黃聰:Python+NLTK自然語言處理學習(一):環境搭建
http://www.cnblogs.com/huangcong/archive/2011/08/29/2157437.html
安裝NLTK可能出現的問題:
1. pip install ntlk
2. 如果遇到缺少stopwords報錯如下:(http://johnlaudun.org/20130126-nltk-stopwords/)
LookupError:
**********************************************************************
Resource u'corpora/stopwords' not found. Please use the
NLTK Downloader to obtain the resource: >>> nltk.download()
Searched in:
- 'C:\\Users\\Tree/nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- 'F:\\Program Files (x86)\\python\\nltk_data'
- 'F:\\Program Files (x86)\\python\\lib\\nltk_data'
- 'C:\\Users\\Tree\\AppData\\Roaming\\nltk_data'
**********************************************************************
則有一下輸入:
In[3]: import nltk
In[4]: nltk.download()
showing info http://www.nltk.org/nltk_data/
彈出窗口:
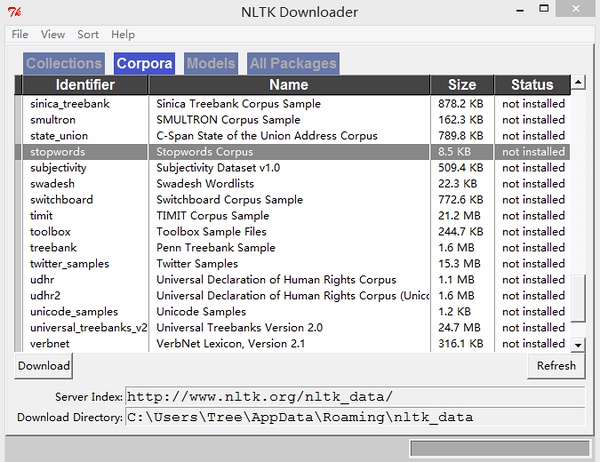 選擇Corpora 然后找到stopword list確認,刷新
選擇Corpora 然后找到stopword list確認,刷新
Out[4]: True
3.如果遇到缺少punkt報錯如下:
LookupError:
**********************************************************************
Resource u'tokenizers/punkt/english.pickle' not found. Please
use the NLTK Downloader to obtain the resource:
>>>nltk.download()
Searched in:
- 'C:\\Users\\Tree/nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- 'F:\\Program Files (x86)\\python\\nltk_data'
- 'F:\\Program Files (x86)\\python\\lib\\nltk_data'
- 'C:\\Users\\Tree\\AppData\\Roaming\\nltk_data'
**********************************************************************
解決方法
In[5]: nltk.download('punkt')
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\Tree\AppData\Roaming\nltk_data...
[nltk_data] Unzipping tokenizers\punkt.zip.
Out[5]: True
文章:http://www.52nlp.cn/%E5%A6%82%E4%BD%95%E8%AE%A1%E7%AE%97%E4%B8%A4%E4%B8%AA%E6%96%87%E6%A1%A3%E7%9A%84%E7%9B%B8%E4%BC%BC%E5%BA%A6%E4%B8%89 文章: http://www.52nlp.cn/%E5%A6%82%E4%BD%95%E8%AE%A1%E7%AE%97%E4%B8%A4%E4%B8%AA%E6%96%87%E6%A1%A3%E7%9A%84%E7%9B%B8%E4%BC%BC%E5%BA%A6%E4%B8%89
詳細講述了如何使用NLTK進行英文分詞、去除停用詞、詞干化、訓練LSI、等等文本預處理的步驟。
在使用sumy demo時候出錯:
C:\Python27\python.exe D:/Python/jieba/demo/sklearn/sumy_demo1.py
Traceback (most recent call last):
File "D:/Python/jieba/demo/sklearn/sumy_demo1.py", line 20, in
parser = HtmlParser.from_url(url, Tokenizer(LANGUAGE))
File "C:\Python27\lib\site-packages\sumy\nlp\tokenizers.py", line 33, in __init__
self._sentence_tokenizer = self._sentence_tokenizer(tokenizer_language)
File "C:\Python27\lib\site-packages\sumy\nlp\tokenizers.py", line 45, in _sentence_tokenizer
"NLTK tokenizers are missing. Download them by following command: "
LookupError: NLTK tokenizers are missing. Download them by following command: python -c "import nltk; nltk.download('punkt')"





)







:ActiveMQ結合Spring開發--建議)




)
