文章的關鍵字導出,文章是網頁中的核心內容。網頁的版塊由應用于文章的首個關鍵字的版塊確定。]
由于并非所有的團隊成員都參與了該過程的所有階段,所以我們需要向他們介紹工作進展,并將這些全部展現在了墻上。然后開發人員開始了敏捷開發之旅,而且由于編輯和開發人員、BA、QA都在一起工作,任何有關模型及其意圖的問題都能在開發過程的任何時候獲得第一手的可靠信息。
經過幾次迭代之后系統初具形態,我們還建立工具來創建和管理關鍵字、文章和頁面。隨著這些內容的創建,編輯們很快掌握了它們,并且給出了一些修改建議。大家普遍認為這一簡單的關鍵模型能正常運行,而且可以繼續下去、形成網站初次發布的基礎。
3. 增量計劃中的DDD過程
首次發布之后,我們的項目團隊伴隨著技術人員和業務代表們的成長,一起取得了進步,打算演進領域模型。很顯然,我們需要一種有組織的方式來為領域模型引入新的內容、進行系統的演進。
3.1. 新員工入門
DDD是入門過程中的核心部分。非技術人員在整個項目生命周期內都會加入項目,因為工作計劃是橫跨各個編輯領域的,反過來,在恰當的時機我們也會引入版面編輯。技術人員很容易就能加入項目,因為我們持續不斷地雇用新員工。
我們的入門過程包括針對這兩類人的DDD講習,盡管細節不同,但高層次的議題涵蓋兩個相同的部分:DDD是什么,它為什么重要;領域模型本身的特定范圍。
描述DDD時我們強調的最重要的內容有:
- 領域模型歸業務代表所有。這就要從業務代表的頭腦里抽象概念,并將這些概念嵌入到軟件中,而不能從軟件的角度思考,并試圖影響業務代表。
- 技術團隊是關鍵的利益相關者。我們將圍繞具體細節據理力爭。
覆蓋領域模型的特定范圍本身就很重要,因為它予以就任者處理項目中特定問題的真正工具。我們的領域模型中有幾十個對象,所以我們只關注于高級別和更為明顯的少數幾個,在我們的情況中就是本文所討論的各種內容和關鍵字概念。在這里我們做了三件事:
- 我們在白板上畫出了概念及其關系,因此我們能給出系統如何工作的一個有形的表示。
- 我們確保每位編輯當場解釋大量的領域模型,以強調領域模型不屬于技術團隊所有這一事實。
- 我們解釋一些為了達到這一點而做出的歷史變遷,所以就任者可以理解(a)這不是一成不變的,而是多變的,(b)為了進一步開發模型,他們可以在即將進行的對話中扮演什么樣的角色。
3.2. 規劃中的DDD
入門是必不可少的,不過在開始計劃每次迭代的時候,知識才真正得以實踐。
3.2.1 使用統一語言
DDD強制使用的統一語言使得業務人員、技術人員和設計師能圍坐在一起規劃并確定具體任務的優先次序。這意味著有很多會議與業務人員有關,他們更接近技術人員,也更加了解技術過程。有一位同事,她先擔任項目的編輯助理,然后成長為關鍵的決策者;她解釋說,在迭代啟動會議上她親自去看技術人員怎樣判斷和(激烈地)評估任務,開始更多地意識到功能和努力之間的平衡。如果她不和技術團隊共用一種語言,她就不會一直出席會議,也不會收獲那些認識。
在規劃階段利用DDD時我們使用的兩個重要原則是:
- 領域模型歸屬于業務;
- 領域模型需要一個權威的業務源。
領域模型的業務所有權在入門中就進行了解釋,但在這里才發揮作用。這意味著技術團隊的關鍵角色是聆聽并理解,而不是解釋什么可能、什么不可能。需求抽象要求將概念性的領域模型映射到具體的功能需求上,并在存在不匹配的地方對業務代表提出異議或進行詢問。接著,存在不匹配的地方要么改變領域模型,要么在更高層次上解決功能需求(“你想用此功能達成什么效果?”)。
對領域模型來說,權威的業務源是我們組織的性質所明確需要的。我們正在構建一個獨立的軟件平臺,它需要滿足很多編輯團隊的需求,編輯團隊不一定以同樣的方式來看世界。Guardian不實行許多公司實行的“命令和控制”結構;編輯臺則有很多自由,也能以他們認為合適的方式去開發自己的網站版面,并設定預期的讀者。因此,不同的編輯對領域模型會有略微不同的理解和觀點,這有可能會破壞單一的統一語言。我們的解決辦法是確定并加入業務代表,他們在整個編輯臺都有責任。對我們來說,這是生產團隊,是那些處理日常構建版面、指定布局等技術細節的人。他們是文字編輯依賴的超級用戶,作為專家工具建議,因此技術團隊認為他們是領域模型的持有者,而且他們保證軟件中大部分的一致性。他們當然不是唯一的業務代表,但他們是與技術人員保持一致的人員。
3.2.2 與DDD一起計劃的問題
不幸的是,我們發現了在計劃過程中應用DDD特有的挑戰,尤其是在持續計劃的敏捷環境中。這些問題是:
- 本質上講,我們正在將軟件寫入新的、不確定商業模式中;
- 綁定到一個舊模型;
- 業務人員“入鄉隨俗”。
我們反過來討論下這些問題……
EricEvans撰寫關于創建領域模型的文章時,觀點是業務代表的腦海中存在著一個模型,該模型需要提取出來;即便他們的模型不明確,他們也明白核心概念,而且這些概念基本上能解釋給技術人員。然而在我們的情況中,我們正在改變我們的模型——事實上是在改變我們的業務——但并不知道我們目標的確切細節。(馬上我們就會看到這一點的具體例子。)某些想法顯而易見,也很早就建立起來了(比如我們會有文章和關鍵字),但很多并不是這樣(引入頁面的想法還有一些阻力;關鍵字如何關聯到其它內容則完全是各有各的想法)。我們的教科書并沒有提供解決這些問題的指南。不過,敏捷開發原則則可以:
- 構建最簡單的東西。盡管我們無法在早期解決所有的細節,但通常能對構建下一個有用的功能有足夠的理解。
- 頻繁發布。通過發布此功能,我們能看到功能如何實際地運轉。進一步的調整和進化步驟因此變得最為明顯(不可避免,它們往往不是我們所預期的)。
- 降低變化的成本。利用這些不可避免的調整和進化步驟,減少變化的成本很有必要。對我們來說這包括自動化構建過程和自動化測試等。
- 經常重構。經過幾個演進步驟,我們會看到技術債務累積,這需要予以解決。
與此相關的是第二個問題:與舊模型有太多的精神聯系。比如說,我們的遺留系統要求編輯和制作人員單獨安排頁面布局,而新系統的愿景則是基于關鍵字自動生成頁面。在新系統里,Guantánamo Bay頁面無需任何人工干預,許多內容會給出GuantánamoBay關鍵字,僅簡單地憑借這一事實就能顯示出來。但結果卻是,這只是由技術團隊持有的過度機械化的愿景,技術團隊希望減少體力勞動和所有頁面的持續管理。相比之下,編輯人員高度重視人的洞察力,他們帶入過程的不僅有記述新聞,還有展現新聞;對他們來說,為了突出最重要的故事(而不僅僅是最新的),為了用不同的方法和靈敏性(比如9·11和Web 2.0報導)區別對待不同的主題,個人的布局是很有必要的。
對這類問題沒有放之四海而皆準的解決辦法,但我們發現了兩個成功的關鍵:專注于業務問題,而不是技術問題;銘記“創造性沖突”這句話。在這里的例子里,見解有分歧,但雙方表達了他們在商業上的動機后,我們就開始在同一個環境里面工作了。該解決方案是創造性的,源于對每個人動機的理解,也因此解決了大家了疑慮。在這種情況下,我們構建了大量的模板,每個都有不同的感覺和影響等,編輯可以從中選擇并切換。此外,每個模板的關鍵區域允許手動選擇顯示的故事、頁面的其余部分自動生成內容(小心不要重復內容),對于該手動區域,如果管理變得繁重,就可以隨時關閉,從而使網頁完全自動化。
我們發現的第三個挑戰是隨著業務人員“入鄉隨俗”,也就是說他們已深深融入技術且牽涉到了要點,以至于他們會忘記對新使用系統的內部用戶來說,系統該是什么樣。當業務代表發現跟他們的同事很難溝通事情如何運轉,或者很難指出價值有限的功能時,就有危險的信號了。KentBeck在《解析極限編程》第一版中說,現場客戶與技術團隊直接交互絕不會占用他們很多的時間,通過強調這一點,就可以保證在現場的客戶。但我們在與有幾十個開發人員、多名BA、多名QA的團隊一起工作時,我們發現即使有三個全職的業務代表,有時也是不夠的。由于業務人員花費了太多的時間與技術人員在一起,以至他們與同事失去聯系成為真正的問題。這些都是人力解決方案帶來的人力問題。解決方案是要提供個人備份和支持,讓新的業務人員輪流加入團隊(可能從助理開始著手進行,逐步成長為關鍵決策角色),允許代表有時間回歸他們自己的核心工作,比如一天、一周等。事實上,這還有一個附加的好處,就是能讓更多的業務代表接觸到軟件開發,還可以傳播技巧和經驗。
4. 進化的領域模型
在本章中,我們看看模型在方案的后期是如何演進的。
4.1. 演進第一步:超越文章
首次發布后不久,編輯要求系統能處理更多的內容類型,而非只有文章一類。盡管這對我們來說毫不稀奇,但在我們構建模型的第一個版本時,我們還是明確決定對此不予考慮太多。
這是個關鍵點:我們關注整個團隊能很好地理解小規模、可管理塊中的模型和建模過程,而不是試圖預先對整個系統進行架構設計。隨著理解的深入或變化,稍后再改變模型并不是個錯誤。這種做法符合YAGNI編碼原則(你不會需要它),因為該做法防止開發人員引入額外的復雜度,因而也能阻止Bug的引入。它還能讓整個團隊安排時間去對系統中很小的一塊達成共識。我們認為,今天產出一個可工作的無Bug系統要比明天產出一個完美的、包括所有模型的系統更為重要。
我們的編輯在下一個迭代中要求的內容類型有音頻和視頻。我們的技術團隊和編輯再次坐在一起討論了領域建模過程。編輯先跟技術團隊談道,音頻和視頻很顯然與文章相似:應該可以將視頻或音頻放在一個頁面上。每個頁面只允許有一種內容。視頻和音頻可以通過關鍵字分類。關鍵字可以屬于版面。編輯還指明,在以后的迭代中他們會添加更多類型的內容,他們認為現在該是時候去理解我們應該如何隨著時間的推移去演進內容模型。
對我們的開發人員來說,很顯然編輯想在語言中明確引入兩個新條目:音頻和視頻。音頻、視頻和文章有一些共同點:它們都是內容類型,這一點也很明確。我們的編輯并不熟悉繼承的概念,所以技術團隊可以給編輯講解繼承,以便技術團隊能正確表述編輯所看到的模型。
這里有一個明顯的經驗:通過利用敏捷開發技術將軟件開發過程細分為小的塊,我們還能使業務人員的學習曲線變得平滑。久而久之他們能加深對領域建模過程的理解,而不用預先花費大量的時間去學習面向對象設計所有的組件。
這是我們的編輯根據添加的新內容類型設計的模型。

這個單一的模型演變是大量更細微的通用語言演進的結果。現在我們有三個外加的詞:音頻、視頻和內容;我們的編輯已經了解了繼承,并能在以后的模型迭代中加以利用;對添加新的內容類型,我們也有了以后的擴展策略,并使其對我們的編輯來說是簡單的。如果編輯需要一個新的內容類型,而這一新的內容類型與我們已有的內容類型相同、在頁面和關鍵字之間有大致相同的關系,那編輯就能要求開發團隊產出一個新的內容類型。作為一個團隊,我們正通過逐步生成模型來提高效率,因為我們的編輯不會再詳細檢查漫長的領域建模過程去添加新的內容類型。
4.2. 演進第二步:
由于我們的模型要擴展到包括更多的內容類型,它需要更靈活地去分類。我們開始在領域模型中添加額外的元數據,但編輯的最終意圖是什么還不是非常清楚。然而這并不讓我們太過擔憂,因為我們對元數據進行建模的方法與處理內容的方法一樣,將需求細分為可管理的塊,將每個添加到我們的領域中。
我們的編輯想添加的第一個元數據類型是系列這一概念。系列是一組相關的內容,內容則有一個基于時間的隱含順序。在報紙中有很多系列的例子,也需要將這一概念解釋為適用于Web的說法。
我們對此的初步想法非常簡單。我們將系列添加為一個領域對象,它要關聯到內容和頁面。這個對象將用來聚集與系列關聯的內容。如果讀者訪問了一種內容,該內容屬于某個系列,我們就能從頁面鏈接到同一系列中的前一條和后一條內容。我們還能鏈接到并生成系列索引頁面,該頁面可以顯示系列中的所有內容。
這里是編輯所設計的系列模型:

與此同時,我們的編輯正在考慮更多的元數據,他們想讓這些元數據與內容關聯。目前關鍵字描述了內容是關于什么的。編輯還要求系統能根據內容的基調對內容進行不同的處理。不同基調的例子有評論、訃告、讀者供稿、來信。通過引入基調,我們就可以將其顯示給讀者,讓他們找到類似的內容(其它訃告、評論等)。這像是除關鍵字或系列外另一種類型的關系。跟系列一樣,基調可以附加到一條內容上,也能和頁面有關系。
這里是編輯針對基調設計的模型:

完成開發后,我們有了一個能根據關鍵字、系列或基調對內容進行分類的系統。但編輯對達到這一點所需的技術工作量還有一些關注點。他們在我們下次演進模型時向技術團隊提出了這些關注點,并能提出解決方案。
4.3. 演進第三步:重構元數據
模型的下一步演進是我們的編輯想接著添加類似于系列和基調的內容。我們的編輯想添加帶有貢獻者的內容這一概念。貢獻者是創建內容的人,可能是文章的作者,或者是視頻的制作人。跟系列一樣,貢獻者在系統中有一個頁面,該頁面會自動聚集貢獻者制作的所有內容。
編輯還看到了另一個問題。他們認為隨著系列和基調的引入,他們已經向開發人員指明了大量非常相似的細節。他們要求構建一個工具去創建系列,構建另一個工具去創建基調。他們不得不指明這些對象如何關聯到內容和頁面上。每次他們都發現,他們在為這兩種類型的領域對象指定非常相似的開發任務;這很浪費時間,還是重復的。編輯更加關注于貢獻者,還有更多的元數據類型會加入進來。這看起來又要讓編輯再次指明、處理大量昂貴的開發工作,所有這些都非常相似。
這顯然成為一個問題。我們的編輯似乎已經發現了模型的一些錯誤,而開發人員還沒有。為什么添加新的元數據對象會如此昂貴呢?為什么他們不得不一遍又一遍地去指定相同的工作呢?我們的編輯問了一個問題,該問題是“這僅僅是‘軟件開發如何工作’,還是模型有問題?”技術團隊認為編輯熟悉一些事情,因為很顯然,他們理解模型的方式與編輯不同。我們與編輯一起召開了另一個領域建模會議,試圖找出問題所在。
在會議上我們的編輯建議,所有已有的元數據類型實際上源于相同的基本思想。所有的元數據對象(關鍵字、系列、基調和貢獻者)可以和內容有多對多的關系,而且它們都需要它們自己的頁面。(在先前的模型版本中,我們不得不知道對象和頁面之間的關系)。我們重構了模型,引入了一個新的超類——Tag(標簽),并作為其它元數據的超類。編輯們很喜歡使用“超類”這一技術術語,將整個重構稱為“Super-Tag”,盡管最終也回到了現實。
由于標簽的引入,添加貢獻者和其它預期的新元數據類型變得很簡單,因為我們能夠利用已有的工具功能和框架。
我們修訂后的模型現在看起來是這樣的:

我們的業務代表在以這種方式考慮開發過程和領域模型,發現這一點非常好,還發現領域驅動設計有能力促進在兩個方向都起作用的共同理解:我們發現技術團隊對我們正努力解決的業務問題有良好且持續的理解,而且出乎意料,業務代表能“洞察”開發過程,還能改變這一過程以更好地滿足他們的需求。編輯們現在不僅能將他們的需求翻譯為領域模型,還能設計、檢查領域模型的重構,以確保重構能與我們目前對業務問題的理解保持同步。
編輯規劃領域模型重構并成功執行它們的能力是我們領域驅動設計guardian.co.uk成功的一個關鍵點。
5. 代碼級別的演進
前面我們看了領域模型方面的進化。但DDD在代碼級別也有影響,不斷變化的業務需求也意味著代碼要有變化。現在我們來看看這些變化。
5.1. 構建模型
在構建領域模型時,要確認的第一件事就是領域中出現的聚集。聚集可認為是相關對象的集合,這些對象彼此相互引用。這些對象不應該直接引用其它聚集中的其它對象;不同聚集之間的引用應該由根聚集來完成。

看一下我們在上面定義的模型示例,我們開始看到對象成形。我們有Page和Template對象,它們結合起來能給Web頁面提供URL和觀感。由于Page是系統的入口點,所以在這里Page就是根聚集。
我們還有一個聚集Content,它也是根聚集。我們看到Content有Article、Video、Audio等子類型,我們認為這些都是內容的子聚集,核心的Content對象則是根聚集。
我們還看到形成了另一個聚集。它是元數據對象的集合:Tag、Series、Tone等。這些對象組成了標簽聚集,Tag是根聚集。
Java編程語言提供了理想的方式來對這些聚集進行建模。我們可以使用Java包來對每個聚集進行建模,使用標準的POJO對每個領域對象進行建模。那些不是根聚集、且只在聚集中使用的領域對象可以有包范圍內使用的構造函數,以防它們在聚集外被構造。
上述模型的包結構如下所示(“r2”是我們應用套件的名稱):
com.gu.r2.model.page com.gu.r2.model.tag com.gu.r2.model.content com.gu.r2.model.content.articlecom.gu.r2.model.content.videocom.gu.r2.model.content.audio
我們將內容聚集細分為多個子包,因為內容對象往往有很多聚集特定的支持類(這里的簡化圖中沒有顯示)。所有以標簽為基礎的對象往往要更為簡單,所以我們將它們放在了一個包里,而沒有引入額外的復雜性。
不過不久之后,我們認識到上述包結構會給我們帶來問題,我們打算修改它。看看我們前端應用的包結構示例,了解一下我們如何組織控制器,就能闡述清楚這一問題:
com.gu.r2.frontend.controller.pagecom.gu.r2.frontend.controller.articl
這里看到我們的代碼集要開始細分為片段。我們提取了所有的聚集,將其放入包中,但我們沒有單獨的包去包含與聚集相關的所有對象。這意味著,如果以后領域變得太大而不能作為一個單獨的單元來管理,我們希望將應用分解,處理依賴就會有困難。目前這還沒有真正帶來什么問題,但我們要重構應用,以便不會有太多的跨包依賴。經過改進的結構如下:
com.gu.r2.page.model (domain objects in the page aggregate)com.gu.r2.page.controller (controllers providing access to aggregate)com.gu.r2.content.article.modelcom.gu.r2.content.article.controller...etc
除了約定,我們在代碼集中沒有其它任何的領域驅動設計實施原則。創建注解或標記接口來標記聚集根是有可能的,實際上是爭取在模型包鎖定開發,減少開發人員建模時出錯的幾率。但實際上并不是用這些機械的強制來保證在整個代碼集中都遵循標準約定,而是我們更多地依賴了人力技術,比如結對編程和測試驅動開發。如果我們確實發現已創建的一些內容違反了我們的設計原則(這相當少見),那我們會告訴開發人員并讓他完善設計。我們還是喜歡這個輕量級的方法,因為它很少在代碼集中引入混亂,反而提升了代碼的簡單性和可讀性。這也意味著我們的開發人員更好地理解了為什么一些內容是按這種方式組織,而不是被迫去簡單地做這些事情。
5.2. 核心DDD概念的演進
根據領域驅動設計原則創建的應用會具有四種明顯的對象類型:實體、值對象、資源庫和服務。在本節中,我們將看看應用中的這些例子。
5.2.1 實體
實體是那些存在于聚集中并具有標識的對象。并不是所有的實體都是聚集根,但只有實體才能成為聚集根。
開發人員,尤其是那些使用關系型數據庫的開發人員,都很熟悉實體的概念。不過,我們發現這個看似很好理解的概念卻有可能引起一些誤解。
這一誤解似乎跟使用Hibernate持久化實體有點兒關系。由于我們使用Hibernate,我們一般將實體建模為簡單的POJO。每個實體具有屬性,這些屬性可以利用setter和getter方法進行存取。每個屬性都映射到一個XML文件中,定義該屬性如何持久化到數據庫中。為了創建一個新的持久化實體,開發人員需要創建用于存儲的數據庫表,創建適當的Hibernate映射文件,還要創建有相關屬性的領域對象。由于開發人員要花費一些時間處理持久化機制,他們有時似乎認為實體對象的目的僅僅只是數據的持久化,而不是業務邏輯的執行。等他們后來開始實現業務邏輯時,他們往往在服務對象中實現,而不是在實體對象本身中。
在下面(簡化)的代碼片段中可以看出此類錯誤。我們用一個簡單的實體對象來表示一場足球賽:
public class FootballMatch extends IdBasedDomainObject{ private final FootballTeam homeTeam;private final FootballTeam awayTeam;private int homeTeamGoalsScored;private int awayTeamGoalsScored;FootballMatch(FootballTeam homeTeam, FootballTeam awayTeam) { this.homeTeam = homeTeam; this.awayTeam = awayTeam; } public FootballTeam getHomeTeam() { return homeTeam; } public FootballTeam getAwayTeam() { return awayTeam; } public int getHomeTeamScore() { return homeTeamScore; } public void setHomeTeamScore(int score) { this.homeTeamScore = score; } public void setAwayTeamScore(int score) { this.awayTeamScore = score; } }
該實體對象使用FootballTeam實體去對球隊進行建模,看起來很像使用Hibernate的開發人員所熟悉的對象類型。該實體的每個屬性都持久化到數據庫中,盡管從領域驅動設計的角度來說這個細節并不真的重要,我們的開發人員還是將持久化的屬性提升到一個高于它們應該在的水平上去。在我們試圖從FootballTeam對象計算出誰贏得了比賽的時候這一點就可以顯露出來。我們的開發人員要做的事情就是造出另一種所謂的領域對象,就像下面所示:
public class FootballMatchSummary { public FootballTeam getWinningTeam(FootballMatch footballMatch) { if(footballMatch.getHomeTeamScore() > footballMatch.getAwayTeamScore()) { return footballMatch.getHomeTeam(); } return footballMatch.getAwayTeam(); } }
片刻的思考應該表明已經出現了錯誤。我們已經創建了一個FootballMatchSummary類,該類存在于領域模型中,但對業務來說它并不意味著什么。它看起來是充當了FootballMatch對象的服務對象,提供了實際上應該存在于FootballMatch領域對象中的功能。引起這一誤解的原因好像是開發人員將FootballMatch實體對象簡單地看成了是反映數據庫中持久化信息,而不是解決所有的業務問題。我們的開發人員將實體考慮為了傳統ORM意義上的實體,而不是業務所有和業務定義的領域對象。
不愿意在領域對象中加入業務邏輯會導致貧血的領域模型,如果不加以制止還會使混亂的服務對象激增——就像我們等會兒看到的一樣。作為一個團隊,現在我們來檢視一下創建的服務對象,看看它們實際上是否包含業務邏輯。我們還有一個嚴格的規則,就是開發人員不能在模型中創建新的對象類型,這對業務來說并不意味著什么。
作為團隊,我們在項目開始時還被實體對象給弄糊涂了,而且這種困惑也與持久化有關。在我們的應用中,大部分實體與內容有關,而且大部分都被持久化了。但當實體不被持久化,而是在運行時由工廠或資源庫創建的話,有時候還是會混淆。
一個很好的此類例子就是“標簽合成的頁面”。我們在數據庫中持久化了編輯創建的所有頁面的外觀,但我們可以自動生成從標記組合(比如USA+Economics或Technology+China)聚集內容的頁面。由于所有可能的標記組合總數是個天文數字,我們不可能持久化所有的這些頁面,但系統還必須能生成頁面。在渲染標記組合頁面時,我們必須在運行時實例化尚未持久化的新Page實例。項目初期我們傾向于認為這些非持久化對象與“真正的”持久化領域對象不同,也不像在對它們建模時那么認真。從業務觀點看,這些自動生成的實體與持久化實體實際上并沒有什么不同,因此從領域驅動設計觀點來看也是如此。不論它們是否被持久化,對業務來說它們都有同樣的定義,都不過是領域對象;沒有“真正的”和“不是真正的”領域對象概念。
5.2.2 值對象
值對象是實體的屬性,它們沒有特性標識去指明領域中的內容,但表達了領域中有含義的概念。這些對象很重要,因為它們闡明了統一語言。
值對象闡述能力的一個例子可以從我們的Page類更詳細地看出。系統中任何Page都有兩個可能的URLs。一個URL是讀者鍵入Web瀏覽器以訪問內容的公開URL。另一個則是從應用服務器直接提供服務時內容依存的內部URL。我們的Web服務器處理從用戶那里傳入的URL,并將它轉換為適合后端CMS服務器的內部URL。
一種簡化的觀點是,在Page類中兩個可能的URL都被建模為字符串對象:
public String getUrl(); public String getCmsUrl();
不過,這并沒有什么特別的表現力。除了這些方法返回字符串這一事實之外,只看這些方法的簽名很難確切地知道它們會返回什么。另外想象一下這種情況,我們想基于頁面的URL從一個數據訪問對象中加載頁面。我們可能會有如下的方法簽名:
public Page loadPage(String url);
這里需要的URL是哪一個呢?是公開的那個還是CMS URL?不檢查該方法的代碼是不可能識別出來的。這也很難與業務人員談論頁面的URL。我們指的到底是哪一個呢?在我們的模型中沒有表示每種類型URL的對象,因此在我們的詞匯里面也就沒有相關條目。
這里還含有更多的問題。我們對內部URL和外部URL可能有不同的驗證規則,也希望對它們執行不同的操作。如果我們沒有地方放置這個邏輯,那我們怎么正確地封裝該邏輯呢?控制URLs的邏輯一定不屬于Page,我們也不希望引入更多不必要的服務對象。
領域驅動設計建議的演進方案是明確地對這些值對象進行建模。我們應該創建表示值對象的簡單包裝類,以對它們進行分類。如果我們這樣做,Page里面的簽名就如下所示:
public Url getUrl();public CmsPath getCmsPath();
現在我們可以在應用中安全地傳遞CmsPath或Url對象,也能用業務代表理解的語言與他們談論代碼。
5.2.3 資源庫
資源庫是存在于聚集中的對象,在抽象任何持久化機制時提供對聚集根對象實體的訪問。這些對象由業務問題請求,與領域對象一起響應。
將資源庫看成是類似于有關數據庫持久化功能的數據訪問對象,而非存在于領域中的業務對象,這一點很不錯。但資源庫是領域對象:他們響應業務請求。資源庫始終與聚集關聯,并返回聚集根的實例。如果我們請求一個頁面對象,我們會去頁面資源庫。如果我們請求一個頁面對象列表來響應特定的業務問題,我們也會去頁面資源庫。
我們發現一個很好的思考資源庫的方式,就是把它們看成是數據訪問對象集合之上的外觀。然后它們就成為業務問題和數據傳輸對象的結合點,業務問題需要訪問特定的聚集,而數據傳輸對象提供底層功能。
這里舉一小段頁面資源庫的代碼例子,我們來實際看下這個問題:
private final PageDAO<Page> pageDAO; private final PagesRelatedBySectionDAO pagesRelatedBySectionDAO; public PageRepository(PageDAO<Page> pageDAO,EditorialPagesInThisSectionDAO pagesInThisSectionDAO, PagesRelatedBySectionDAO pagesRelatedBySectionDAO) { this.pageDAO = pageDAO; this.pagesRelatedBySectionDAO = pagesRelatedBySectionDAO;} public List<Page> getAudioPagesForPodcastSeriesOrderedByPublicationDate(Series series, int maxNumberOfPages) { return pageDAO.getAudioPagesForPodcastSeriesOrderedByPublicationDate(series, maxNumberOfPages); } public List<Page> getLatestPagesForSection(Section section, int maxResults) {return pagesRelatedBySectionDAO.getLatestPagesForSection(section, maxResults); }
我們的資源庫有業務請求:獲取PublicationDate請求的特定播客系列的頁面。獲取特定版面的最新頁面。我們可以看看這里使用的業務領域語言。它不僅僅是一個數據訪問對象,它本身就是一個領域對象,跟頁面或文章是領域對象一樣。
我們花了一段時間才明白,把資源庫看成是領域對象有助于我們克服實現領域模型的技術問題。我們可以在模型中看到,標簽和內容是一種雙向的多對多關系。我們使用Hibernate作為ORM工具,所以我們對其進行了映射,Tag有如下方法:
public List<Content> getContent();
Content有如下方法:
public List<Tag> getTags();
盡管這一實現跟我們的編輯看到的一樣,是模型的正確表達,但我們有了自己的問題。對開發人員來說,代碼可能會編寫成下面這樣:
if(someTag.getContent().size() == 0){... do some stuff}
這里的問題是,如果標簽關聯有大量的內容(比如“新聞”),我們最終可能會往內存中加載幾十萬的內容條目,而只是為了看看標記是否包含內容。這顯然會引起巨大的網站性能和穩定性問題。
隨著我們演進模型、理解了領域驅動設計,我們意識到有時候我們必須要注重實效:模型的某些遍歷可能是危險的,應該予以避免。在這種情況下,我們使用資源庫來用安全的方式解決問題,會為系統的性能和穩定性犧牲模型個別的清晰性和純潔性。
5.2.4. 服務
服務是通過編排領域對象交互來處理業務問題執行的對象。我們所理解的服務是隨著我們過程演進而演進最多的東西。
首要問題是,對開發人員來說創建不應該存在的服務相當容易;他們要么在服務中包含了本應存在于領域對象中的領域邏輯,要么扮演了缺失的領域對象角色,而這些領域對象并沒有作為模型的一部分去創建。
項目初期我們開始發現服務開始突然涌現,帶著類似于ArticleService的名字。這是什么呀?我們有一個領域對象叫Article;那文章服務的目的是什么?檢查代碼時,我們發現該類似乎步了前面討論的FootballMatchSummary的后塵,有類似的模式,包含了本該屬于核心領域對象的領域邏輯。
為了對付這一行為,我們對應用中的所有服務進行了代碼評審,并進行重構,將邏輯移到適當的領域對象中。我們還制定了一個新的規則:任何服務對象在其名稱中必須包含一個動詞。這一簡單的規則阻止了開發人員去創建類似于ArticleService的類。取而代之,我們創建ArticlePublishingService和ArticleDeletionService這樣的類。推動這一簡單的命名規范的確幫助我們將領域邏輯移到了正確的地方,但我們仍要求對服務進行定期的代碼評審,以確保我們在正軌上,以及對領域的建模接近于實際的業務觀點。
6. 演進架構中DDD的一些教訓
盡管面臨挑戰,但我們發現了在不斷演進和敏捷的環境中利用DDD的顯著優勢,此外我們還總結了一些經驗教訓:
- 你不必理解整個領域來增加商業價值。你甚至不需要全面的領域驅動設計知識。團隊的所有成員差不多都能在他們需要的任何時間內對模型達成一個共同的理解。
- 隨著時間的推移,演進模型和過程是可能的,隨著共同理解的提高,糾正以前的錯誤也是可能的。
我們系統的完整領域模型要比這里描述的簡化版本大很多,而且隨著我們業務的擴展在不斷變化。在一個大型網站的動態世界里,創新永遠發生著;我們始終要保持領先地位并有新的突破,對我們來說,有時很難在第一次就得到正確的模型。事實上,我們的業務代表往往想嘗試新的想法和方法。有些人會取得成果,其他人則會失敗。是逐步擴展現有領域模型——甚至在現有領域模型不再滿足需求時進行重構——的業務能力為guardian.co.uk開發過程中遇到的大部分創新提供了基礎。
7. 附錄:具體示例
為了了解我們的領域模型如何生成真實的結果,這里給出了一個例子,先看單獨的內容……
- 有關頁面本身的一些音頻內容
- 它有幾個標簽:貢獻者是Matt Wells;關鍵字包括“Digital Media”和“Radio”;它屬于“Media Talk”系列。這些標簽都鏈接在頁面上。
- Matt Wells有他自己的頁面,而且有特定的模板
- “Digital Media”關鍵字也有其自己的頁面,使用不用的模板
- “Media Talk”系列也有自己的頁面
- 音頻內容有一個頁面,頁面列出了所有的音頻
- 標簽組合頁面可以完全實時生成。
8. 關于作者
Nik Silver是Guardian News & Media軟件開發總監。他于2003年在公司引入敏捷軟件開發,負責軟件開發、前端開發和質量保證。Nik偶爾會在blogs.guardian.co.uk/inside上寫Guardian技術工作相關的內容,并在他自己的站點niksilver.com上寫更寬泛的軟件問題。
Matthew Wall是Guardian News & Media的軟件架構師,深入研究敏捷環境下大型Web應用的開發。他目前最關心的是為guardian.co.uk開發下一代的Web平臺。他在JAOO、ServerSide、QCon、XTech和OpenTech上做過關于此及相關主題的各種演講。
Web架構設計經驗分享
作者:朱燚
來源:http://www.cnblogs.com/yizhu2000/archive/2007/12/04/982142.html
?
本人作為一位web工程師,著眼最多之處莫過于 性能與架構,本次幸得參與sd2.0大會,得以與同行廣泛交流,于此二方面,有些心得,不敢獨享,與眾博友分享,本文是這次參會與眾同撩交流的心得,有興趣者可以查看視頻
架構設計的幾個心得:
一,不要過設計:never over design
這是一個常常被提及的話題,但是只要想想你的架構里有多少功能是根本沒有用到,或者最后廢棄的,就能明白其重要性了,初涉架構設計,往往傾向于設計大而化一的架構,希望設計出具有無比擴展性,能適應一切需求的增加架構,web開發領域是個非常動態的過程,我們很難預測下個星期的變化,而又需要對變化做出最快最有效的響應。。
ebay的工程師說過,他們的架構設計從來都不能滿足系統的增長,所以他們的系統永遠都在推翻重做。請注意,不是ebay架構師的能力有問題,他們設計的架構總是建立舊版本的瓶頸上,希望通過新的架構帶來突破,然而新架構帶來的突破總是在很短的時間內就被新增需求淹沒,于是他們不得不又使用新的架構
web開發,是個非常敏捷的過程,變化隨時都在產生,用戶需求千變萬化,許多方面偶然性非常高,較之軟件開發,希望用一個架構規劃以后的所有設計,是不現實的
二,web架構生命周期:web architecture‘s life cycle
既然要杜絕過設計,又要保證一定的前瞻性,那么怎么才能找到其中的平衡呢?希望下面的web架構生命周期能夠幫到你
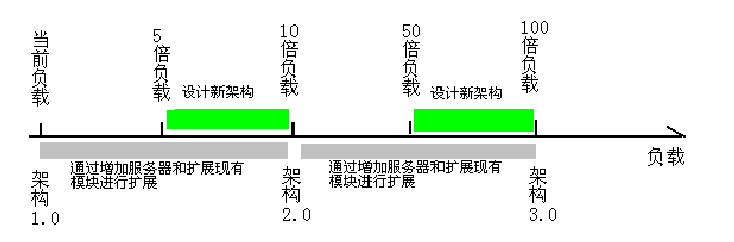
所設計的架構需要在1-10倍的增長下,通過簡單的增加硬件容量就能夠勝任,而在5-10倍的增長期間,請著手下一個版本的架構設計,使之能承受下一個10倍間的增長
google之所以能夠稱霸,不完全是因為搜索技術和排序技術有多先進,其實包括baidu和yahoo,所使用的技術現在也已經大同小異,然而,google能在一個月內通過增加上萬臺服務器來達到足夠系統容量的能力確是很難被復制的
三,緩存:Cache
空間換取時間,緩存永遠計算機設計的重中之重,從cpu到io,到處都可以看到緩存的身影,web架構設計重,緩存設計必不可少,關于怎樣設計合理的緩存,jbosscache的創始人,淘寶的創始人是這樣說的:其實設計web緩存和企業級緩存是非常不同的,企業級緩存偏重于邏輯,而web緩存,簡單快速為好。。
緩存帶來的問題是什么?是程序的復雜度上升,因為數據散布在多個進程,所以同步就是一個麻煩的問題,加上集群,復雜度會進一步提高,在實際運用中,采用怎樣的同步策略常常需要和業務綁定
老錢為搜狐設計的帖子設計了鏈表緩存,這樣既可以滿足靈活插入的需要,又能夠快速閱讀,而其他一些大型社區也經常采用類此的結構來優化帖子列表,memcache也是一個常常用到的工具
錢宏武談架構設計視頻 http://211.100.26.82/CSDN_Live/140/qhw.flv
Cache的常用的策略是:讓數據在內存中,而不是在比較耗時的磁盤上。從這個角度講,mysql提供的heap引擎(存儲方式)也是一個值得思考的方法,這種存儲方法可以把數據存儲在內存中,并且保留sql強大的查詢能力,是不是一舉兩得呢?
我們這里只說到了讀緩存,其實還有一種寫緩存,在以內容為主的社區里比較少用到,因為這樣的社區最主要需要解決的問題是讀問題,但是在處理能力低于請求能力時,或者單個希望請求先被緩存形成塊,然后批量處理時,寫緩存就出現了,在交互性很強的社區設計里我們很容易找到這樣的緩存
四,核心模塊一定要自己開發:DIY your core module
這點我們是深有體會,錢宏武和云風也都有談到,我們經常傾向于使用一些開源模塊,如果不涉及核心模塊,確實是可以的,如果涉及,那么就要小心了,因為當訪問量達到一定的程度,這些模塊往往都有這樣那樣的問題,當然我們可以把問題歸結為對開源的模塊不熟悉,但是不管怎樣,核心出現問題的時候,不能完全掌握其代碼是非常可怕的
五,合理選擇數據存儲方式:reasonable data storage
我們一定要使用數據庫嗎,不一定,雷鳴告訴我們搜索不一定需要數據庫,云風告訴我們,游戲不一定需要數據庫,那么什么時候我們才需要數據庫呢,為什么不干脆用文件來代替他呢?
首先我們需要先承認,數據庫也是對文件進行操作。我們需要數據庫,主要是使用下面這幾個功能,一個是數據存儲,一個是數據檢索,在關系數據庫中,我們其實非常在乎數據庫的復雜搜索的能力,看看一個統計用的tsql就知道了(不用仔細讀,掃一眼就可以了)
select?? c.Class_name,d.Class_name_2,a.Creativity_Title,b.User_name,(select?? count(Id)?? from?? review?? where?? Reviewid=a.Id)?? as?? countNum?? from?? Creativity?? as?? a,User_info?? as?? b,class?? as?? c,class2?? as?? d?? where?? a.user_id=b.id?? and?? a.Creativity_Class=c.Id?? and?? a.Creativity_Class_2=d.Id
select?? a.Id,max(c.Class_name),(max(d.Class_name_2),max(a.Creativity_Title),max(b.User_name),count(e.Id)?? as?? countNum?? from?? Creativity?? as?? a,User_info?? as?? b,class?? as?? c,class2?? as?? d,review?? as?? e?? where?? a.user_id=b.id?? and?? a.Creativity_Class=c.Id?? and?? a.Creativity_Class_2=d.Id?? and?? a.Id=e.Reviewid?? group?? by?? a.Id ..............................................
我們可以看出需要數據庫關聯,排序的能力,這個能力在某些情況下非常重要,但是如果你的網站的常規操作,全是這樣復雜的邏輯,那效率一定是非常低的,所以我們常常在數據庫里加入許多冗余字段,來減小簡單查詢時關聯等操作帶來的壓力,我們看看下面這張圖,可以看到數據庫的設計重心,和網站(指內容型社區)需要面對的問題實際是有一些偏差的
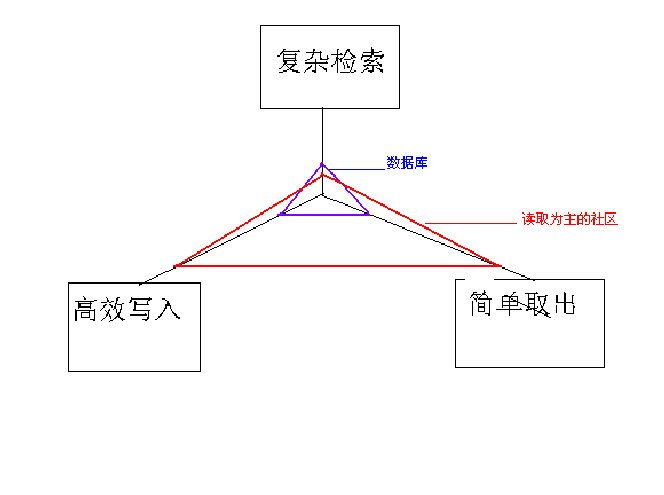
同樣其他一些軟件產品也遇到同樣的問題所以具我了解,有許多特殊的運用都有自己設計的特殊數據存儲結構與方法,比如有的大型服務程序采取樹形數據存儲結構,lucene使用文件來存儲索引和文件
從另外一個角度上看,使用數據庫,意味著數據和表現是完全分離的(這當然是經典的設計思路),也就是說當需要展示數據時,不得不需要一個轉換的過程,也可以說是綁定的過程,當網站具備一定規模的時候,數據庫往往成為效率的瓶頸,所以許多網站也采用直接書寫靜態文件的方法來避免讀取操作時的綁定
這并不是說我們從今天起就可以把我們親愛的數據庫打入冷宮,而是我們在設計數據的持久化時,需要根據實際情況來選擇存儲方式,而數據庫不過是其中一個選項
六,搞清楚誰是最重要的人:who's the most important guy
在用例需求分析的時候常常講到涉眾,就是和你的設計息息相關的人,在web中我們一定以為最重要的涉眾莫過于用戶了。,在一個傳統的互動社區開發中,最重要的東西是內容,用戶產生內容,所以用戶就是上帝,至于內容挑選工具,不就是給坐我后面三排的妹妹們用的嗎?湊或行了,實在有問題我就在數據里手動幫你加得了。。這大概是眼下許多小型甚至中型網站技術人員的普遍想法。錢宏武在他的講座里談到了這個問題:實際上網站每天產生的內容非常的多,普通人是不可能看完的,而編輯負責把精華的內容推薦到首頁上,所以很多用戶讀到的內容其實都依賴于編輯的推薦,所以設計讓編輯工作方便的工具也是非常重要,有時甚至是最重要的。
七,不要執著于文檔:don't be crazy about document
web開發的文檔重要嗎?什么文檔最重要?我的看法是web開發中交流>文檔,
現在大的軟件公司比較流行的做法是:
注重產品設計文檔,在這種方法里,產品文檔非常詳盡,并且沒有歧義,開發人員基于設計文檔開發,測試人員基于設計文檔制定測試方案,任何新人都可以通過閱讀產品設計文檔來了解項目的概況
而web項目從概念到實現的時間是非常短的,而且越短越好,并且由于變化迅速,要想寫出完整的產品和需求文檔是幾乎不可能的,大多數情況是等你寫出完備的文檔,項目早就是另外一個樣子,但是沒有文檔的問題是,如果團隊發生變化,添加新成員怎樣才能了解軟件的結構和概念呢,一種是每個人都了解軟件的整個結構,除非你的團隊整體消失,否則任何一個人都能夠擔當培養新人的責任,這種face2face交流比文檔有效率很多。
于是就有了前office開發者,現任yahoo中國某產品開發負責人的劉振飛所感覺到的落差,他說,我們的項目是吵出來的,我聽完會心一笑
八,團隊:team
不要專家團隊,而要外科手術式的團隊,你的團隊里一定要有清道夫,需要有弓箭手,讓他們和項目一起成長,才是項目負責人的最大成就
總結:
0)架構是一種權衡
1)web開發的特點是是:沒有太復雜的技術難點,一切在于迅速的把握需求,其實這正式敏捷開發的要旨所在,一切都可以非常快速的建立,非常快速的重構,我們的開發工具,底層庫和框架,包括搜索引擎和web文檔提供的幫助,都提我們供給了敏捷的能力。
2)此外,相應的,最有效率的交流方式必須留給web開發,那就是face2face(面對面),不要太擔心你的設計不能被完備的文檔所保留下來,他們會以交流,代碼和小卡片的方式保存下來
3)人的因素會更加重要,無論是對用戶的需求,還是開發人員的素質。
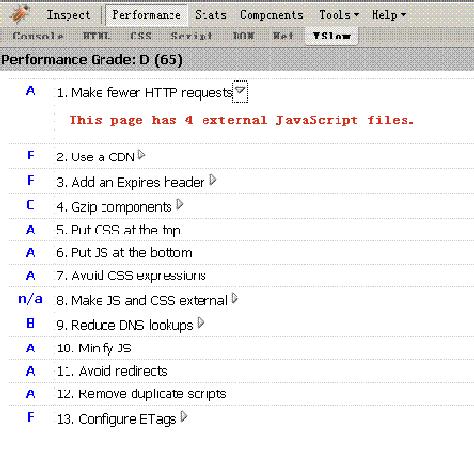
另:有關web效率,有著名的14條規則,由yahoo性能效率小組所總結,并廣為流傳。業已出現相關插件(YSlow),針對具體網頁按彼規則評分,這次該小組負責人Tenni Theurer也受邀來到此次大會,我把Tenni小姐(之前真的沒有想到她是個女孩,并且如此年輕)和她的團隊的14 rules列在下面
- Make Fewer HTTP Requests
- Use a Content Delivery Network
- Add an Expires Header
- Gzip Components
- Put CSS at the Top
- Move Scripts to the Bottom
- Avoid CSS Expressions
- Make JavaScript and CSS External
- Reduce DNS Lookups
- Minify JavaScript
- Avoid Redirects
- Remove Duplicate Scripts
- Configure ETags
- Make Ajax Cacheable
?
通過安裝firebug和YSlow這兩個firefox插件(請注意要先安裝firebug再安裝yslow,下載后拖動到firefox里即可)我們可以看到你的網頁根據下面的規則的評分,這是我在博客園博客首頁的評分截圖,上面D表示總分,下面是單項評分,A最好F最差,不知道還有沒有G :)
?
相關連接
yahoo性能團隊:http://developer.yahoo.com/performance/
軟件架構設計
事實上,經過從上面三個方面審視架構,我們已經建立了一個完整的而且比較良好的架
構。但我們還需要從第四個方面在更高的層次審視我們的架構,需要考慮的又一個問題就是
軟件的復用。復用可以大大降低后期成本,提高整個軟件系統的可升級性與可維護性。我們
可以考慮哪些結構可以使用已經存在的可復用結構和產品,某些結構可以利用 GoF 的設計模
式設計可復用的構件已備后期使用。還需要根據需求分析得出的易變點仔細設計產品結構,
確保后期的變化不至于對產品帶來太大的影響。而復用的一個重要的手段,就是面向構件的
方法。
1,軟件復用
軟件復用是指重復使用“為了復用目的而設計的軟件”的過程。在過去的開發實踐中,
我們也可能會重復使用“并非為了復用目的而設計的軟件”的過程,或者在一個應用系統的
不同版本間重復使用代碼的過程,這兩類行為都不屬于嚴格意義上的軟件復用。
通過軟件復用,在應用系統開發中可以充分地利用已有的開發成果,消除了包括分析、
設計、編碼、測試等在內的許多重復勞動,從而提高了軟件開發的效率,同時,通過復用高
質量的已有開發成果,避免了重新開發可能引入的錯誤,從而提高了軟件的質量。在基于復
用的軟件開發中,為復用而開發的軟件架構本身就可以作為一種大粒度的、抽象級別較高的
軟件構件進行復用,而且軟件架構還為構件的組裝提供了基礎和上下文,對于成功的復用具
有非常重要的意義。
軟件架構研究如何快速、可靠地用可復用構件構造系統的方式,著眼于軟件系統自身的
整體結構和構件間的互聯。其中主要包括:軟件架構原理和風格,軟件架構的描述和規范,
特定領域軟件架構,構件如何向軟件構架的集成機制等。
2,面向構件的方法簡述
構件也稱為組件,面向構件的方法包含了許多關鍵理論,這些關鍵理論解決了當今許多
備受挑剔的軟件問題,這些理論包括:
構件基礎設施
軟件模式
軟件架構
基于構件的軟件開發
構件可以理解為面向對象軟件技術的一種變體,它有四點原則區別于其它思想,封裝、
多態、后期綁定、安全。從這個角度來說,它和面向對象是類似的。不過它取消了對于繼承
的強調。
在面向構件的思想里,認為繼承是個緊耦合的、白盒的關系,它對大多數打包和復用來
說都是不合適的。構件通過直接調用其它對象或構件來實現功能的復用,而不是使用繼承來
實現它,事實上,在我們后面的討論中,也會提到面向對象的方法中還是要優先使用組合而
不是繼承,但在構件方法中則完全摒棄了繼承而是調用,在構件術語里,這些調用稱作“代
理”(delegation)。
實現構件技術關鍵是需要一個規范,這個規范應該定義封裝標準,或者說是構件設計的
公共結構。理想狀態這個規范應該是在行業以至全球范圍內的標準,這樣構建就可以在系統、
企業乃至整個軟件行業中被廣泛復用。構件利用組裝來創建系統,在組裝的過程中,可以把
多個構件結合在一起創建一個比較大的實體,如果構件之間能夠匹配用戶的請求和服務的規
范,它們就能進行交互而不需要額外的代碼。
3,面向構件的軟件模式
面向構件技術的特色在于:迅速、靈活、簡潔,面向構件技術之于軟件業的意義正如由
生產流水線之于工業制造,是軟件業發展的必然趨勢。軟件業發展到今天,已經不是那種個
人花費一段時間即可完成的小軟件。軟件越來越復雜,時間越來越短,軟件代碼也從幾百行
到現在的上百萬行。把這些代碼分解成一些構件完成,可以減少軟件系統中的變化因子。
1)面向構件方法模式
面向構件技術的思想基礎在軟件復用,技術基礎是根據軟件復用思想設計的眾多構件。
面向構件將軟件系統開發的重心移向如何把應用系統分解成穩定、靈活、可重用的構件和如
何利用已有構件庫組裝出隨需而變的應用軟件。
基于面向構件的架構可以描述為:系統=框架+構件+組建。框架是所有構件的支撐框架;
每個構件實現系統的每個具體功能;組建,可以視為構件的插入順序,不同構件的組成順序不
同,其實現的整體功能也就不同。
面向構件技術將把軟件開發分成幾種:框架開發設計、構件開發設計、組裝,如果用現
代的工業生產做比喻,框架設計就是基本的生產機器的開發研究,構件開發就是零件的生產,
組裝就是把零件組裝成汽車、飛機等等各種產品。
2)面向構件開發的不足之處
(1)系統資源耗費
從軟件性能角度看,用面向構件技術開發的軟件并不是最佳的。除了有比較大的代碼冗
余外,因為它的靈活性在很大程度上是以空間和時間等為代價實現的。
(2)面向構件開發的風險
從細節來看,構件將構件的實現細節完全封裝,如果沒有好的文檔支持,有可能導致構
件的使用結果不是使用者預期的。比如,構件使用者對某構件的出錯機制認識不夠
3)開放式系統技術
專用軟件是由單個供應商生產的不符合統一標準的產品。這些單個供應商通過版本更換
來控制軟件的形式與功能。但是誰這系統越來越復雜,當一個系統建立起來以后,往往更傾
向于依賴于通用的商業軟件,這種依賴往往成為內部軟件復用的非常有效的形式。正是這種
狀態,我們需要討論一下開放式系統技術這個問題。
商業軟件成為復用的有效形式,主要原因是規模經濟的作用,通用的商業軟件的質量,
往往超過終端用戶自主開發能力。
商業軟件也可以在某個領域內實現專有,也就是提供應用程序接口(API)為應用軟件
提供服務。當軟件不斷升級的過程中,這些接口的復雜性可能超出用戶的需要,這就需要有
復雜性的控制。
一個解決方案就是實現開放式系統技術,開放式系統技術與專有技術有根本的不同。在
開放式系統技術中,由供應商組織來開發獨立于專有實現的規范,所有的供應商實現的接口
都嚴格的一致,并且規定了統一的術語,這樣就可以是軟件的生命周期得以延長,這種開放
式系統技術特別適合于面向對象的方法。
為了使商業技術能適應各種應用需求,對軟件開發和安裝就有一定的要求,這種要求稱
之為配置(profiling),適當的配置軟件的嵌入也稱為開放是軟件的一個特點。
從架構的角度來看,不少系統結構具有大量的一對一接口和復雜的相互連接關系,這種
模型被稱之為“煙囪”模型,當系統規模增大以后,這種關系會以平方律的速度增加,復雜
性的增加會帶來相當多的問題,尤其是升級和修改越來越難以進行,而系統的可擴展性恰恰
是開發成本的重要部分。
為此,我們可以建立一個稱之為對象管理器的層,用于統一協調各個對象的溝通,從可
維護性角度這是一個比較好的結構,但是在某些特別強調效率的點可以避開它。系統的架構
的一個重要原則就是對軟件接口定義一個已經規劃的定義,為系統集成方案提供更高的統一
性,軟件的子系統部分要由應用程序接口來定義。這樣,就削弱了模塊之間的依賴性,這樣
的系統就比較容易擴展和維護,并且支持大規模的集成。
經過從四個方面審視我們的架構,經過分析、權衡、設計和部分編碼,我們就可以得到
一個穩固的架構。這個架構經過經過評審,就可以作為后期開發的基礎架構.
綜上所述,我們就可以比較條理化的建立軟件架構設計的流程了。典型軟件架構設計的
流程如下圖所示。
一、業務架構概念
在構建軟件架構之前,架構師需要仔細研究如下幾個問題:
系統是為什么目的而構建的?
系統投運后服務于哪些利益相關者的利益?
什么角色在什么時候操作或者維護系統?
業務系統實現方法是怎樣的?
整個業務系統是如何依靠系統而運轉的?
為了回答這些問題,需要仔細閱讀需求分析文檔中的業務模型建立、問題域及其解決構
思、產品模型的構思等等前期文檔,站在系統架構的角度,全面清晰的建立業務模型,包括
組織結構關系、業務功能、業務流程、業務信息交互方法、業務地理分布、業務規則和約束
條件。這個階段的主要活動如下:
建立產品范圍、目的、最終用戶、業務背景等重要的初始信息。
建立完整的業務和系統的術語字典,確保項目相關人員理解上保持一致。
建立宏觀層面業務的總體概念,明確總體流程、業務功能的邊界、交互與協作方式,
建立系統的概念模型。
匯總業務總的組織結構與協作職能關系。
分析業務的組成節點,以及節點間交互、協同與信息的依賴關系。
分析業務節點的事件、消息,以及由此引發的狀態轉換關系。
匯總業務運行的基本數據模型,以便于跟蹤信息的流動與格式轉換。分析業務數據
的關聯關系。
理解問題域以及系統需要解決的問題。
分析業務運作層面的基本業務規則與約束條件。
這個階段的活動非常重要,架構師只有具備了這些相互關聯的業務概念以后,才可能從
這些概念中抽取恰當的架構因素。
二、產品架構概念
在理解業務的基礎上,我們需要進一步思考產品架構的概念,這個階段從活動的層面看
實際上與建立業務架構概念是一樣的,但是思維的重心轉移到如下幾個方面:
新系統投入運行以后,最高層面的業務會怎樣運作?
新系統是如何解決原來工作系統的問題的?
新系統的投運,會對原來的組織結構劃分發生什么樣的影響?
由于新系統取代了原來的一些業務職能,業務節點的分布會發生怎樣的變化?變化
后的節點間的信息又是怎樣交換與依賴的?
變化后的業務事件傳遞又會發生怎樣的變化?
新的系統加入以后,哪些業務流程將會發生重大變化?哪些不會發生變化?
業務的狀態轉換關系將會如何隨著新系統地加入而改變?
業務的數據模型將會如何隨著業務流程的變化而變化的?
新系統地加入,將會如何影響新的業務規則和約束?
從這些角度出發,我們會重新構建未來新系統投運以后的業務規則,相應的新規則也需
要建立,這就實現了業務過程的重構。
三、建立穩定的架構基線
在對業務領域與問題域有深刻的理解以后,我們需要繼續研究如下一些問題:
這個復雜系統應該分成多少和哪些子系統?
子系統是如何分布在不同的業務節點或者物理節點上的?
這些分散的子系統將提供哪些接口?這些接口如何進行交互?
各個子系統需要交互哪些數據?
每個單獨的子系統,所需要實現的功能有哪些?
整個系統對各個子系統有哪些功能、性能和質量上的要求?
“基線”這個詞有兩個意義:
這個階段將會對整體架構策略做出重大的設計上的決策。一旦作出了這些決策,后
續開發沒有重大情況不允許變動。
這個階段完成的工作,本身就是架構階段的重要成果,需要廣泛認同、集體遵守以
及具備強制的約束力。
盡管在后期的演變中,這樣的基線實際上還會不斷的精化和優化,但最初下功夫構建穩
定的架構基線是十分必要的。這個階段的活動如下:
校驗與確認前期所有的業務架構與產品架構的信息,必要的時候補充相應的信息。
修訂和增補術語字典,確保所有的相關人員對術語有相同的認知。
把整個系統功能進行拆分,并且分解到不同的運行節點上,構建不同的系統集和子
系統,在全局范圍內劃分接口與交互規則。
匯總系統/子系統接口信息,便于檢索與瀏覽。
規劃整個系統的通信鏈路、通信路徑、通信網絡等傳輸媒介。
把產品架構概念中的業務職能與系統功能相對應,從而確保滿足業務要求。
分析系統/子系統在運行起動態協作需要交互的信息。
構建和模擬整個系統在業務環境下的動態特性,規劃全系統內部狀態變化過程、觸
發的事件及約束條件。
詳細匯總各個子系統間信息傳遞的過程、內容以及其它輔助信息。
根據初始的數據模型構建數據物理模型。
匯總質量上對系統的要求,并把這些質量要求細化分解,量化到各個子系統中去。
構建整個系統與子系統的構建和演化計劃,在迭代過程中構建整體項目規劃和初始
的迭代規劃。
按固定時段預測技術的演化,匯總整個系統的應用技術及其演化。
分辨與匯總整個系統在不同階段必須遵循的標準。
把業務約束映射到各個子系統,必要時附加 IT 業務約束。
四、子系統架構的設計與實現
通過上述各主要過程,我們已經實現了一個重要的總體架構基線。所有的子系統設計都
是在這個龐大的架構基線約束下展開,至此,首席架構師逐漸淡出,讓位于子系統架構設計
師。子系統架構設計師的任務是繼續分解、細化、設計各個子系統。在這個階段,將會考慮
更加細節的問題,為后來的構件設計與單元設計作準備,我們需要考慮的問題如下:
規劃給該子系統的功能是否可行?
在整個子系統的范圍內,又能分解成什么子功能集?
在整個子系統的范圍內,又能把哪些子功能合并到某些構件中去?
這些構件與子功能集是如何通過接口與子系統銜接的?
事實上子系統架構設計本身就是一個完整的系統設計,所區別的是視野集中到子系統的
范圍內,這個階段的活動如下:
校驗與確認前期與該子系統相關的業務架構與產品架構的信息,必要的時候補充相
應的信息。
增補與本子系統相關的術語字典,確保所有的相關人員對術語有相同的認知。
把整個子系統功能進行拆分,并且分解到不同的構件節點上,構建不同的子功能集,
在子系統范圍內劃分接口與交互規則。
匯總子系統/構件接口信息,便于檢索與瀏覽。
規劃整個子系統的通信鏈路、通信路徑、通信網絡等傳輸媒介。
把產品架構概念中的子業務職能與構件功能相對應,從而確保滿足業務要求。
分析子系統/構件在運行起動態協作需要交互的信息。
構建和模擬整個子系統在業務環境下的動態特性,規劃子系統內部狀態變化過程、
觸發的事件及約束條件。
詳細匯總各個構件間信息傳遞的過程、內容以及其它輔助信息。
根據初始的數據模型構建子系統相關的更詳細的數據物理模型。
根據質量上對子系統的要求,并把這些質量要求細化分解,量化到各個構件中去。
構建整子系統的構建和演化計劃,在迭代過程中構建子系統項目規劃和更詳細地的
迭代規劃。
按固定時段預測技術的演化,匯總子系統的應用技術及其演化。
分辨與匯總子系統在不同階段必須遵循的標準。
把業務約束映射到各個構件,必要時附加 IT 業務約束。
五、構件與實現單元的設計
進入構件設計階段也就是進入了詳細設計階段。這個階段主要的工作就是接口與功能設
計。在迭代模型下,這個階段很大程度上是在迭代過程中完成的,由某個設計人員帶領全體
開發團隊進行分析和設計。
在這個過程中,我們應該考慮在小粒度架構中如何使產品需求變更不至于對產品質量造
成影響,還需要考慮業務概念模型與產品功能塊有相應的追溯和回溯關系。這些問題,我們
將會在后面用適當的篇幅進行討論。
小結:
大型復雜項目的成功依賴于合理的項目組織,這種組織概念包括人力資源的組織和產品
架構的組織兩個方面。敏捷項目管理為這兩種合理的組織提供了思維基礎,為項目的成功提
供了保證。一個典型的例子是 20 世紀 90 年代加拿大空中交通系統項目(首席架構師:Philippe
Kruchten)。150 個程序員被組織到 6 個月的長周期迭代中。但是,即使在 6 個月的迭代中,
10~20 人的子系統,仍然把任務分解成一連串 6 個為期一個月的小迭代。正是這個項目的
實踐成功,Philippe Kruchten 才成為 RUP 的首倡者。
敏捷過程的提出直接影響到架構設計的核心思維,正是因為敏捷過程的提出,才有了架
構驅動、彈性架構和骨架系統這些理念。也直接影響到需求分析方法、項目規劃和估計方法
等一系列領域的新思維。甚至推動了業務敏捷以及與之相適應的基于服務的架構的提出。這
些觀念的提出又更加推動了軟件工程學向更高的層次發展。
下面我們將討論幾個專題,但討論的時候希望研究一種思考問題的方法,從而為大家解
決更廣闊的問題提供一個思維的平臺。這些專題并不是獨立存在,而是融合在本章所討論的
各個階段之中。再一次強調,方法和技術是會變化的,但優秀的思維方式是永恒的!
從MVC框架看MVC架構的設計
從MVC框架看MVC架構的設計
盡管MVC早已不是什么新鮮話題了,但是從近些年一些優秀MVC框架的設計上,我們還是會發現MVC在架構設計上的一些新亮點。本文將對傳統MVC架構中的一些弊病進行解讀,了解一些優秀MVC框架是如何化解這些問題的,揭示其中所折射出的設計思想與設計理念。
MVC回顧
作為一種經典到不能再經典的架構模式,MVC的成功有其必然的道理,這個道理不同的人會有不同的解讀,筆者最認同的一種觀點是:通過把職責、性質相近的成分歸結在一起,不相近的進行隔離,MVC將系統分解為模型、視圖、控制器三部分,每一部分都相對獨立,職責單一,在實現過程中可以專注于自身的核心邏輯。MVC是對系統復雜性的一種合理的梳理與切分,它的思想實質就是“關注點分離”。至于MVC三元素的職責劃分與相互關系,這里不再贅述,下圖給出了非常細致的說明。
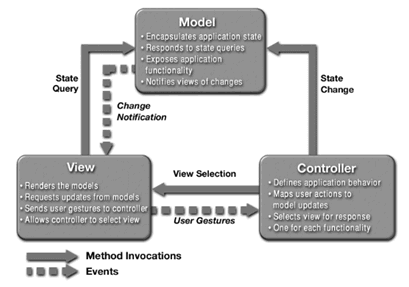
圖1:MVC組件的功能和關系[i]
View與Controller的解耦:mediator+二次事件委派
筆者早年開發基于swing的GUI應用時,在架構MVC的實踐過程中深刻體會到了view與controller之間的緊密耦合問題。在很多事件驅動的GUI框架里,如swing,用戶對view的任何操作都會觸發一個事件,然后在listener的響應方法里進行處理。如果讓view自己注冊成為事件的listener,則必須要在view中加入對controller的引用,這不是MVC希望看到的,因為這樣view和controller就形成了緊密的耦合關系。若將controller注冊為listener,則事件響應將由controller承擔,這又會導致controller處理其不該涉及的展現邏輯,造成view和controller難以解耦的原因在于:多數的用戶請求都包含一定成分的展現邏輯和一定成分的業務邏輯,兩種邏輯揉合在一個請求里,在處理的時候,view與controller很難合理地分工。解決這一問題的關鍵是要在view與controller之間建立一種可以將展現邏輯與業務邏輯進行有效分割的機制,在這方面,PureMVC[ii]的設計非常值得參考,它通過引入mediator+二次事件委派機制很好的解決了view與controller之間的緊耦合問題。
Mediator是一種設計模式,這種模式在組件化的圖形界面框架中似乎有著普遍的應用場景,即使是在四人幫的《設計模式》一書中,也使用了一個圖形界面程序的示例來講解mediator。mediator的設計用意在于通過一個媒介對象,完成一組對象的交互,避免對象間相互引用,產生復雜的依賴關系。mediator應用于圖形界面程序時,往往作為一組關系緊密的圖形組件的交互媒介,完成組件間的協調工作(比如點選某一按鈕,其他組件將不可用)。在PureMVC中,mediator被廣泛應用,其定位也發生了微妙的變化,它不再只是圖形組件間的媒介,同時也成為了圖形組件與command之間的媒介,這使得它不再是可選的,而是成為了架構中的必需設施。對應到傳統MVC架構中,mediator就是view與controller之間的媒介(當然,也依然是view之間的媒介),所有從view發出的用戶請求都經過了mediator再傳遞給controller,它的出現在一定程度上緩解了view與controller的緊密耦合問題。
當view、mediator和controller三者被定義出來,并進行了清晰的職責劃分后,剩下的問題就是如何將它們串聯起來,以完成一個用戶請求了,在這方面,事件機制起到了至關重要的作用。事件機制可以讓當前對象專注于處理其職責范圍內的事務,而不必關心超出部分由誰來處理以及怎樣處理,當前對象只需要廣播一個事件,就會有對此事件感興趣的其他對象出來接手下一步的工作,當前對象與接手對象之間不存在直接依賴,甚至感知不到彼此的存在,這是事件機制被普遍認為是一種松耦合機制的重要原因。講到這里插一句題外話,在領域驅動設計(Domain-Driven Design)里,著名的Domain Event模式也是有賴于事件機制的這一特性被創造出來的,其用意正是為了保證領域模型的純凈,避免領域模型對repository和service的直接依賴。回到PureMVC, 我們來看在處理用戶請求的過程中,事件機制是如何串聯view、mediator和controller的。在PureMVC里,當一個用戶請求下達時,圖形組件先在自身的事件響應方法中實現與自身相關的展現邏輯,然后收集數據,將數據置入一個新的event中,將其廣播出去,這是第一次事件委派。這個event會被一個mediator監聽到,如果處理該請求需要其他圖形組件的協助,mediator會協調它們處理應由它們承擔的展現邏輯,然后mediator再次發送一個event(這次的event在PureMVC里稱之為notification),這個event會促使某個command執行,完成業務邏輯的計算,這是第二次事件委派。在兩次事件委派中,第一次事件委派讓當事圖形組件完成“處理其職責范圍內的展現邏輯”后,得以輕松“脫身”,免于被“協調其他圖件處理剩余展現邏輯”和“選擇并委派業務對象處理業務邏輯”所拖累。而“協調其他圖形組件處理剩余展現邏輯”顯然是mediator的職責,于是第一次廣播的事件被委派給了mediator. mediator在完成圖形組件的協調工作后,并不會插手“選擇并委派業務對象處理業務邏輯”的工作,這不是它的職責,因此,第二次事件委派發生了,一個新的event由mediator廣播出去,后被某個command響應到,由command完成了最后的工作——“選擇并委派業務對象處理業務邏輯”。
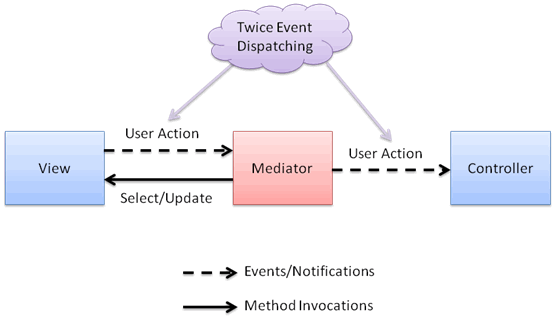
圖2:mediator+二次事件委派機制
總結起來,PureMVC是通過在view與controller之間引入mediator,讓view與controller變成間接依賴,用戶請求從view到mediator,再從mediator到controller均以事件方式委派,mediator+二次事件委派的組合可以說是一種“強力”的解耦機制,它實現了view與controller之間的完全解耦。
從Controller到Command,自然粒度的回歸
目前,很多平臺的主流MVC框架在設計上都引入了command模式,command模式的引入改變了傳統MVC框架的結構,受沖擊最大的就是controller。在過去傳統的MVC架構里,一個controller可能有多個方法,每個方法往往對應一個user action,因此,一個 controller往往對應多個user action,而在基于command的MVC架構里,一個command往往只對應一個user action。傳統MVC架構里將一個user action委派到某個controller的某個方法的過程,在基于command的MVC架構里變成了將useraction與command一一綁定的過程。如果說傳統controller的管理方式是在user action與model之間建立“集中式”的映射,那么基于command的管理方式就是在user action與model之間建立“點對點式”的直連映射。
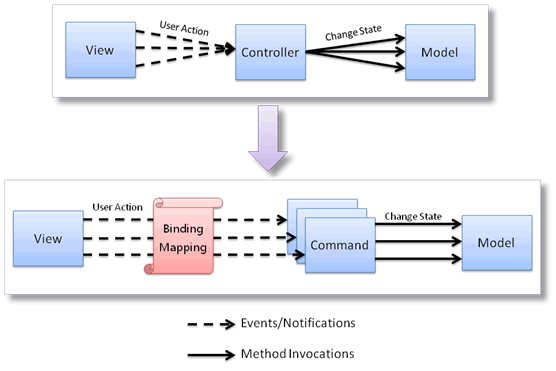
圖3:從基于Controller到基于Command的架構演進
主流MVC框架向command轉型是有原因的,除了command自身的優勢之外,一個非常重要的原因就是:由于缺少合理的組織依據,controller的粒度很難拿捏。controller不同于view與model,view與model都有各自天然的粒度組織依據,view的組織粒度直接承襲用戶界面設計,model的組織粒度則是依據某種分析設計思想(如OOA/D)進行領域建模的結果,controller需要同時協調view與model,但是view與model的組織結構和粒度都是不對等的,這就使得controller面臨一個“在多大視圖范圍內溝通與協調多少領域對象”的問題,由于找不出合理的組織依據,設計者在設計controller時往往感到無所適從。相比之下,command則完全沒有controller的困惑,因為command有一個天然的組織依據,這就是user action。針對一個user action設計一個command,然后將兩者映射在一起,是一件非常自然而簡單的事情。不過,需要說明的是這并不意味著所有command的粒度是一樣的,因為不同的user action所代表的業務量是不同的,因此也決定了command是有“大”有“小”的。遵循良好的設計原則,對某些較“大”的command進行分解,從中抽離出一些可復用的部分封裝成一些較“小”的command是值得推薦的。很多MVC框架就定義了一些相關的接口和抽象類用于支持基于組合模式的命令拼裝。
不管是基于controller還是基于command,MVC架構中界定的“協調view與model交互”的控制器職責是不會變的,都需要相應的組件和機制去承載與實現。在基于command的架構里,command承擔了過去controller的部分職責,從某種意義上說 command是一種細粒度的controller,但是command的特性是偏“被動”的。一方面,它對于view和model的控制力比controller弱化了很多, 比如,一般情況下command是不會直接操縱view的。另一方面,它不知道自己與什么樣的user action映射在了一起,也不知道自己會在何種情況下被觸發執行。支撐command的運行需要額外的注冊、綁定和觸發機制,是這些機制加上command一起實現了controller的職責。由于現在多數基于command的MVC框架都實現并封裝了這些重要的機制,所以從某種意義上說,是這些框架自身扮演了controller角色。
小結
本文主要分析了過去傳統MVC架構中存在的兩大弊病:view與controller的緊密耦合以及controller粒度難以把控的問題,介紹了一些MVC框架是如何應對這些問題的,這些設計方案所體現出的優秀設計思想是非常值得學習的。
[i] 圖片來源:http://java.sun.com/blueprints/patterns/MVC-detailed.html
[ii] PureMVC是一種MVC框架,最初使用ActionScript 3實現,現在在多種語言平臺上有實現版本。官方站點:http://puremvc.org/
更多精彩博文:
領域驅動設計(Domain Driven Design)參考架構詳解
關于垂直切分Vertical Sharding的粒度
企業應用集成與開源ESB產品ServiceMix和Mule介紹
論基于數據訪問的集合類(Data Access Based Collection)和領域事件(Domain Event)模式
關于系統異常設計的再思考
前車之覆,后車之鑒——開源項目經驗談
前車之覆,后車之鑒
——開源項目經驗談
(本文發表于《程序員》2005年第2期)
隨著開源文化的日益普及,“參與開源”似乎也變成了一種時尚。一時間,似乎大家都樂于把自己的代碼拿出來分享了。就在新年前夕,我的一位老朋友、一位向來對開源嗤之以鼻的J2EE架構師竟然也發布了一個開源的J2EE應用框架(姑且稱之為“X框架”),不得不令我驚嘆開源文化的影響力之強大。
可惜開源并非免費的午餐,把源碼公開就意味著要承受眾目睽睽的審視。僅僅幾天之后,國內幾位資深的J2EE架構師就得出一個結論:細看之下,X框架不管從哪個角度都只能算一個失敗的開源項目。究竟是什么原因讓一個良好的愿望最終只能得到一個失敗的結果?本文便以X框架為例,點評初涉開源的項目領導者常犯的一些錯誤,指出投身開源應當遵循的一些原則,為后來的開源愛好者掃清些許障礙。
成熟度
打開X框架在SourceForge的項目站點,我們立刻可以看到:在“Development Status”一欄赫然寫著“5 – Production/Stable”。也就是說,作者認為X框架已經成熟穩定,可以交付用戶使用。那么,現在對其進行評估便不應該有為時過早之嫌。可是,X框架真的已經做好準備了嗎?
打開從SourceForge下載的X框架的源碼包,筆者不禁大吃一驚:壓縮包里真的只有源碼——編譯、運行整個項目所需的庫文件全都不在其中。從作者自己的論壇得知,該項目需要依賴JBoss、JDOM、Castor、Hibernate等諸多開源項目,筆者只好自己動手下載了這些項目,好一番折騰總算是在Eclipse中成功編譯了整個項目。
不需要對開源文化有多么深刻的了解,只要曾經用過一些主流的開源產品,你就應該知道:一個開源軟件至少應該同時提供源碼發布包和二進制發布包,源碼包中至少應該有所有必需的依賴庫文件(或者把依賴庫單獨打包發布)、完整的單元測試用例(對于Java項目通常是Junit測試套件)、以及執行編譯構建的腳本(對于Java項目通常是Ant腳本或者Maven腳本),但這些內容在X框架的發布包中全都不見蹤影。用戶如果想要使用這個框架,就必須像筆者一樣手工下載所有的依賴庫,然后手工完成編譯和構建,而且構建完成之后也無從知曉其中是否有錯誤存在(因為沒有單元測試)。這樣的發布形式,算得上是“Production/Stable”嗎?
| 開源必讀:便捷構建 開源軟件應該提供最便捷的構建方式,讓用戶可以只輸入一條命令就完成整個項目的編譯、構建和測試,并得到可運行的二進制程序。對于Java項目,這通常意味著提供完整的JUnit測試套件和Ant腳本。你的潛在用戶可能會在一天之內試用所有類似的開源軟件,如果一個軟件需要他用半天時間才能完成構建、而且還無從驗證正確性、無從著手編寫他自己的測試用例,這個軟件很可能在第一時間被扔到墻角。 |
從SourceForge的項目頁面可以看到,X框架的授權協議是Apache License V2.0(APL)。然而在它的發布包中,筆者沒有看到任何形式的正式授權協議文本。眾所周知,SourceForge的項目描述是可以隨時修改的(X框架本身的授權協議就曾經是GPL),如果發布包中沒有一份正式的授權協議文本,一旦作者修改了SourceForge的項目描述,用戶又該到哪里去尋找證據支持自己的合法使用呢?
在X框架的源碼中,大部分源文件在開始處加上了APL的授權聲明,但有一部分源碼很是令人擔心。例如UtilCache這個類,開始處沒有任何授權聲明,而JavaDoc中則這樣聲明作者信息:
@author???? <a href="mailto:jonesde@ofbiz.org">David E. Jones</a>
也就是說,這個類的源碼來自另一個開源項目Ofbiz。值得一提的是,Ofbiz一直是“商業開源”的倡導者,它的授權協議相當嚴格。凡是使用Ofbiz源碼,必須將它的授權協議一并全文復制。像X框架這樣復制Ofbiz源碼、卻刪掉了授權協議的行為,實際上已經構成了對Ofbiz的侵權。
另外,作者打包用的壓縮格式是RAR,而這個壓縮格式對于商業用戶是收費的。對于一個希望在商業項目中應用的框架項目來說,選擇這樣一個壓縮格式實在算不得明智。而且筆者在源碼包中還看到了好幾個.jbx文件,這是JBuilder的項目描述文件。把這些JBuilder專用的文件放在源碼包中,又怎能讓那些買不起或是不想買JBuilder的用戶放心呢?更何況,出于朋友的關心,筆者還不得不擔心X框架的作者是否會收到Borland公司的律師信呢。
| 開源必讀:授權先行 在啟動一個開源項目時,第一件大事就是要確定自己的授權協議,并在最醒目的地方用最正式的方式向所有人聲明——當然,在此之前你必須首先了解各種開源授權協議。譬如說,GPL(Linux采用的授權協議)要求在軟件之上的擴展和衍生也必須繼承GPL,因此這種協議對軟件的商業化應用很不友好;相反,APL則允許用戶將軟件的擴展產物私有化,便于商業應用,卻不利于開發者社群的發展。作為一個開源項目的領導者,對于各種授權協議的利弊是不可不知的。 除了源碼本身的授權協議之外,軟件需要使用的類庫、IDE、解壓工具等等都需要考慮授權問題。開源絕對不僅僅意味著“免費使用”,開源社群的人們有著更加強烈的版權意識和法律意識。如果你的開源軟件會給用戶帶來潛在的法律麻煩,它離著被拋棄的命運也就不遠了。 |
可以看到,不管從法律的角度還是從發布形式的角度,X框架都遠夠不上“Production/Stable”的水準——說實在的,以它的成熟度,頂多只能算是一個尚未計劃周全的開源項目。雖然作者在自己的網站上大肆宣傳,但作為一個潛在的用戶,我不得不冷靜地說:即便X框架的技術真的能夠吸引我,但它遠未成熟的項目形態決定了它根本無法在任何有實際意義的項目中運用。要讓商業用戶對它產生興趣,作者需要做的工作還很多。
我剛才說“即便X框架的技術真的能夠吸引我”,這算得上是一個合理的假設嗎?下面,就讓我們進入這個被作者寄予厚望的框架內部,看看它的技術水平吧。
整體架構
在X框架的宣傳頁面上,我們看到了這樣的宣傳詞:
X框架解決了以往J2EE開發存在的諸多問題:EJB難用、J2EE層次復雜、DTO太亂、Struts繞人、緩存難做性能低等。X框架是Aop/Ico[注:應為“IoC”,此處疑似筆誤]的實現,優異的緩存性能是其優點。
下面是X框架的整體架構圖:

可以看到,在作者推薦的架構中,EJB被作為業務邏輯實現的場所,而POJO被用于實現Fa?ade。這是一個好的技術架構嗎?筆者曾在一篇Blog中這樣評價它[1]:
讓我們先回想一下,使用EJB的理由是什么?常見的答案有:可分布的業務對象;聲明性的基礎設施服務(例如事務管理)。那么,如果在EJB的上面再加上一層POJO的Fa?ade,顯然你不能再使用EJB的基礎設施了,因為完整的業務操作(也就是事務邊界)將位于POJO Fa?ade的方法這里,所以你必須重新——以聲明性的方式——實現事務管理、安全性管理、remoting、緩存等基礎設施服務。換句話說,你失去了 session bean的一半好處。另一方面,“可分布的業務對象”也不復存在,因為POJO本身是不能——像EJB那樣——分布的,這樣你又失去了session bean的另一半好處。
繼續回想,使用基于POJO的輕量級架構的理由是什么?常見的答案有:易于測試;便于移植;“開發-發布”周期短。而如果僅僅把POJO作為一層Fa?ade,把業務邏輯放在下面的EJB,那么你仍然無法輕易地測試業務邏輯,移植自然也無從談起了,并且每次修改EJB之后必須忍受漫長的發布周期。即便是僅僅把EJB作為O/R mapping,而不是業務邏輯的居所,你最多只能通過DAO封裝獲得比較好的業務可測性,但“修改-發布”的周期仍然很長,因為仍然有entity bean存在。也就是說,即使是往最好的方面來說,這個架構至少損失了輕量級架構的一半優點。
作為一個總結,X框架即便是在使用得最恰當的情況下,它仍然不具備輕量級架構的全部優點,至少會對小步前進的敏捷開發造成損害(因為EJB的存在),并且沒有Spring框架已經實現的基礎設施(例如事務管理、remoting等),必須重新發明這些輪子;另一方面,它也不具備EJB的任何優點,EJB的聲明性基礎設施、可分布業務對象等能力它全都不能利用。因此,可以簡單地總結說,X框架是一個這樣的架構:它結合了EJB和輕量級架構兩者各自的短處,卻拋棄了兩者各自的長處。
在不得不使用EJB的時候,一種常見的架構模式是:用session bean作為Fa?ade,用POJO實現可移植、可測試的業務邏輯。這種模式可以結合EJB和POJO兩者的長處。而X框架推薦的架構模式,雖然乍看起來也是依葫蘆畫瓢,效果卻恰恰相反,正可謂是“取其糟粕、去其精華”。
| 開源必讀:架構必須正確 在開源軟件的初始階段,功能可以不完善,代碼可以不漂亮,但架構思路必須是正確的。即使你沒有完美的實現,參與開源的其他人可以幫助你;但如果架構思路有嚴重失誤,誰都幫不了你。從近兩年容器項目的更迭就可以看出端倪:PicoContainer本身只有20個類、數百行代碼,但它有清晰而優雅的架構,因此有很多人為它貢獻外圍的功能;Avalon容器盡管提供了完備的功能,但架構的落伍迫使Apache基金會只能將其全盤廢棄。 所以如果你有志于啟動一個開源項目(尤其是框架性的項目),務必先把架構思路拿出來給整個社群討論。只要大家都認可你的架構,你就有機會得到很多的幫助;反之,恐怕你就只能得到無盡的嘲諷了。 |
技術細節
既然整體架構已經無甚可取之處,那么X框架的實現是否又像它所宣稱的那樣,能夠解決諸多問題呢?既然X框架號稱是“AOP/IoC的實現”,我們就選中這兩項技術,看看它們在X框架中的實現和應用情況。
IoC
X框架宣稱自己是一個“基于IoC的應用框架”。按照定義,框架本身就具有“業務代碼不調用框架,框架調用業務代碼”的特性,因此從廣義上來說,所有的框架必然是基于IoC模式的。所以,在框架這里,“基于IoC”通常是特指“對象依賴關系的管理和組裝基于IoC”,也就是Martin Fowler所說的Dependency Injection模式[2]:由容器統一管理組件的創建和組裝,組件本身不包含依賴查找的邏輯。那么,X框架實現IoC的情況又如何呢?
我們很快找到了ContainerWrapper這個接口,其中指定了一個POJO容器核心應該具備的主要功能:
public interface ContainerWrapper {
? public void registerChild(String name);
? public void register(String name, Class className);
? public void register(String name, Class className, Parameter[] parameters);
? public void register(String name, Object instance);
? public void start();
? public void stop();
? public Collection getAllInstances();
? public Object lookup(String name);
}
在這個接口的默認實現DefaultContainerWrapper中,這些功能被轉發給PicoContainer的對應方法。也就是說,X框架本身并沒有實現組件容器的功能,這部分功能將被轉發給其他的IoC組件容器(例如PicoContainer、Spring或HiveMind等)來實現。在ContainerWrapper接口的注釋中,我們看到了一句頗可玩味的話:
/**
?* 封裝了Container,解耦具體應用系統和PicoContainer關系。
了解IoC容器的讀者應該知道,在使用PicoContainer或Spring等容器時,絕大多數POJO組件并不需要對容器有任何依賴:它們只需要是最普通的JavaBean,只需要實現自己的業務接口。既然對容器沒有依賴,自然也不需要“解耦”。至于極少數需要獲得生命周期回調、因此不得不依賴容器的組件,讓它們依賴PicoContainer和依賴X框架難道有什么區別嗎?更何況,PicoContainer是一個比X框架更成熟、更流行的框架,為什么用戶應該選擇X框架這么一個不那么成熟、不那么流行的框架夾在中間來“解耦”呢?
不管怎么說,至少我們可以看到:X框架提供了組件容器的核心功能。那么,IoC(或者說,Dependency Injection)在X框架中的應用又怎么樣呢?眾所周知,引入IoC容器的目標就是要消除應用程序中泛濫的工廠(包括Service Locator),由容器統一管理組件的創建和組裝。遺憾的是,不論在框架內部還是在示例應用中,我們仍然看到了大量的工廠和Service Locator。例如作者引以為傲的緩存部分,具體的緩存策略(即Cache接口的實現對象)就是由CacheFactory負責創建的,并且使用的實現類還是硬編碼在工廠內部:
? public? CacheFactory() {
cache = new LRUCache();
也就是說,如果用戶需要改變緩存策略,就必須修改CacheFactory的源代碼——請注意,這是一個X框架內部的類,用戶不應該、也沒有能力去修改它。換句話說,用戶實際上根本無法改變緩存策略。既然如此,那這個CacheFactory又有什么用呢?
| 開源必讀:開放-封閉原則 開源軟件應該遵守開放-封閉原則(Open-Close Principle,OCP):對擴展開放,對修改封閉。如果你希望為用戶提供任何靈活性,必須讓用戶以擴展(例如派生子類或配置文件)的方式使用,不能要求(甚至不能允許)用戶修改源代碼。如果一項靈活性必須通過修改源碼才能獲得,那么它對于用戶就毫無意義。 |
在示例應用中,我們同樣沒有看到IoC的身影。例如JdbcDAO需要使用數據源(即DataSource對象),它就在構造子中通過Service Locator主動獲取這個對象:
? public JdbcDAO() {
????? ServiceLocator sl = new ServiceLocator();
????? dataSource = (DataSource) sl.getDataSource(JNDINames.DATASOURCE);
同樣的情況也出現在JdbcDAO的使用者那里。也就是說,雖然X框架提供了組件容器的功能,卻沒有(至少是目前沒有)利用它的依賴注入能力,僅僅把它作為一個“大工廠”來使用。這是對IoC容器的一種典型的誤用:用這種方式使用容器,不僅沒有獲得“自動管理依賴關系”的能力,而且也失去了普通Service Locator“強類型檢查”的優點,又是一個“取其糟粕、去其精華”的設計。
| 開源必讀:了解你自己 當你決定要在開源軟件中使用某項技術時,請確定你了解它的利弊和用法。如果僅僅為了給自己的軟件貼上“基于xx技術”的標簽而使用一種自己不熟悉的技術,往往只會給你的項目帶來負面的影響。 |
AOP
在X框架的源碼包中,我們找到了符合AOP-Alliance API的一些攔截器,例如用于實現緩存的CacheInterceptor。盡管——毫不意外地——沒有找到如何將這些攔截器織入(weave in)的邏輯或配置文件,但我們畢竟可以相信:這里的確有AOP的身影。可是,甫一深入這個“基于AOP的緩存機制”內部,筆者卻又發現了更多的問題。
單從CacheInterceptor的實現來看,這是一個最簡單、也最常見的緩存攔截器。它攔截所有業務方法的調用,并針對每次方法調用執行下列邏輯:
??? IF 需要緩存
?????? key = (根據方法簽名生成key);
?????? IF (cache.get(key) == null)
??? ?????? value = (實際調用被攔截方法);
??? ??? ??? cache.put(key, value);
?????? RETURN (cache.get(key));
??? ELSE
?????? RETURN (實際調用被攔截方法);
看上去很好,基于AOP的緩存實現就應該這么做……可是,清除緩存的邏輯在哪里?如果我們把業務方法分為“讀方法”和“寫方法”兩種,那么這個攔截器實際上只照顧了“讀方法”的情況。而“寫方法”被調用時會改變業務對象的狀態,因此必須將其操作的業務對象從緩存中清除出去,但這部分邏輯在CacheInterceptor中壓根不見蹤影。如果緩存內容不能及時清理的話,用戶從緩存中取出的信息豈不是完全錯誤的嗎?
被驚出一身冷汗之后,筆者好歹還是從幾個Struts action(也就是調用POJO Fa?ade的client代碼)中找到了清除緩存的邏輯。原來X框架所謂“基于AOP的緩存機制”只實現了一條腿:“把數據放入緩存”和“從緩存中取數據”的邏輯確實用攔截器實現了,但“如何清除失效數據”的邏輯還得散布在所有的客戶代碼中。AOP原本就是為了把緩存這類橫切性(crosscutting)的基礎設施邏輯集中到一個模塊管理,像X框架的這個緩存實現,不僅橫切性的代碼仍然四下散布,連緩存邏輯的相關性和概念完整性都被打破了,豈不是弄巧成拙么?
| 開源必讀:言而有信 如果你在宣傳詞中承諾了一項特性,請務必在你的軟件中完整地實現它。不要僅僅提供一個半吊子的實現,更不要讓你的任何承諾放空。如果你沒有把握做好一件事,就不要承諾它。不僅對于開源軟件,對于任何軟件開發,這都是應該記住的原則。 |
更有趣的是,X框架的作者要求領域模型對象繼承Model基類,并聲稱這是為了緩存的需要——事實也的確如此:CacheInterceptor只能處理Model的子對象。但只要對緩存部分的實現稍加分析就會發現,這一要求完全是作者憑空加上的:用于緩存對象的Cache接口允許放入任何Object;而Model盡管提供了setModified()、setCacheable()等用于管理緩存邏輯的方法,卻沒有任何代碼調用它們。換句話說,即便我們修改CacheInterceptor,使其可以緩存任何Object,對X框架目前的功能也不會有任何影響。既然如此,又為什么要給用戶憑空加上這一層限制呢?
退一萬步說,即使我們認為X框架今后會用Model的方法來管理緩存邏輯,這個限制仍然是理由不足的。畢竟,目前X框架還僅僅提供了緩存這一項基礎設施(infrastructure)而已。如果所有基礎設施都用“繼承一個基類”的套路來實現,當它真正提供企業級應用所需的所有基礎設施時,Model類豈不是要變得碩大無朋?用戶的領域對象豈不是再也無法移植到這個框架之外?況且,“由領域對象判斷自己是否需要緩存”的思路本身也是錯誤的:如果不僅要緩存領域對象,還要緩存String、Integer等簡單對象,該怎么辦?如果同一個領域對象在不同的方法中需要不同的緩存策略,又該怎么辦?X框架的設計讓領域對象背負了太多的責任,而這些責任原本應該是通過AOP轉移到aspect中的。在X框架這里,AOP根本沒有發揮它應有的效用。
| 開源必讀:避免綁定 開源軟件(尤其是框架類軟件)應該盡量避免對你的用戶造成綁定。能夠在POJO上實現的功能,就不要強迫用戶實現你的接口;能夠通過接口實現的功能,就不要強迫用戶繼承你的基類。尤其是Java語言只允許單根繼承,一旦要求用戶的類繼承框架基類,那么前者就無法再繼承其他任何基類,這是一種非常嚴重的綁定,不論用戶和框架設計者都應當極力避免。 |
寫在最后
看完這篇多少有些尖刻的批評,恐怕讀者難免要怪責我“不厚道”——畢竟,糟糕的開源軟件堪比恒河沙數,為什么偏要選中X框架大加撻伐呢?在此,我要給各位讀者、各位有志于開源的程序員一個最后、卻是最重要的建議:
| 開源必讀:切忌好大喜功 開源是一件長期而艱巨的工作,對于只能用業余時間參與的我們更是如此。做開源務必腳踏實地,做出產品首先在小圈子里內部討論,然后逐漸擴大宣傳的圈子。切勿吹大牛、放衛星,把“未來的愿景”當作“今天的承諾”來說——因為一旦工作忙起來,誰都不敢保證這個愿景到哪天才能實現。 國人還有個愛好:凡事喜歡趕個年節“獻禮”,或是給自己綁上個“民族軟件”的旗號,這更是開源的大忌。凡是做過政府項目的程序員,想必都對“國慶獻禮”、“新年獻禮”之類事情煩不勝煩,輪到自己做開源項目時,又何苦把自己套進這個怪圈里呢?當然,如果你的開源項目原本就是做給某些官老爺看的,那又另當別論。 |
所以,我的這位朋友怕也不能怪我刻薄:要不是他緊趕著拿出個遠未完善的版本“新年獻禮”,要不是他提前放出“AOP/IoC”的衛星,要不是他妄稱這個框架“代表民族軟件水平”,或許我還會夸他的代碼頗有可看之處呢。有一句大家都熟悉的老話,筆者私以為所有投身開源者頗可借鑒,在此與諸位共勉:
長得丑不是你的錯……
[1] 這篇Blog的原文請看:http://gigix.blogdriver.com/gigix/474041.html。
[2] 關于IoC模式和Dependency Injection模式,詳見Martin Fowler的《Dependency Injection與模式IoC容器》一文。(中譯本發表于《程序員》2004年第3期。
軟件的架構與設計模式之什么是架構
什么是軟件系統的架構(Architecture)?一般而言,架構有兩個要素:·它是一個軟件系統從整體到部分的最高層次的劃分。
一個系統通常是由元件組成的,而這些元件如何形成、相互之間如何發生作用,則是關于這個系統本身結構的重要信息。
詳細地說,就是要包括架構元件(Architecture Component)、聯結器( Connector)、任務流( Task-flow)。所謂架構元素,也就是組成系統的核心"磚瓦",而聯結器則描述這些元件之間通訊的路徑、通訊的機制、通訊的預期結果,任務流則描述系統如何使用這些元件和聯結器完成某一項需求。
·建造一個系統所作出的最高層次的、以后難以更改的,商業的和技術的決定。
在建造一個系統之前會有很多的重要決定需要事先作出,而一旦系統開始進行詳細設計甚至建造,這些決定就很難更改甚至無法更改。顯然,這樣的決定必定是有關系統設計成敗的最重要決定,必須經過非常慎重的研究和考察。
計算機軟件的歷史開始于五十年代,歷史非常短暫,而相比之下建筑工程則從石器時代就開始了,人類在幾千年的建筑設計實踐中積累了大量的經驗和教訓。建筑設計基本上包含兩點,一是建筑風格,二是建筑模式。獨特的建筑風格和恰當選擇的建筑模式,可以使一個獨一無二。
下面的照片顯示了 中美洲古代瑪雅建筑,Chichen-Itza大金字塔,九個巨大的石級堆壘而上,九十一級臺階(象征著四季的天數)奪路而出,塔頂的神殿聳入云天。所有的數字都如日歷般嚴謹,風格雄渾。難以想象這是石器時代的建筑物。
 圖1、位于墨西哥Chichen-Itza(在瑪雅語中chi意為嘴chen意為井)的古瑪雅建筑。(攝影:作者) |
軟件與人類的關系是架構師必須面對的核心問題,也是自從軟件進入歷史舞臺之后就出現的問題。與此類似地,自從有了建筑以來,建筑與人類的關系就一直是建筑設計師必須面對的核心問題。 英國首相丘吉爾說,我們 構造建筑物,然后建筑物構造我們(We shape our buildings, and afterwards our buildings shape us)。英國下議院的會議廳較狹窄,無法使所有的下議院議員面向同一個方向入座,而必須分成兩側入座。丘吉爾認為,議員們入座的時候自然會選擇與自己政見相同的人同時入座,而這就是英國政黨制的起源。Party這個詞的原意就是"方"、"面"。政黨起源的關鍵就是建筑物對人的影響。
在軟件設計界曾經有很多人認為功能是最為重要的,形式必須服從功能。與此類似地,在建筑學界,現代主義建筑流派的開創人之一Louis Sullivan也認為形式應當服從于功能(Forms follows function)。
幾乎所有的軟件設計理念都可以在浩如煙海的建筑 學歷史中找到更為遙遠的歷史回響。最為著名的,當然就是模式理論和XP理論。
架構的目標是什么
正如同軟件本身有其要達到的目標一樣,架構設計要達到的目標是什么呢?一般而言,軟件架構設計要達到如下的目標:
·可靠性(Reliable)。軟件系統對于用戶的商業經營和管理來說極為重要,因此軟件系統必須非常可靠。
·安全行( Secure)。軟件系統所承擔的交易的 商業價值極高,系統的 安全性非常重要。
·可擴展性(Scalable)。軟件必須能夠在用戶的使用率、用戶的數目增加很快的情況下,保持合理的性能。只有這樣,才能適應用戶的市場擴展得可能性。
·可定制化(Customizable)。同樣的一套軟件,可以根據客戶群的不同和市場需求的變化進行調整。
·可擴展性(Extensible)。在新技術出現的時候,一個軟件系統應當允許導入新技術,從而對現有系統進行功能和性能的擴展
·可維護性(Maintainable)。軟件系統的維護包括兩方面,一是排除現有的 錯誤,二是將新的軟件需求反映到現有系統中去。一個易于維護的系統可以有效地降低技術支持的花費
·客戶體驗(Customer Experience)。軟件系統必須易于使用。
·市場時機( Time to Market)。軟件用戶要面臨同業競爭,軟件提供商也要面臨同業競爭。以最快的速度爭奪市場先機非常重要。
架構的種類
根據我們關注的角度不同,可以將架構分成三種:
·邏輯架構、軟件系統中元件之間的關系,比如用戶界面,數據庫,外部系統接口,商業邏輯元件,等等。
比如下面就是筆者親身經歷過的一個軟件系統的邏輯架構圖
 圖2、一個邏輯架構的例子 |
從上面這張圖中可以看出,此系統被劃分成三個邏輯層次,即表象層次,商業層次和數據持久層次。每一個層次都含有多個邏輯元件。比如 WEB服務器層次中有 HTML服務元件、Session服務元件、 安全服務元件、 系統管理元件等。
·物理架構、軟件元件是怎樣放到硬件上的。
比如下面這張物理架構圖描述了一個分布于北京和上海的 分布式系統的物理架構,圖中所有的元件都是物理設備,包括網絡分流器、代理服務器、 WEB服務器、應用服務器、報表服務器、整合服務器、 存儲服務器、主機等等。
 圖3、一個物理架構的例子 |
·系統架構、系統的非功能性特征,如可擴展性、可靠性、強壯性、靈活性、性能等。
系統架構的設計要求架構師具備軟件和硬件的功能和性能的過硬知識,這一工作無疑是架構設計工作中最為困難的工作。
此外,從每一個角度上看,都可以看到架構的兩要素:元件劃分和設計決定。
首先,一個軟件系統中的元件首先是邏輯元件。這些邏輯元件如何放到硬件上,以及這些元件如何為整個系統的可擴展性、可靠性、強壯性、靈活性、性能等做出貢獻,是非常重要的信息。
其次,進行軟件設計需要做出的決定中,必然會包括邏輯結構、物理結構,以及它們如何影響到系統的所有非功能性特征。這些決定中會有很多是一旦作出,就很難更改的。
根據作者的經驗,一個基于數據庫的系統架構,有多少個數據表,就會有多少頁的架構設計文檔。比如一個中等的 數據庫應用系統通常含有一百個左右的數據表,這樣的一個系統設計通常需要有一百頁左右的架構設計文檔。
架構師
軟體設計師中有一些技術水平較高、經驗較為豐富的人,他們需要承擔軟件系統的架構設計,也就是需要設計系統的元件如何劃分、元件之間如何發生相互作用,以及系統中邏輯的、物理的、系統的重要決定的作出。
這樣的人就是所謂的架構師(Architect)。在很多公司中,架構師不是一個專門的和正式的職務。通常在一個開發小組中,最有經驗的程序員會負責一些架構方面的工作。在一個部門中,最有經驗的項目經理會負責一些架構方面的工作。
但是,越來越多的公司體認到架構工作的重要性,并且在不同的組織層次上設置專門的架構師位置,由他們負責不同層次上的邏輯架構、物理架構、系統架構的設計、配置、維護等工作。
- 快速體驗)












)
V1.0發布!)




![[轉載]建立團隊溝通協作工作方式](http://pic.xiahunao.cn/[轉載]建立團隊溝通協作工作方式)