特征工程-概念
特征工程是一個面向十分廣的概念,只要是在處理數據就可以認為是在做特征工程。個人理解,真正意義上的特征工程還是數據降維和數據升維的過程。
而前期對數據的處理過程:
- 需要哪些數據?
- 數據如何存儲?
- 數據如何清洗?
將這三步歸納到數據準備的過程。
1、需要哪些數據?根據領導提出的一個分析要求,我們需要構思自己需要哪些數據,這個時候我們要和企業中的運維人員進行溝通,看看運維人員能夠提供哪些數據。
2、數據如何存儲?一般如果不是那種需要一個人頂十個人的超級創業公司,像數據存儲的工作一般不會交給我們去完成。
3、數據如何清洗?對我們來說,數據準備過程中最關鍵的第一步操作是如何對數據進行清洗。比如數據庫中存的是作者和文章所在的url地址。我們可以對作者進行啞編碼的操作,對url地址返回的文章進行詞袋法的處理,等等。
4、數據特征工程。數據特征工程和數據清洗有時候概念的邊界比較模糊。有些在數據清理過程中也會遇到特征選擇的問題,但很多時候數據本身特征就少,你再做個特征選擇就更加欠擬合了。總的來說實際情況實際分析。
一、需要哪些數據?
在進行機器學習之前,收集數據的過程中,我們主要按照以下規則找出我們所需要的數據:
- 業務的實現需要哪些數據?
基于對業務規則的理解,盡可能多的找出對因變量有影響的所有自變量數據。
- 數據可用性評估
在獲取數據的過程中,首先需要考慮的是這個數據獲取的成本;
獲取得到的數據,在使用之前,需要考慮一下這個數據是否覆蓋了所有情況以及這個數據的可信度情況。
- 一般公司內部做機器學習的數據源:
- 用戶行為日志數據:記錄的用戶在系統上所有操作所留下來的日志行為數據...
- 業務數據:商品/物品的信息、用戶/會員的信息...
- 第三方數據:爬蟲數據、購買的數據、合作方的數據...
PS:入職第一周可能就是讓你拿數據,熟悉數據來源,這樣后續工作也好上手。
二、數據如何存儲?
一般情況下,用于后期模型創建的數據都是存在在本地磁盤、關系型數據庫或者一些相關的分布式數據存儲平臺的。
- 本地磁盤
- MySQL
- Oracle
- HBase
- HDFS
- Hive
三、數據清洗
數據清洗(data cleaning)是在機器學習過程中一個不可缺少的環節,其數據的清洗結果直接關系到模型效果以及最終的結論。在實際的工作中,數據清洗通常占開發過程的50%-80%左右的時間。推薦一本書
數據清洗過程:
1、數據預處理
在數據預處理過程主要考慮兩個方面,如下:
- 選擇數據處理工具:關系型數據庫或者Python
- 查看數據的元數據以及數據特征:一是查看元數據,包括字段解釋、數據來源等一切可以描述數據的信息;另外是抽取一部分數據,通過人工查看的方式,對數據本身做一個比較直觀的了解,并且初步發現一些問題,為之后的數據處理做準備。
注意:建模和做特征之前,要先了解字段含義,來源,再用data.describe() 抽取一部分數據通過人工查看,進一步分析。
作為研究者,我們不能為了完成任務而完成任務,至少在數據層面上必須要嚴謹,做出來的模型必須要起到作用。很多時候,客戶要求模型的準確率達到98%,不過也許我們能給出的模型一般在91%~92%,但是必須保證我們分析的數據是絕對有用的,有解釋意義的。這樣的模型也許在指標上沒有完成客戶的需求,但模型也是有價值的。
反之有些分析師為了獲得更好的模型評分,強行加入一些沒有意義的奇怪數據,這樣一來在當前的數據集中能夠跑出很好的評分,到了實際運用中結果會很差。這就是過擬合。
2、格式內容清洗
一般情況下,數據是由用戶/訪客產生的,也就有很大的可能性存在格式和內容上不一致的情況,所以在進行模型構建之前需要先進行數據的格式內容清洗操作。格式內容問題主要有以下幾類:
- 時間、日期、數值、半全角等顯示格式不一致:直接將數據轉換為一類格式即可,該問題一般出現在多個數據源整合的情況下。
- 內容中有不該存在的字符:最典型的就是在頭部、中間、尾部的空格等問題,這種情況下,需要以半自動校驗加半人工方式來找出問題,并去除不需要的字符。
- 內容與該字段應有的內容不符:比如姓名寫成了性別、身份證號寫成手機號等問題。
3、邏輯錯誤清洗
主要是通過簡單的邏輯推理發現數據中的問題數據,防止分析結果走偏,主要包含以下幾個步驟:
- 數據去重
- 去除/替換不合理的值
- 去除/重構不可靠的字段值(修改矛盾的內容)
4、去除不需要的數據
一般情況下,我們會盡可能多的收集數據,但是不是所有的字段數據都是可以應用到模型構建過程的,也不是說將所有的字段屬性都放到構建模型中,最終模型的效果就一定會好,實際上來講,字段屬性越多,模型的構建就會越慢,所以有時候可以考慮將不要的字段進行刪除操作。在進行該過程的時候,要注意備份原始數據。
5、關聯性驗證
如果數據有多個來源,那么有必要進行關聯性驗證,該過程常應用到多數據源合并的過程中,通過驗證數據之間的關聯性來選擇比較正確的特征屬性,比如:汽車的線下購買信息和電話客服問卷信息,兩者之間可以通過姓名和手機號進行關聯操作,匹配兩者之間的車輛信息是否是同一輛,如果不是,那么就需要進行數據調整。
特征工程 - 數據不平衡
PS:工作中可能遇到的最大的問題是數據不均衡。
怎么去解決的? 上采樣、下采樣、SMOTE算法。
解決的效果如何? 有一點點改進,但不是很大。
事實上確實如此,很多時候即使用了上述算法對采樣的數據進行改進,但是結果反而可能更差。在業界中,對數據不均衡問題的處理確實是一件比較頭疼的問題。最好的處理方法還是:盡可能去獲得更多的那些類別比較少的數據。
數據不平衡概念
在實際應用中,數據往往分布得非常不均勻,也就是會出現“長尾現象”,即:絕大多數的數據在一個范圍/屬于一個類別,而在另外一個范圍或者另外一個類別中,只有很少的一部分數據。那么這個時候直接使用機器學習可能效果會不太少,所以這個時候需要我們進行一系列的轉換操作。
而在采樣過程中修改樣本的權重,一般做的比較少。
數據不平衡解決方案一
設置損失函數的權重,使得少數類別數據判斷錯誤的損失大于多數類別數據判斷錯誤的損失,即當我們的少數類別數據預測錯誤的時候,會產生一個比較大的損失值,從而導致模型參數往讓少數類別數據預測準確的方向偏。可以通過scikit-learn中的class_weight參數來設置權重。
數據不平衡解決方案二
下采樣/欠采樣(under sampling):從多數類中隨機抽取樣本從而減少多數類別樣本數據,使數據達到平衡的方式。
PS:比如本來樣本正負例的比例是100:1,一般使用下采樣將數據比例控制到4:1就是極限了。如果強行將正負例的比例控制到1:1,會損失很多樣本的特性,使得模型效果還不如100:1的訓練結果。
集成下采樣/欠采樣:采用普通的下采樣方式會導致信息丟失,所以一般采用集成學習和下采樣結合的方式來解決這個問題;主要有兩種方式:
1、EasyEnsemble
采用不放回的數據抽取方式抽取多數類別樣本數據,然后將抽取出來的數據和少數類別數據組合訓練一個模型;多次進行這樣的操作,從而構建多個模型,然后使用多個模型共同決策/預測。
2、BalanceCascade
利用Boosting這種增量思想來訓練模型;先通過下采樣產生訓練集,然后使用Adaboost算法訓練一個分類器;然后使用該分類器多對所有的大眾樣本數據進行預測,并將預測正確的樣本從大眾樣本數據中刪除;重復迭代上述兩個操作,直到大眾樣本數據量等于小眾樣本數據量。
擴展一個技巧:
如果參加一個比賽,我們會在模型訓練的時候將數據分成訓練集和開發集。模型提交后,比賽方會提供測試集對結果進行預測。
一般來說我們訓練集上的模型評分會在86 ~ 88%左右,開發集上的評分為82 ~ 84%,但是到了實際的測試集上,模型評分可能只有72%左右。
技巧來了:
1、一般來說測試集的數據是不帶標簽的,但是測試集依然有特征X。
2、我們都不考慮訓練集和測試集的目標Y,人為創建一列目標值Z,將訓練集中的Z都設為0,將測試集的目標Z都設為1。
3、尋找測試集的X和Z之間的映射。
4、根據這個X和Z之間的映射,使用訓練集中的X預測Z,結果肯定是組0,1向量。
5、將預測值為1的數據提出來,作為我的開發集(用來驗證我們模型的數據集合),剩下預測為0的數據作為訓練集。在這個基礎上對我的訓練數據進行調優。
這是一個在不做任何特征的情況下對模型調優的一個技巧,一般可以將模型在真實環境中的評分提高一點點。大概72%提高到74%左右。
為什么?實際上我們做訓練的目的是為了找一找比賽中人家提供給我們的訓練數據和真實數據,哪些長得比較像。將更像真實測試數據的樣本放到開發集中作為調參的標準,從而能夠提高最終的評分。雖然沒有什么科學依據,但是確實比較有效,不登大雅之堂。
數據不平衡解決方案三
Edited Nearest Neighbor(ENN): 對于多數類別樣本數據而言,如果這個樣本的大部分k近鄰樣本都和自身類別不一樣,那我們就將其刪除,然后使用刪除后的數據訓練模型。
數據不平衡解決方案四
Repeated Edited Nearest Neighbor(RENN): 對于多數類別樣本數據而言,如果這個樣本的大部分k近鄰樣本都和自身類別不一樣,那我們就將其刪除;重復性的進行上述的刪除操作,直到數據集無法再被刪除后,使用此時的數據集據訓練模型。
數據不平衡解決方案五
Tomek Link Removal: 如果兩個不同類別的樣本,它們的最近鄰都是對方,也就是A的最近鄰是B,B的最近鄰也是A,那么A、B就是Tomek Link。將所有Tomek Link中多數類別的樣本刪除。然后使用刪除后的樣本來訓練模型。
上面是對多數樣本進行刪除,下面是對少數樣本進行增加
數據不平衡解決方案六
過采樣/上采樣(Over Sampling):和欠采樣采用同樣的原理,通過抽樣來增加少數樣本的數目,從而達到數據平衡的目的。一種簡單的方式就是通過有放回抽樣,不斷的從少數類別樣本數據中抽取樣本,然后使用抽取樣本+原始數據組成訓練數據集來訓練模型;不過該方式比較容易導致過擬合一般抽樣樣本不要超過50%。
過采樣/上采樣(Over Sampling):因為在上采樣過程中,是進行是隨機有放回的抽樣,所以最終模型中,數據其實是相當于存在一定的重復數據,為了防止這個重復數據導致的問題,我們可以加入一定的隨機性,也就是說:在抽取數據后,對數據的各個維度可以進行隨機的小范圍變動,eg: (1,2,3) --> (1.01, 1.99, 3);通過該方式可以相對比較容易的降低上采樣導致的過擬合問題。
數據不平衡解決方案七
采用數據合成的方式生成更多的樣本,該方式在小數據集場景下具有比較成功的案例。常見算法是SMOTE算法,該算法利用小眾樣本在特征空間的相似性來生成新樣本。
比如:給少數樣本編號,1~100;將1、2樣本連起來,取他們的中點(期望),作為一個新的樣本。以此類推,最后可以新生成50個樣本。用這種算法一次可以提高50%的樣本量。
數據不平衡解決方案八
對于正負樣本極不平衡的情況下,其實可以換一種思路/角度來看待這個問題:可以將其看成一分類(One Class Learning)或者異常檢測(Novelty Detection)問題,在這類算法應用中主要就是對于其中一個類別進行建模,然后對所有不屬于這個類別特征的數據就認為是異常數據,經典算法包括:One Class SVM、IsolationForest等。
特征工程 - 特征轉換 - 文本特征屬性轉換
特征轉換主要指將原始數據中的字段數據進行轉換操作,從而得到適合進行算法模型構建的輸入數據(數值型數據),在這個過程中主要包括但不限于以下幾種數據的處理:
- 文本數據轉換為數值型數據
- 缺省值填充
- 定性特征屬性啞編碼
- 定量特征屬性二值化
- 特征標準化與歸一化
機器學習的模型算法均要求輸入的數據必須是數值型的,所以對于文本類型的特征屬性,需要進行文本數據轉換,也就是需要將文本數據轉換為數值型數據。常用方式如下:
- 詞袋法(BOW/TF)
- TF-IDF(Term frequency-inverse document frequency)
- HashTF
詞袋法
詞袋法(Bag of words,BOW)是最早應用于NLP和IR領域的一種文本處理模型,該模型忽略文本的語法和語序,用一組無序的單詞(words)來表達一段文字或者一個文檔,詞袋法中使用單詞在文檔中出現的次數(頻數)來表示文檔。

詞集法
詞集法(Set of words,SOW)是詞袋法的一種變種,應用的比較多,和詞袋法的原理一樣,是以文檔中的單詞來表示文檔的一種的模型,區別在于:詞袋法使用的是單詞的頻數,而在詞集法中使用的是單詞是否出現,如果出現賦值為1,否則為0。

TF-IDF
在詞袋法或者詞集法中,使用的是單詞的詞頻或者是否存在來進行表示文檔特征,但是不同的單詞在不同文檔中出現的次數不同,而且有些單詞僅僅在某一些文檔中出現(例如專業名稱等等),也就是說不同單詞對于文本而言具有不同的重要性,那么,如何評估一個單詞對于一個文本的重要性呢?
單詞的重要性隨著它在文本中出現的次數成正比增加,也就是單詞的出現次數越多,該單詞對于文本的重要性就越高。同時單詞的重要性會隨著在語料庫中出現的頻率成反比下降,也就是單詞在語料庫中出現的頻率越高,表示該單詞與常見,也就是該單詞對于文本的重要性越低。
TF-IDF(Item frequency-inverse document frequency)是一種常用的用于信息檢索與數據挖掘的常用加權技術,TF的意思是詞頻(Item Frequency),IDF的意思是逆向文件頻率(Inverse Document Frequency)。TF-IDF可以反映語料中單詞對文檔/文本的重要程度。
假設單詞用t表示,文檔用d表示,語料庫用D表示,那么N(t,D)表示包含單詞t的文檔數量,|D|表示文檔數量,|d|表示文檔d中的所有單詞數量。N(t,d)表示在文檔d中單詞t出現的次數。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
TF-IDF除了使用默認的tf和idf公式外,tf和idf公式還可以使用一些擴展之后公式來進行指標的計算,常用的公式有:

有兩個文檔,單詞統計如下,請分別計算各個單詞在文檔中的TF-IDF值以及這些文檔使用單詞表示的特征向量。

HashTF-IDF
不管是前面的詞袋法還是TF-IDF,都避免不了計算文檔中單詞的詞頻,當文檔數量比較少、單詞數量比較少的時候,我們的計算量不會太大,但是當這個數量上升到一定程度的時候,程序的計算效率就會降低下去,這個時候可以通過HashTF的形式來解決該問題。
HashTF的計算規則是:在計算過程中,不計算詞頻,而是計算單詞進行hash后的hash值的數量(有的模型中可能存在正則化操作)。
HashTF的特點:運行速度快,但是無法獲取高頻詞,有可能存在單詞碰撞問題(hash值一樣)。
Scikit-learn中進行文本特征提取
在Scikit-learn中,對于文本數據主要提供了三種方式將文本數據轉換為數值型的特征向量,同時提供了一種對TF-IDF公式改版的公式。所有的轉換方式均位于模塊:sklearn.feature_extraction.text。
| 名稱 | 描述 |
| CountVectorizer | 以詞袋法的形式表示文檔 |
| HashingVectorizer | 以HashingTF的模型來表示文檔的特征向量 |
| TfidfVectorizer | 以TF-IDF的模型來表示文檔的特征向量,等價于先做CountVectorizer,然后做TfidfTransformer轉換操作的結果 |
| TfidfTransformer | 使用改進的TF-IDF公式對文檔的特征向量矩陣(數值型的)進行重計算的操作,TFIDF=TF*(IDF+1)。備注:該轉換常應用到CountVectorizer或者HashingVectorizer之后 |
Scikit-learn中進行缺省值填充
對于缺省的數據,在處理之前一定需要進行預處理操作,一般采用中位數、均值或者眾數來進行填充,在Scikit-learn中主要通過Imputer類來實現對缺省值的填充。
案例:
啞編碼
啞編碼(OneHotEncoder):對于定性的數據(也就是分類的數據),可以采用N位的狀態寄存器來對N個狀態進行編碼,每個狀態都有一個獨立的寄存器位,并且在任意狀態下只有一位有效。啞編碼是一種常用的將特征數字化的方式。比如有一個特征屬性:[‘male’,‘female’],那么male使用向量[1,0]表示,female使用[0,1]表示。
?
二值化
二值化(Binarizer):對于定量的數據根據給定的閾值,將其進行轉換,如果大于閾值,那么賦值為1;否則賦值為0。
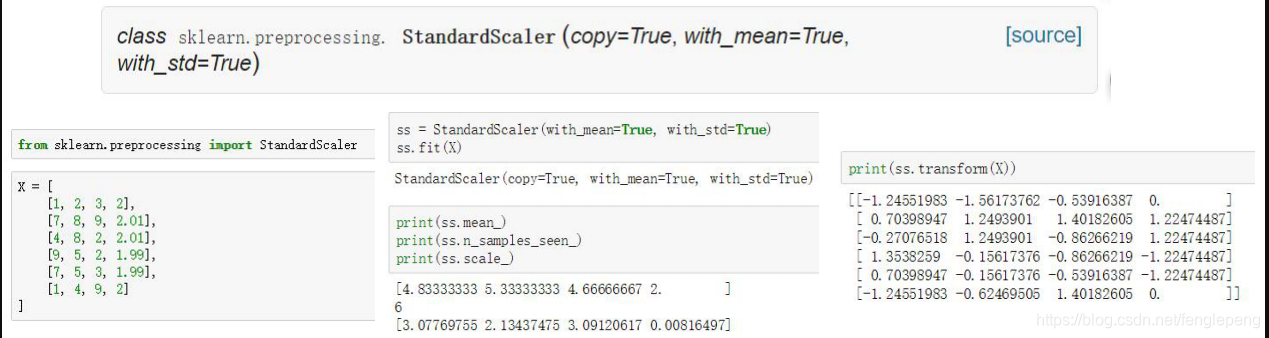
標準化
標準化:基于特征屬性的數據(也就是特征矩陣的列),獲取均值和方差,然后將特征值轉換至服從標準正態分布。計算公式如下:
區間縮放法
區間縮放法:是指按照數據的方差特性對數據進行縮放操作,將數據縮放到給定區間上,常用的計算方式如下。
歸一化
歸一化:和標準化不同,歸一化是基于矩陣的行進行數據處理,其目的是將矩陣的行均轉換為“單位向量”,l2規則轉換公式如下:
標準化、區間縮放法(歸一化)、正則化
有的書把區間縮放說為歸一化,歸一化說為正則化
標準化的目的是為了降低不同特征的不同范圍的取值對于模型訓練的影響;比如對于同一個特征,不同的樣本的取值可能會相差的非常大,那么這個時候一些異常小或者異常大的數據可能會誤導模型的正確率;另外如果數據在不同特征上的取值范圍相差很大,那么也有可能導致最終訓練出來的模型偏向于取值范圍大的特征,特別是在使用梯度下降求解的算法中;通過改變數據的分布特征,具有以下兩個好處:1. 提高迭代求解的收斂速度;2. 提高迭代求解的精度。
?
歸一化 對于不同特征維度的伸縮變換的主要目的是為了使得不同維度度量之間特征具有可比性,同時不改變原始數據的分布(相同特性的特征轉換后,還是具有相同特性)。和標準化一樣,也屬于一種無量綱化的操作方式。
正則化 則是通過范數規則來約束特征屬性,通過正則化我們可以降低數據訓練的模型的過擬合可能,和之前在機器學習中所講述的L1、L2正則的效果一樣。
備注:廣義上來講,標準化、區間縮放法、正則化都是具有類似的功能。在有一些書籍上,將標準化、區間縮放法統稱為標準化,把正則化稱為歸一化操作。
PS:如果面試有人問標準化和歸一化的區別:標準化會改變數據的分布情況,歸一化不會,標準化的主要作用是提高迭代速度,降低不同維度之間影響權重不一致的問題。
數據多項式擴充變換
多項式數據變換主要是指基于輸入的特征數據按照既定的多項式規則構建更多的輸出特征屬性,比如輸入特征屬性為[a,b],當設置degree為2的時候,那么輸出的多項式特征為?
?
GBDT/RF+LR
認為每個樣本在決策樹落在決策樹的每個葉子上就表示屬于一個類別,那么我們可以進行基于GBDT或者隨機森林的維度擴展,經常我們會將其應用在GBDT將數據進行維度擴充,然后使用LR進行數據預測,這也是我們進行所說的GBDT+LR做預測。
先通過GBDT,將原來樣本中的維度進行擴展,然后將新生成的特征放到邏輯回歸或線性回歸中進行模型構建。
特征選擇
當做完特征轉換后,實際上可能會存在很多的特征屬性,比如:多項式擴展轉換、文本數據轉換等等,但是太多的特征屬性的存在可能會導致模型構建效率降低,同時模型的效果有可能會變的不好,那么這個時候就需要從這些特征屬性中選擇出影響最大的特征屬性作為最后構建模型的特征屬性列表。
在選擇模型的過程中,通常從兩方面來選擇特征:
- 特征是否發散:如果一個特征不發散,比如方差解決于0,也就是說這樣的特征對于樣本的區分沒有什么作用
- 特征與目標的相關性:如果與目標相關性比較高,應當優先選擇
特征選擇的方法主要有以下三種:
- Filter:過濾法,按照發散性或者相關性對各個特征進行評分,設定閾值或者待選擇閾值的個數,從而選擇特征;常用方法包括方差選擇法、相關系數法、卡方檢驗、互信息法等
- Wrapper:包裝法,根據目標函數(通常是預測效果評分),每次選擇若干特征或者排除若干特征;常用方法主要是遞歸特征消除法
- Embedded:嵌入法,先使用某些機器學習的算法和模型進行訓練,得到各個特征的權重系數,根據系數從大到小選擇特征;常用方法主要是基于懲罰項的特征選擇法
方差選擇法
先計算各個特征屬性的方差值,然后根據閾值,獲取方差大于閾值的特征。
相關系數法
先計算各個特征屬性對于目標值的相關系數以及相關系數的P值,然后獲取大于閾值的特征屬性。
卡方檢驗
檢查定性自變量對定性因變量的相關性:
遞歸特征消除法
使用一個基模型來進行多輪訓練,每輪訓練后,消除若干權值系數的特征,再基于新的特征集進行下一輪訓練。
基于懲罰項的特征選擇法
在使用懲罰項的基模型,除了可以篩選出特征外,同時還可以進行降維操作。
基于樹模型的特征選擇法
樹模型中GBDT在構建的過程會對特征屬性進行權重的給定,所以GBDT也可以應用在基模型中進行特征選擇。
特征選取/降維
當特征選擇完成后,可以直接可以進行訓練模型了,但是可能由于特征矩陣過大,導致計算量比較大,訓練時間長的問題,因此降低特征矩陣維度也是必不可少的。常見的降維方法除了基于L1的懲罰模型外,還有主成分析法(PCA)和線性判別分析法(LDA),這兩種方法的本質都是將原始數據映射到維度更低的樣本空間中,但是采用的方式不同,PCA是為了讓映射后的樣本具有更大的發散性,LDA是為了讓映射后的樣本有最好的分類性能。
主成分分析(PCA)
將高維的特征向量合并成為低維度的特征屬性,是一種無監督的降維方法。
- 二維到一維降維

- 多維情況—協方差矩陣:


線性判別分析(LDA)
LDA是一種基于分類模型進行特征屬性合并的操作,是一種有監督的降維方法。

異常數據處理
缺省值是數據中最常見的一個問題,處理缺省值有很多方式,主要包括以下四個步驟進行缺省值處理:
1、確定缺省值范圍。
2、去除不需要的字段。
3、填充缺省值內容。
4、重新獲取數據。
注意:最重要的是缺省值內容填充。
一、確定缺省值范圍
在進行確定缺省值范圍的時候,對每個字段都計算其缺失比例,然后按照缺失比例和字段重要性分別指定不同的策略。
二、去除不需要的字段
在進行去除不需要的字段的時候,需要注意的是:刪除操作最好不要直接操作與原始數據上,最好的是抽取部分數據進行刪除字段后的模型構建,查看模型效果,如果效果不錯,那么再到全量數據上進行刪除字段操作。總而言之:該過程簡單但是必須慎用,不過一般效果不錯,刪除一些丟失率高以及重要性低的數據可以降低模型的訓練復雜度,同時又不會降低模型的效果。
三、填充缺省值內容
填充缺省值內容是一個比較重要的過程,也是我們常用的一種缺省值解決方案,一般采用下面幾種方式進行數據的填充:
1、以業務知識或經驗推測填充缺省值。
2、以同一字段指標的計算結果(均值、中位數、眾數等)填充缺省值。
3、以不同字段指標的計算結果來推測性的填充缺省值,比如通過身份證號碼計算年齡、通過收貨地址來推測家庭住址、通過訪問的IP地址來推測家庭/公司/學校的家。
四、重新獲取數據
如果某些指標非常重要,但是缺失率有比較高,而且通過其它字段沒法比較精準的計算出指標值的情況下,那么就需要和數據產生方(業務人員、數據收集人員等)溝通協商,是否可以通過其它的渠道獲取相關的數據,也就是進行重新獲取數據的操作。
scikit中通過Imputer類實現缺省值的填充
對于缺省的數據,在處理之前一定需要進行預處理操作,一般采用中位數、均值或者眾數來進行填充,在scikit中主要通過Imputer類來實現對缺省值的填充。
如m行n列 axis = 0 對第0個位置進行填充, 即對m進行填充,保持n不變。
按列進行填充
axis = 1 對第1個位置進行填充, 即對n進行填充,保持m不變。
按行進行填充
思考:按行填充好,還是按列填充好?
當然是按列填充好。 因為每列表示的都是屬性,我要填充,自然需要和同一個屬性內的各個值進行對比。如果按行填充,那么一個身高,一個體重的值,我們怎么分析都不知道該填充什么。
六、自然語言處理
分詞是指將文本數據轉換為一個一個的單詞,是NLP自然語言處理過程中的基礎;因為對于文本信息來講,我們可以認為文本中的單詞可以體現文本的特征信息,所以在進行自然語言相關的機器學習的時候,第一操作就是需要將文本信息轉換為單詞序列,使用單詞序列來表達文本的特征信息。
分詞: 通過某種技術將連續的文本分隔成更具有語言語義學上意義的詞。這個過程就叫做分詞。
- 自然語言處理:即實現人機間自然語言通信,或實現自然語言理解和自然語言生成。
- 主要技術:漢字詞法分析、句法分析、語義分析、文本生成、語言識別。
- 應用場景:文本分類和聚類、信息檢索和過濾、機器翻譯。
- Python中漢字分詞包:jieba,Python開發的中文分詞模塊。
- 分詞:來把連續的漢字分隔成更具有語言語義學上意義的詞。這個過程就叫做分詞。
- 分詞的常見方法:
- 詞典匹配:匹配方式可以從左到右,從右到左。對于匹配中遇到的多種分段可能性,通常會選取分隔出來詞的數目最小的
- 基于統計的方法:隱馬爾可夫模型(HMM)、最大熵模型(ME),估計相鄰漢字之間的關聯性,進而實現切分
- 基于深度學習:神經網絡抽取特征、聯合建模
- 按照文本/單詞特征進行劃分:對于英文文檔,可以基于空格進行單詞劃分。
Jieba分詞
jieba:中文分詞模塊;
Python中漢字分詞包:jieba
安裝方式: pip install jieba
Github:https://github.com/fxsjy/jieba
Jieba分詞原理
- 字符串匹配:把漢字串與詞典中的詞條進行匹配,識別出一個詞
- 理解分詞法:通過分詞子系統、句法語義子系統、總控部分來模擬人對句子的理解
- 統計分詞法:建立大規模語料庫,通過隱馬爾可夫模型或其他模型訓練,進行分詞
Jieba分詞使用
- jieba分詞模式:全模式:jieba.cut(str,cut_all=True),精確模式:jieba.cut(str),搜索引擎模式:jieba.cut_for_search(str)
- 分詞特征提取:返回TF/IDF權重最大的關鍵詞,默認返回20個,jieba.analyse.extract_tags(str,topK=20)
- 自定義詞典:幫助切分一些無法識別的新詞,加載詞典jieba.load_userdict(‘dict.txt’)
- 調整詞典:add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中動態修改詞典。使用 suggest_freq(segment, tune=True) 可調節單個詞語的詞頻
https://www.jianshu.com/p/9332b04e06d3


![git push到GitHub的時候遇到! [rejected] master -> master (non-fast-forward)的問題](http://pic.xiahunao.cn/git push到GitHub的時候遇到! [rejected] master -> master (non-fast-forward)的問題)
)



)

)
)





)


