今天本來想把昨天安裝的intellij配置好,但是一直顯示沒有網絡,網上查了相關資料也沒有查出來解決辦法。

然后暫停了intellij的配置,開始做了幾個Python爬取簡單數據的實例,先做了幾個最簡單的,以后再加大難度(用idle編碼):
(1)京東商品頁面爬取:
鏈接:https://item.jd.com/2967929.html

代碼解析:
首先r是一個response對象;
r.status_code返回一個值,如果是200的話則正常,如果時候503的話,則拋出異常,調用該方法的目的是查看返回的response對象是否正確;
r.encoding是返回編碼信息,如果編碼為gbk則表示這個網站提供了頁面信息的相關編碼;
(2)亞馬遜商品頁面的爬取:

r.status_code返回值為503,說明請求沒有得到正確的答復,這時,查看我們訪問的http的頭可知我們告訴了亞馬遜網站我們是用Python的requests庫來訪問的,并且亞馬遜拒絕了爬蟲的訪問,所以,這時我們更改了我們的頭部信息,讓爬蟲模擬一個瀏覽器來訪問,把user-agent更改為Mozolla/5.0就可以成功的訪問了。
(3)百度搜索關鍵詞提交:

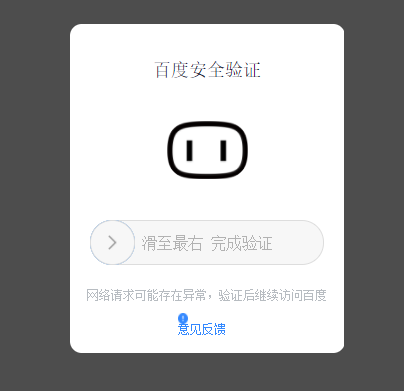
百度對關鍵詞的搜索提供了接口:http://www.baidu.com/s?wd=keyword。所以這時利用了params,將鍵字對輸入進去,但是這里當我查詢url時,并沒有正常顯示,百度利用安全認證,我把http的頭部更改為Mozilla/5.0也不起作用,還未解決。
(4)網絡圖片的爬取和存儲:
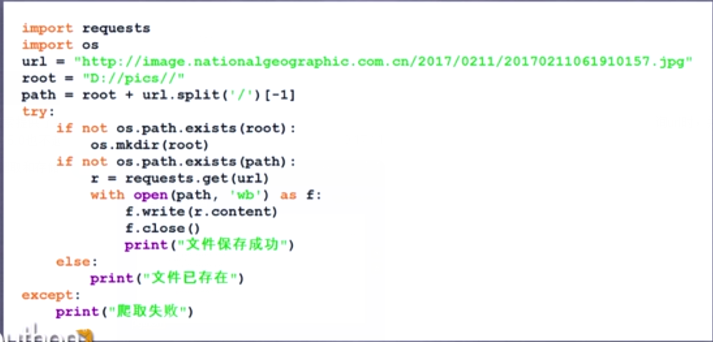
只適用于最簡單的圖片爬取,如https://gss2.bdstatic.com/fo3dSag_xI4khGkpoWK1HF6hhy/baike/c0%3Dbaike80%2C5%2C5%2C80%2C26/sign=c9162213c4fcc3cea0cdc161f32cbded/279759ee3d6d55fb3cfdd81761224f4a20a4ddcc.jpg。
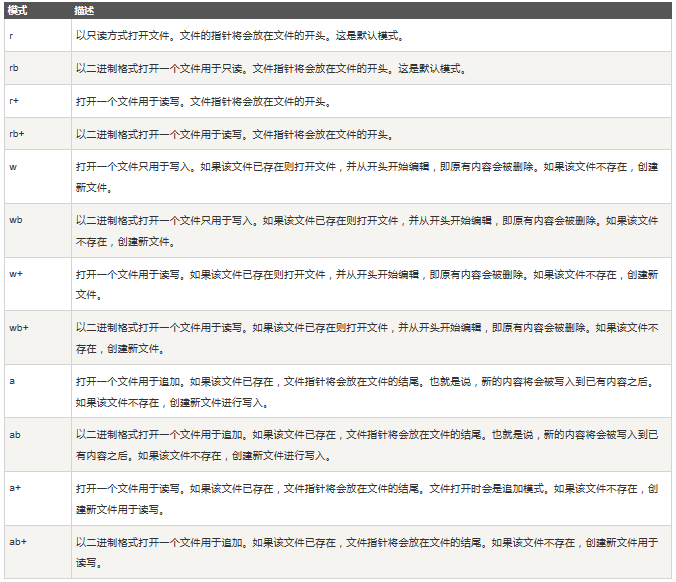
結尾是圖片文件的形式,r.content是返回內容的二進制形式,所以用write方法寫入文件中,形成jpg文件。open函數中的‘wb’是指打開文件的模式,相關模式含義如下表:

)
















)
