目錄
一、Pandas簡介
數據結構
二、Series
series 的創建
Series值的獲取
Series的運算
Series缺失值檢測
Series自動對齊
Series及其索引的name屬性
三、DataFrame
創建
Index對象
通過索引值或索引標簽獲取數據
自動化對齊
四、文件操作
文件讀取
數據庫數據讀取
將數據寫出為csv
將數據寫出為excel
將數據寫入數據庫
五、查詢數據
通過布爾索引來實現特定信息的查詢
六、統計分析
七、類似于SQL的操作
增:
刪
改:
分組聚合:groupby()函數
?排序:
多表連接:
八、缺失值處理
刪除法:直接刪除缺失值
用常數填補所有缺失值
采用前項填充或后向填充
使用常量填充不同的列
用均值或中位數填充各自的列
九、數據透視表
多層索引的使用
Numpy,Scipy,pandas三個庫的區別
- NumPy:數學計算庫,以矩陣為基礎的數學計算模塊,包括基本的四則運行,方程式以及其他方面的計算什么的,純數學;
- SciPy :科學計算庫,有一些高階抽象和物理模型,在NumPy基礎上,封裝了一層,沒有那么純數學,提供方法直接計算結果;比如:做個傅立葉變換,這是純數學的,用Numpy;做個濾波器,這屬于信號處理模型了,用Scipy。
- Pandas:提供名為DataFrame的數據結構,比較契合統計分析中的表結構,做數據分析用的,主要是做表格數據呈現。
目前來說,隨著 Pandas 更新,Numpy 大部分功能已經直接和 Pandas 融合了。
一、Pandas簡介
Python Data Analysis Library 或 pandas 是基于NumPy 的一種工具,該工具是為了解決數據分析任務而創建的。Pandas 納入了大量庫和一些標準的數據模型,提供了高效地操作大型數據集所需的工具。pandas提供了大量能使我們快速便捷地處理數據的函數和方法。你很快就會發現,它是使Python成為強大而高效的數據分析環境的重要因素之一。
Pandas是python的一個數據分析包,最初由AQR Capital Management于2008年4月開發,并于2009年底開源出來,目前由專注于Python數據包開發的PyData開發team繼續開發和維護,屬于PyData項目的一部分。Pandas最初被作為金融數據分析工具而開發出來,因此,pandas為時間序列分析提供了很好的支持。 Pandas的名稱來自于面板數據(panel data)和python數據分析(data analysis)。panel data是經濟學中關于多維數據集的一個術語,在Pandas中也提供了panel的數據類型。
數據結構
- Series:一維數組,與Numpy中的一維array類似。二者與Python基本的數據結構List也很相近,其區別是:List中的元素可以是不同的數據類型,而Array和Series中則只允許存儲相同的數據類型,這樣可以更有效的使用內存,提高運算效率。
- Time- Series:以時間為索引的Series。
- DataFrame:二維的表格型數據結構。很多功能與R中的data.frame類似。可以將DataFrame理解為Series的容器。以下的內容主要以DataFrame為主。
- Panel :三維的數組,可以理解為DataFrame的容器。
Pandas 有兩種自己獨有的基本數據結構。雖然它有著兩種數據結構,但它依然是 Python 的一個庫,所以,Python 中有的數據類型在這里依然適用,也同樣還可以使用類自己定義數據類型。只不過,Pandas 里面又定義了兩種數據類型:Series 和 DataFrame,它們讓數據操作更簡單了。
二、Series
Series 在python的中type()為 <class 'pandas.core.series.Series'>。
series 的創建
- 通過一維數組創建,如果沒有為數據指定索引值,會自動創建一個0-N-1的索引
- 通過字典的方式創建,字典的key為索引
# series 的創建:數組方式
arr=np.array([1,3,5,np.NaN,10])
ser1=pd.Series(arr)
print(ser1)
print(ser1.dtype) # 獲取series的元素的數據類型
print(ser1.index) # 獲取series的索引
print(ser1.values) # 獲取series的值
0 ? ? 1.0
1 ? ? 3.0
2 ? ? 5.0
3 ? ? NaN
4 ? ?10.0
dtype: float64
float64
RangeIndex(start=0, stop=5, step=1)
[ ?1. ? 3. ? 5. ?nan ?10.]# 通過index修改索引值,且索引值可以重復
ser2=pd.Series([98,99,90])
ser2.index=['語文','數學','語文']
print(ser2)
ser3=pd.Series(data=[99,98,97],dtype=np.float64,index=['語文','數學','歷史'])
print(ser3)
語文 ? ?98
數學 ? ?99
語文 ? ?90
dtype: int64
語文 ? ?99.0
數學 ? ?98.0
歷史 ? ?97.0
dtype: float64# 通過字典的方式創建series,字典的key為series的索引值,字典的values為series的元素值
dit={'語文':90,'數學':99,'歷史':98}
ser4=pd.Series(dit)
print(ser4)
歷史 ? ?98
數學 ? ?99
語文 ? ?90
dtype: int64Series值的獲取
Series值的獲取主要有兩種方式:
- 通過方括號+索引的方式讀取對應索引的數據,有可能返回多條數據
- 通過方括號+下標值的方式讀取對應下標值的數據,下標值的取值范圍為:[0,len(Series.values)];另外下標值也可 以是負數,表示從右往左獲取數據
Series獲取多個值的方式類似NumPy中的ndarray的切片操作,通過方括號+下標值/索引值+冒號(:)的形式來截取series對象中的一部分數據!
# Series數據的獲取:下標值、索引值、切片
print('==============ser4[1]==============')
print(ser4[1])
print('==============ser4["語文"]=========')
print(ser4["語文"])
print('==============ser4[0:2]============')
print(ser4[0:2])
print("==============ser4['歷史':'語文']===")
print(ser4['歷史':'語文'])
==============ser4[1]==============
99
==============ser4["語文"]=========
90
==============ser4[0:2]============
歷史 ? ?98
數學 ? ?99
dtype: int64
==============ser4[u'歷史':u'語文']===
歷史 ? ?98
數學 ? ?99
語文 ? ?90
dtype: int64Series的運算
NumPy中的數組運算,在Series中都保留了,均可以使用,并且Series進行數組運算的時候,索引與值之間的映射關系不會發生改變。
注意:其實在操作Series的時候,基本上可以把Series看成NumPy中的ndarray數組來進行操作。ndarray數組的絕大多數操作都可以應用到Series上。
# series的部分運算
print('==============ser4[ser4>98] 布爾運算=========')
print(ser4[ser4>98])
print('==============ser4/9 除法運算================')
print(ser4/9)
print('==============np.exp(ser4) e的x次方==========')
print(np.exp(ser4))
print('==============np.log10(ser4) ? ========')
print(np.log10(ser4))
==============ser4[ser4>98] 布爾運算=========
數學 ? ?99
dtype: int64
==============ser4/9 除法運算================
歷史 ? ?10.888889
數學 ? ?11.000000
語文 ? ?10.000000
dtype: float64
==============np.exp(ser4) e的x次方==========
歷史 ? ?3.637971e+42
數學 ? ?9.889030e+42
語文 ? ?1.220403e+39
dtype: float64
==============np.log10(ser4) ? ========
歷史 ? ?1.991226
數學 ? ?1.995635
語文 ? ?1.954243
dtype: float64# 在pandas中用NaN表示一個缺省值或者NA值
print('==============ser4================')
print(ser4)
ser5=pd.Series(ser4,index=['地理','語文','歷史','數學'])
print('==============ser5================')
print(ser5)
==============ser4================
歷史 ? ?98
數學 ? ?99
語文 ? ?90
dtype: int64
==============ser5================
地理 ? ? NaN
語文 ? ?90.0
歷史 ? ?98.0
數學 ? ?99.0
dtype: float64Series缺失值檢測
pandas中的isnull和notnull兩個函數可以用于在Series中檢測缺失值,這兩個函數的返回時一個布爾類型的Series
print('==============pd.isnull(ser5)================')
print(pd.isnull(ser5))
print('==============ser5[pd.isnull(ser5)]===========')
print(ser5[pd.isnull(ser5)])
print('==============pd.notnull(ser5)================')
print(pd.notnull(ser5))
print('==============ser5[pd.notnull(ser5)]==========')
print(ser5[pd.notnull(ser5)])
==============pd.isnull(ser5)================
地理 ? ? True
語文 ? ?False
歷史 ? ?False
數學 ? ?False
dtype: bool
==============ser5[pd.isnull(ser5)]===========
地理 ? NaN
dtype: float64
==============pd.notnull(ser5)================
地理 ? ?False
語文 ? ? True
歷史 ? ? True
數學 ? ? True
dtype: bool
==============ser5[pd.notnull(ser5)]==========
語文 ? ?90.0
歷史 ? ?98.0
數學 ? ?99.0
dtype: float64Series自動對齊
當多個series對象之間進行運算的時候,如果不同series之間具有不同的索引值,那么運算會自動對齊不同索引值的數據,如果某個series沒有某個索引值,那么最終結果會賦值為NaN。
ser6=pd.Series(data=[99,98,97],index=['語文','數學','歷史'])
ser7=pd.Series(data=[99,98,97,100],index=['語文','數學','歷史','文言文'])
print('==============ser6+ser7================')
print(ser6+ser7)
print('==============ser6-ser7================')
print(ser6-ser7)
print('==============ser6*ser7================')
print(ser6*ser7)
print('==============ser6/ser7================')
print(ser6/ser7)
print('==============ser6**ser7================')
print(ser6**ser7)
==============ser6+ser7================
歷史 ? ? 194.0
數學 ? ? 196.0
文言文 ? ? ?NaN
語文 ? ? 198.0
dtype: float64
==============ser6+ser7================
歷史 ? ? 0.0
數學 ? ? 0.0
文言文 ? ?NaN
語文 ? ? 0.0
dtype: float64
==============ser6+ser7================
歷史 ? ? 9409.0
數學 ? ? 9604.0
文言文 ? ? ? NaN
語文 ? ? 9801.0
dtype: float64
==============ser6+ser7================
歷史 ? ? 1.0
數學 ? ? 1.0
文言文 ? ?NaN
語文 ? ? 1.0
dtype: float64
==============ser6+ser7================
歷史 ? ? 5.210246e+192
數學 ? ? 1.380878e+195
文言文 ? ? ? ? ? ? ?NaN
語文 ? ? 3.697296e+197
dtype: float64Series及其索引的name屬性
Series對象本身以及索引都具有一個name屬性,默認為空,根據需要可以進行賦值操作
ser8=pd.Series(data=[99,98,97],index=['Dov','Drld','Heil'])
ser8.name='語文'
ser8.index.name='考試成績' # 像不像索引的列名
print(ser8)
考試成績
Dov ? ? 99
Drld ? ?98
Heil ? ?97
Name: 語文, dtype: int64三、DataFrame
創建
DateFrame 在python的中type()為 <class 'pandas.core.frame.DataFrame'>
DateFrame的創建主要有三種方式:
1)通過二維數組創建數據框
arr2 = np.array(np.arange(16)).reshape(4,4)
df1 = pd.DataFrame(arr2)0? ?1? ?2? ?3
0 0? ?1? ?2? ?3
1 4? ?5? ?6? ?7
2 8? ?9? ?10 11
3 12 13? 14 15從這個輸出我們可以看到,默認的索引和列名都是[0, N-1]的形式。我們可以在創建DataFrame的時候指定列名和索引,像這樣:
df2 = pd.DataFrame(np.arange(16).reshape(4,4),columns=["column1", "column2", "column3", "column4"],index=["a", "b", "c", "d"])
print("df2:\n{}\n".format(df2))
# 結果如下column1 column2 column3 column4
a 0? ? ? ? ? ? ? 1? ? ? ? ? ? ? ? 2? ? ? ? ? ? ? ?3
b 4? ? ? ? ? ? ? 5? ? ? ? ? ? ? ?6? ? ? ? ? ? ? ?7
c 8? ? ? ? ? ? ? 9? ? ? ? ? ? ? ? 10? ? ? ? ? ? ? 11
d 12? ? ? ? ? ? 13? ? ? ? ? ? ? ?14? ? ? ? ? ? 15請注意:DataFrame的不同列可以是不同的數據類型。如果以Series數組來創建DataFrame,每個Series將成為一行,而不是一列,例如:
noteSeries = pd.Series(["C", "D", "E", "F", "G", "A", "B"],index=[1, 2, 3, 4, 5, 6, 7])
weekdaySeries = pd.Series(["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"],index=[1, 2, 3, 4, 5, 6, 7])
df4 = pd.DataFrame([noteSeries, weekdaySeries])
print("df4:\n{}\n".format(df4))
# df4的輸出如下:1 2 3 4 5 6 7
0 C D E F G A B
1 Mon Tue Wed Thu Fri Sat Sun
2)通過字典的方式創建數據框
以下以兩種字典來創建數據框,一個是字典列表,一個是嵌套字典。
dic2 = {'a':[1,2,3,4],'b':[5,6,7,8],'c':[9,10,11,12],'d':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
dic3 = {'one':{'a':1,'b':2,'c':3,'d':4},'two':{'a':5,'b':6,'c':7,'d':8},'three':{'a':9,'b':10,'c':11,'d':12}}
df3 = pd.DataFrame(dic3)# 結果如下:a b c d
0 1 5 9 13
1 2 6 10 14
2 3 7 11 15
3 4 8 12 16one two three
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
字典的“鍵”("name","marks","price")就是 DataFrame 的 columns 的值(名稱),字典中每個“鍵”的“值”是一個列表,它們就是那一豎列中的具體填充數據。
上面的dic2定義中沒有確定索引,所以,按照慣例(Series 中已經形成的慣例)就是從 0 開始的整數。從上面的結果中很明顯表示出來,這就是一個二維的數據結構(類似 excel 或者 mysql 中的查看效果)。
上面的數據顯示中,columns 的順序沒有規定,就如同字典中鍵的順序一樣,但是在 DataFrame 中,columns 跟字典鍵相比,有一個明顯不同,就是其順序可以被規定,比如:
dic2_1 = DataFrame(dic2,columns=['b','a','c','d'])Index對象
通過索引值或索引標簽獲取數據
pandas的Index對象包含了描述軸的元數據信息。當創建Series或者DataFrame的時候,標簽的數組或者序列會被轉換成Index。可以通過下面的方式獲取到DataFrame的列和行的Index對象:
dic3 = {'one':{'a':1,'b':2,'c':3,'d':4},'two':{'a':5,'b':6,'c':7,'d':8},'three':{'a':9,'b':10,'c':11,'d':12}}
df3 = pd.DataFrame(dic3)
print(df3.columns) # 輸出:Index(['one', 'two', 'three'], dtype='object')
print(df3.index) # 輸出:Index(['a', 'b', 'c', 'd'], dtype='object')Index并非集合,因此其中可以包含重復的數據
Index對象的值是不可以改變,因此可以通過它安全的訪問數據
DataFrame提供了下面兩個操作符來訪問其中的數據:
print(df3[['one','two']]) # df3[列索引]
print(df3.loc[['a','b'], ['one','two']]) # loc[行索引,列索引]
print(df3.iloc[[0, 1], 0]) # iloc[行下標,列下標]# 第二行代碼訪問了行索引為a和b,列索引為'one','two'的元素。第三行代碼訪問了行下標為0和1(對于df3來說,行索引和行下標剛好是一樣的,所以這里都是0和1,但它們卻是不同的含義),列下標為0的元素。one two
a 1 5
b 2 6
c 3 7
d 4 8one two
a 1 5
b 2 6a 1
b 2
Name: one, dtype: int64
自動化對齊
如果有兩個序列,需要對這兩個序列進行算術運算,這時索引的存在就體現的它的價值了—自動化對齊.
s5 = pd.Series(np.array([10,15,20,30,55,80]),index = ['a','b','c','d','e','f'])
s6 = pd.Series(np.array([12,11,13,15,14,16]),index = ['a','c','g','b','d','f'])
s5 + s6
s5/s6
# 結果如下
a 22.0
b 30.0
c 31.0
d 44.0
e NaN
f 96.0
g NaN
dtype: float64a 0.833333
b 1.000000
c 1.818182
d 2.142857
e NaN
f 5.000000
g NaN
dtype: float64
由于s5中沒有對應的g索引,s6中沒有對應的e索引,所以數據的運算會產生兩個缺失值NaN。注意,這里的算術結果就實現了兩個序列索引的自動對齊,而非簡單的將兩個序列加總或相除。對于數據框的對齊,不僅僅是行索引的自動對齊,同時也會自動對齊列索引(變量名)
DataFrame中同樣有索引,而且DataFrame是二維數組的推廣,所以其不僅有行索引,而且還存在列索引,關于數據框中的索引相比于序列的應用要強大的多,這部分內容將放在數據查詢中講解。
四、文件操作
文件讀取
pandas庫提供了一系列的read_函數來讀取各種格式的文件,它們如下所示:
- read_csv
- read_table
- read_fwf
- read_clipboard
- read_excel
- read_hdf
- read_html
- read_json
- read_msgpack
- read_pickle
- read_sas
- read_sql
- read_stata
- read_feather
接下來我們看一個讀取Excel的簡單的例子:
import pandas as pd
import numpy as np
df1 = pd.read_excel("data/test.xlsx")
print("df1:\n{}\n".format(df1))
# 這個Excel的內容如下:
df1:
C Mon
0 D Tue
1 E Wed
2 F Thu
3 G Fri
...
我們再來看讀取CSV文件的例子,
df2 = pd.read_csv("data/test1.csv")
print("df2:\n{}\n".format(df2))
# 結果如下
df2:
C,Mon
D,Tue
E,Wed
F,Thu
...如果分隔符不是,我們可以通過指定分隔符的方式來讀取這個文件,像這樣:
df3 = pd.read_csv("data/test2.csv", sep="|")read_csv支持非常多的參數用來調整讀取的參數,如下表所示:
| 參數 | 說明 |
|---|---|
| path | 文件路徑 |
| sep或者delimiter | 字段分隔符 |
| header | 列名的行數,默認是0(第一行) |
| index_col | 列號或名稱用作結果中的行索引 |
| names | 結果的列名稱列表 |
| skiprows | 從起始位置跳過的行數 |
| na_values | 代替NA的值序列 |
| comment | 以行結尾分隔注釋的字符 |
| parse_dates | 嘗試將數據解析為datetime。默認為False |
| keep_date_col | 如果將列連接到解析日期,保留連接的列。默認為False。 |
| converters | 列的轉換器 |
| dayfirst | 當解析可以造成歧義的日期時,以內部形式存儲。默認為False |
| data_parser | 用來解析日期的函數 |
| nrows | 從文件開始讀取的行數 |
| iterator | 返回一個TextParser對象,用于讀取部分內容 |
| chunksize | 指定讀取塊的大小 |
| skip_footer | 文件末尾需要忽略的行數 |
| verbose | 輸出各種解析輸出的信息 |
| encoding | 文件編碼 |
| squeeze | 如果解析的數據只包含一列,則返回一個Series |
| thousands | 千數量的分隔符 |
詳細的read_csv函數說明請參見這里:pandas.read_csv
注:UTF-8以字節為編碼單元,它的字節順序在所有系統中都是一様的,沒有字節序的問題,也因此它實際上并不需要BOM(“ByteOrder Mark”)。但是UTF-8 with BOM即utf-8-sig需要提供BOM。簡單的說,utf-8-sig是對字節編碼有序的。
這種情況發生在pandas在read csv的時候,如果報錯,
key error,??File "pandas/index.pyx", line 137, in pandas.index.IndexEngine.get_loc (pandas/index.c:4154)
File "pandas/index.pyx", line 159, in pandas.index.IndexEngine.get_loc (pandas/index.c:4018)
File "pandas/hashtable.pyx", line 675, in pandas.hashtable.PyObjectHashTable.get_item (pandas/hashtable.c:12368)
File "pandas/hashtable.pyx", line 683, in pandas.hashtable.PyObjectHashTable.get_item (pandas/hashtable.c:12322)
這種情況要考慮使用utf-8-sig這種編碼,即encdoinf='utf-8-sig'遇到中文亂碼的時候也可以試試改成這個編碼
數據庫數據讀取
read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, chunksize=None)
- sql:表示抽取數據的SQL語句,例如'select * from 表名'
- con:表示數據庫連接的名稱
- index_col:表示作為索引的列,默認為0-行數的等差數列
read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
- table_name:表示抽取數據的表名
- con:表示數據庫連接的名稱
- index_col:表示作為索引的列,默認為0-行數的等差數列
- columns:數據庫數據讀取后的列名。
read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
- sql:表示抽取數據的表名或者抽取數據的SQL語句,例如'select * from 表名'
- con:表示數據庫連接的名稱
- index_col:表示作為索引的列,默認為0-行數的等差數列
- columns:數據庫數據讀取后的列名。
建議:用前兩個
# 讀取數據庫
from sqlalchemy import create_engine
conn = create_engine('mysql+pymysql://root:root@127.0.0.1/test?charset=utf8', encoding='utf-8', echo=True)
# data1 = pd.read_sql_query('select * from data', con=conn)
# print(data1.head())data2 = pd.read_sql_table('data', con=conn)
print(data2.tail())
print(data2['X'][1])數據庫連接字符串各參數說明
'mysql+pymysql://root:root@127.0.0.1/test?charset=utf8'
連接器://用戶名:密碼@數據庫所在IP/訪問的數據庫名稱?字符集將數據寫出為csv
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression=None, quoting=None, quotechar='"', line_terminator='\n', chunksize=None, tupleize_cols=False, date_format=None, doublequote=True, escapechar=None, decimal='.')
- path_or_buf:數據存儲路徑,含文件全名例如'./data.csv'
- sep:表示數據存儲時使用的分隔符
- header:是否導出列名,True導出,False不導出
- index: 是否導出索引,True導出,False不導出
- mode:數據導出模式,'w'為寫
- encoding:數據導出的編碼
import pandas as pd
data.to_csv('data.csv',index = False)將數據寫入數據庫
DataFrame.to_sql(name, con, flavor=None, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)
- name:數據存儲表名
- con:表示數據連接
- if_exists:判斷是否已經存在該表,'fail'表示存在就報錯;'replace'表示存在就覆蓋;'append'表示在尾部追加
- index: 是否導出索引,True導出,False不導出
from sqlalchemy import create_engine
conn =create_engine('mysql+pymysql://root:root@127.0.0.1/data?charset=utf8', encoding='utf-8', echo=True)
data.to_sql('data',con = conn)五、查詢數據
data.shape # 查看數據的形狀
data.columns # 查看所有的列名
data.index # 查看索引
data.dtypes # 查看每一列數據的類型
data.ndim # 查看數據的維度# 查詢前幾行 或 后幾行
data.head(5)
data.tail(5)# 注意當我們提取了一列,Pandas將返回一個series,而不是一個數組
data['X'] # 取出單獨某一列
data[['X','Y']] # 取出多列,如果多個列的話,必須使用雙重中括號
data['X'][1] # 取出某列的某一行
data['X'][:10] # 取出某列的某幾行
data[['X','Y']][:10] # 取出某幾列的某幾行# loc方法索引'''DataFrame.loc[行名,列名]'''
data.loc[1,['X','月份']] # 取出某幾列的某一行
data.loc[1:5,['X','月份']] # 取出某幾列的某幾行(連續)
data.loc[[1,3,5],['X','月份']] # 取出某幾列的某幾行
data.loc[range(0,21,2),['X','FFMC','DC']] # 取出 x ,FFMC ,DC的0-20行所有索引名稱為偶數的數據# iloc方法索引'''DataFrame.iloc[行位置,列位置]'''
data.iloc[1,[1,4]] # 取出某幾列的某一行
data.iloc[0:21:2,0:data.shape[1]:2] # 取出列位置為偶數,行位置為0-20的偶數的數據# ix方法索引'''DataFrame.ix[行位置/行名,列位置/列名]'''
# 取出某幾列的某一行
data.ix[1:4,[1,4]]
data.ix[1:4,1:4]loc,iloc,ix的區別
- loc使用名稱索引,閉區間
- iloc使用位置索引,前閉后開區間
- ix使用名稱或位置索引,且優先識別名稱,其區間根據名稱/位置來改變。不建議使用ix,容易發生混淆的情況,并且運行效率低于loc和iloc,pandas考慮在后期會移除這一索引方法
通過布爾索引來實現特定信息的查詢
student[student['sex'] == F] # 查詢所有性別為女生的信息
student[(student['sex'] == F) & (stuent['age'] > 18)] # 多條件查詢,查詢所有性別為女且年齡大于18歲的信息
student[(student['sex'] == F) & (stuent['age'] > 18)] [['name' , 'height']] # 查詢性別為女,年齡大于18的學生的姓名 和 體重
六、統計分析
pandas模塊為我們提供了非常多的描述性統計分析的指標函數
對于DataFrame,默認統計的是列的數據,如果想要統計行的,需要加axis=1
np.random.seed(1234)
d1 = pd.Series(2*np.random.normal(size = 100)+3)
d2 = np.random.f(2,4,size = 100)
d3 = np.random.randint(1,100,size = 100)d1.count() # 非空元素計算
d1.min() # 最小值
d1.max() # 最大值
d1.idxmin() # 最小值的位置,類似于R中的which.min函數
d1.idxmax() # 最大值的位置,類似于R中的which.max函數
d1.quantile(0.1) # 10%分位數
d1.sum() # 求和
d1.mean() # 均值
d1.median()# 中位數
d1.mode() # 眾數
d1.var() # 方差
d1.std() # 標準差
d1.mad() # 平均絕對偏差
d1.skew() # 偏度
d1.kurt() # 峰度d1.sum() # 求和,默認列
d1.sum(axis=1) # 求和,行上述方法一維和二維均可用。
# 一次性輸出多個描述性統計指標,descirbe方法只能針對序列或數據框,一維數組是沒有這個方法的
d1.describe()
# student['Sex'].describe()
'''
count:非空值的數目
mean:數值型數據的均值
std:數值型數據的標準差
min:數值型數據的最小值
25%:數值型數據的下四分位數
50%:數值型數據的中位數
75%:數值型數據的上四分位數
max:數值型數據的最大值
''
?
相關系數(Correlation coefficient):反映兩個樣本/樣本之間的相互關系以及之間的相關程度。在COV的基礎上進行了無量綱化操作,也就是進行了標準化操作
協方差(Covariance, COV):反映兩個樣本/變量之間的相互關系以及之間的相關程度。
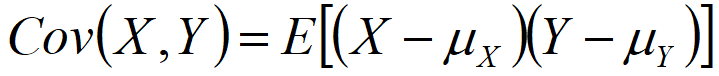
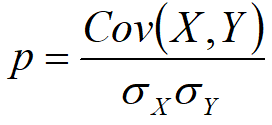
df.corr() # 相關系數
df.cov() # 協方差
df.corr('spearman') # 相關系數的計算可以調用pearson方法或kendell方法或spearman方法,默認使用pearson方法
df.corrwith(df['x1']) # 如果只想關注某一個變量與其余變量的相關系數的話,可以使用corrwith,如下方只關心x1與其余變量的相關系數?
轉置
df3.T對軸進行排序
a.sort_index(axis=1,ascending=False);
# 其中axis=1表示對所有的columns進行排序,下面的數也跟著發生移動。后面的ascending=False表示按降序排列,參數缺失時默認升序。對DataFrame中的值排序
a.sort(columns='x') # 即對a中的x這一列,從小到大進行排序。注意僅僅是x這一列,而上面的按軸進行排序時會對所有的columns進行操作。unique方法用于獲取Series中的唯一值數組(去重數據后的數組)
value_counts方法用于計算一個Series中各值的出現頻率
isin方法用于判斷矢量化集合的成員資格,可用于選取Series中或者DataFrame中列中數據的子集
# unique() 對于dataframe必須要指定是哪一列,對于series可以直接使用unique
df7["數學"].unique()
array([78, 89, 90], dtype=int64)# value_counts()對于dataframe必須要指定是哪一列,對于series可以直接使用value_counts
df7["數學"].value_counts()
89 ? ?2
78 ? ?1
90 ? ?1
Name: 數學, dtype: int64
mask=[89,90]print(df7.isin(mask))
print("========================================")
print(df7[df7.isin(mask)])age ? ? 歷史 ? ? 數學 ? ? 語文
one ? ?False ? True ?False ?False
two ? ?False ?False ? True ?False
three ?False ?False ? True ?False
four ? False ?False ? True ? True
========================================age ? ?歷史 ? ?數學 ? ?語文
one ? ?NaN ?90.0 ? NaN ? NaN
two ? ?NaN ? NaN ?89.0 ? NaN
three ?NaN ? NaN ?89.0 ? NaN
four ? NaN ? NaN ?90.0 ?90.0七、類似于SQL的操作
增:
添加新行或增加新列.可以通過concat函數實現 pd.contat([student,student2])
在數據庫中union必須要求兩張表的列順序一致,而這里concat函數可以自動對齊兩個數據框的變量!
對于新增的列沒有賦值,就會出現空NaN的形式。
其他方式
In [105]: data['new'] = 'token' # 增加列
In [106]: data
Out[106]:name price new
0 BTC 50000 token
1 ETH 4000 token
2 EOS 150 tokenIn [109]: data.loc['3'] = ['ae',200,'token'] # 增加行
In [110]: data
Out[110]:name price type
0 BTC 50000 token
1 ETH 4000 token
2 EOS 150 token
3 ae 200 token刪
# 使用drop()。該方法返回的是Copy而不是視圖,要想真正在原數據里刪除行,設置inplace=True;
# axis:0,表示刪除行;1,表示刪除列。
data.drop('列',axis=1,inplace=True)
data.drop('行',axis=0,inplace=True)# del
del data # 刪除對象,該命令可以刪除Python的所有對象
del data['type'] # 刪除列改:
結合布爾索引直接賦值即可
?
分組聚合:groupby()函數
# 分組
group1 = data.groupby('性別')
group2 = data.groupby(['入職時間','性別'])# 查看有多少組
group1.size()用groupby方法分組后的結果并不能直接查看,而是被存在內存中,輸出的是內存地址。實際上分組后的數據對 象GroupBy類似Series與DataFrame,是pandas提供的一種對象。?
Groupby對象常見方法
Grouped對象的agg方法
Grouped.agg(函數或包含了字段名和函數的字典)
# 第一種情況
group[['年齡','工資']].agg(min)# 對不同的列進行不同的聚合操作
group.agg({'年齡':max,'工資':sum})# 上述過程中使用的函數均為系統math庫所帶的函數,若需要使用pandas的函數則需要做如下操作
group.agg({'年齡':lambda x:x.max(),'工資':lambda x:x.sum()})根據性別分組,計算各組別中學生身高和體重的平均值:
如果不對原始數據作限制的話,聚合函數會自動選擇數值型數據進行聚合計算。如果不想對年齡計算平均值的話,就需要剔除改變量:
groupby還可以使用多個分組變量,例如根本年齡和性別分組,計算身高與體重的平均值:
還可以對每個分組計算多個統計量:

排序:
我們可以使用order、sort_index和sort_values實現序列和數據框的排序工作
我們再試試降序排序的設置:
上面兩個結果其實都是按值排序,并且結果中都給出了警告信息,即建議使用sort_values()函數進行按值排序。
在數據框中一般都是按值排序,例如:
多表連接:
連接分內連接和外連接,在數據庫語言中通過join關鍵字實現,pandas我比較建議使用merger函數實現數據的各種連接操作。
如下是構造一張學生的成績表:
現在想把學生表student與學生成績表score做一個關聯,該如何操作呢?
默認情況下,merge函數實現的是兩個表之間的內連接,即返回兩張表中共同部分的數據。可以通過how參數設置連接的方式,left為左連接;right為右連接;outer為外連接。
左連接實現的是保留student表中的所有信息,同時將score表的信息與之配對,能配多少配多少,對于沒有配對上的Name,將會顯示成績為NaN。
八、缺失值處理
現實生活中的數據是非常雜亂的,其中缺失值也是非常常見的,對于缺失值的存在可能會影響到后期的數據分析或挖掘工作,那么我們該如何處理這些缺失值呢?常用的有三大類方法,即刪除法、填補法和插值法。
- 刪除法:當數據中的某個變量大部分值都是缺失值,可以考慮刪除改變量;當缺失值是隨機分布的,且缺失的數量并不是很多是,也可以刪除這些缺失的觀測。
- 替補法:對于連續型變量,如果變量的分布近似或就是正態分布的話,可以用均值替代那些缺失值;如果變量是有偏的,可以使用中位數來代替那些缺失值;對于離散型變量,我們一般用眾數去替換那些存在缺失的觀測。
- 插補法:插補法是基于蒙特卡洛模擬法,結合線性模型、廣義線性模型、決策樹等方法計算出來的預測值替換缺失值。
| 方法 | 說明 |
| dropna | 根據標簽的值中是否存在缺失數據對軸標簽進行過濾(刪除), 可以通過閾值的調節對缺失值的容忍度 |
| fillna | 用指定值或者插值的方式填充缺失數據,比如: ffill或者bfill |
| isnull | 返回一個含有布爾值的對象,這些布爾值表示那些值是缺失值NA |
| notnull | isnull的否定式 |
刪除法:直接刪除缺失值
默認情況下,數據中只要含有缺失值NaN,該數據行就會被刪除,如果使用參數how=’all’,則表明只刪除所有行為缺失值的觀測。
用常數填補所有缺失值
采用前項填充或后向填充
使用常量填充不同的列
用均值或中位數填充各自的列
很顯然,在使用填充法時,相對于常數填充或前項、后項填充,使用各列的眾數、均值或中位數填充要更加合理一點,這也是工作中常用的一個快捷手段。
九、數據透視表
在Excel中有一個非常強大的功能就是數據透視表,通過托拉拽的方式可以迅速的查看數據的聚合情況,這里的聚合可以是計數、求和、均值、標準差等。
pandas為我們提供了非常強大的函數pivot_table(),該函數就是實現數據透視表功能的。對于上面所說的一些聚合函數,可以通過參數aggfunc設定。我們先看看這個函數的語法和參數吧:
我們仍然以student表為例,來認識一下數據透視表pivot_table函數的用法:
對一個分組變量(Sex),一個數值變量(Height)作統計匯總
對一個分組變量(Sex),兩個數值變量(Height,Weight)作統計匯總
對兩個分組變量(Sex,Age),兩個數值變量(Height,Weight)作統計匯總
很顯然這樣的結果并不像Excel中預期的那樣,該如何變成列聯表的形式的?很簡單,只需將結果進行非堆疊操作(unstack)即可:
使用多個聚合函數
有關更多數據透視表的操作,可參考《Pandas透視表(pivot_table)詳解》一文,鏈接地址:http://python.jobbole.com/81212/
多層索引的使用
最后我們再來講講pandas中的一個重要功能,那就是多層索引。在序列中它可以實現在一個軸上擁有多個索引,就類似于Excel中常見的這種形式:
對于這樣的數據格式有什么好處呢?pandas可以幫我們實現用低維度形式處理高維數數據,這里舉個例子也許你就能明白了:
對于這種多層次索引的序列,取數據就顯得非常簡單了:
對于這種多層次索引的序列,我們還可以非常方便的將其轉換為數據框的形式:
以上針對的是序列的多層次索引,數據框也同樣有多層次的索引,而且每條軸上都可以有這樣的索引,就類似于Excel中常見的這種形式:
我們不妨構造一個類似的高維數據框:
同樣,數據框中的多層索引也可以非常便捷的取出大塊數據:
在數據框中使用多層索引,可以將整個數據集控制在二維表結構中,這對于數據重塑和基于分組的操作(如數據透視表的生成)比較有幫助。
就拿student二維數據框為例,我們構造一個多層索引數據集:
http://www.cnblogs.com/nxld/p/6058591.html
https://www.cnblogs.com/lingLongBaby/p/7147378.html
http://www.cnblogs.com/WoLykos/p/9349581.html
https://www.cnblogs.com/zuizui1204/p/6423069.html
稱獲取 當前機器的IP地址與子網掩碼信息)












)





)