遞歸神經網絡和循環神經網絡
- 循環神經網絡(recurrent neural network):時間上的展開,處理的是序列結構的信息,是有環圖
- 遞歸神經網絡(recursive neural network):空間上的展開,處理的是樹狀結構的信息,是無環圖
- 二者簡稱都是 RNN,但是一般提到的RNN指的是循環神經網絡(recurrent neural network)。
為什么有bp神經網絡、CNN、還需要RNN?
- BP神經網絡和CNN的輸入輸出都是互相獨立的;但是實際應用中有些場景輸出內容和之前的內 容是有關聯的。
- RNN引入“記憶”的概念;遞歸指其每一個元素都執行相同的任務,但是輸出依賴于輸入和“記憶”
什么是循環神經網絡 RNN
我們已經學習了前饋網絡的兩種結構——bp神經網絡和卷積神經網絡。這兩種結構有一個特點,就是假設輸入是一個獨立的沒有上下文聯系的單位。但是對于一些有明顯的上下文特征的序列化輸入,比如預測視頻中下一幀的播放內容,那么很明顯這樣的輸出必須依賴以前的輸入, 也就是說網絡必須擁有一定的”記憶能力”。為了賦予網絡這樣的記憶力,一種特殊結構的神經網絡——循環神經網絡(Recurrent Neural Network)便應運而生了
循環神經網絡RNN的應用場景
自然語言處理(NLP)
RNNs已經被在實踐中證明對NLP是非常成功的。如詞向量表達、語句合法性檢查、詞性標注等。在RNNs中,目前使用最廣泛最成功的模型便是LSTMs(Long Short-Term Memory,長短時記憶模型)模型,該模型通常比vanilla RNNs能夠更好地對長短時依賴進行表達,該模型相對于一般的RNNs,只是在隱藏層做了手腳。對于LSTMs,后面會進行詳細地介紹。下面對RNNs在NLP中的應用進行簡單的介紹。
自然語言處理(NLP)——語言模型與文本生成
給你一個單詞序列,我們需要根據前面的單詞預測每一個單詞的可能性。語言模型能夠一個語句正確的可能性,這是機器翻譯的一部分,往往可能性越大,語句越正確。另一種應用便是使用生成模型預測下一個單詞的概率,從而生成新的文本根據輸出概率的采樣。語言模型中,典型的輸入是單詞序列中每個單詞的詞向量(如 One-hot vector),輸出時預測的單詞序列。當在對網絡進行訓練時,如果,那么第步的輸出便是下一步的輸入。?
??下面是RNNs中的語言模型和文本生成研究的三篇文章:
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
機器翻譯
機器翻譯是將一種源語言語句變成意思相同的另一種源語言語句,如將英語語句變成同樣意思的中文語句。與語言模型關鍵的區別在于,需要將源語言語句序列輸入后,才進行輸出,即輸出第一個單詞時,便需要從完整的輸入序列中進行獲取。機器翻譯如下圖所示:?
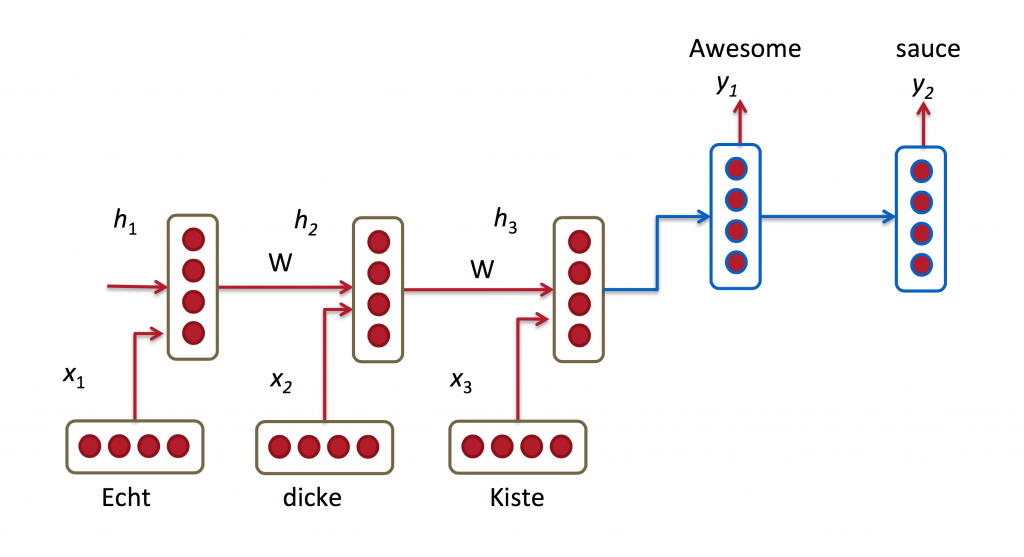
RNN for Machine Translation.?Image Source?。下面是關于RNNs中機器翻譯研究的三篇文章:
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
語音識別
語音識別是指給一段聲波的聲音信號,預測該聲波對應的某種指定源語言的語句以及該語句的概率值。?
RNNs中的語音識別研究論文:
- Towards End-to-End Speech Recognition with Recurrent Neural Networks
圖像描述生成
和卷積神經網絡(convolutional Neural Networks, CNNs)一樣,RNNs已經在對無標圖像描述自動生成中得到應用。將CNNs與RNNs結合進行圖像描述自動生成。這是一個非常神奇的研究與應用。該組合模型能夠根據圖像的特征生成描述。如下圖所示:?
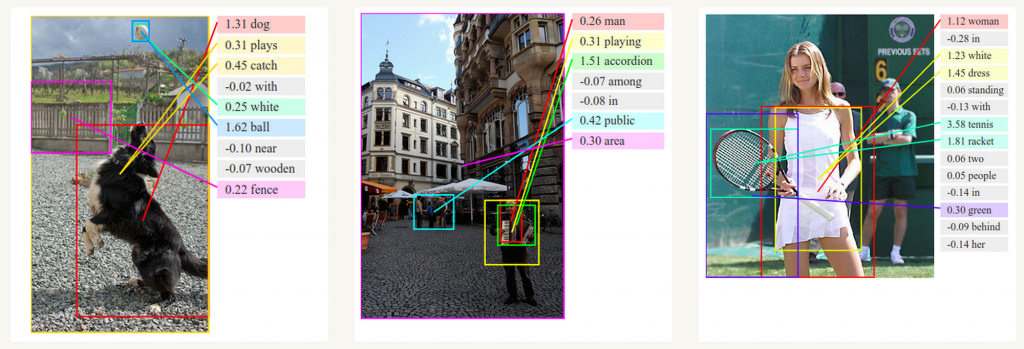
圖像描述生成中的深度視覺語義對比.?Image Source
文本相似度計算等 。。。。。
循環神經網絡 RNN 結構
循環神經網絡是一類用于處理序列數據的神經網絡,就像卷積神經網絡是專門用于處理網格化數據(如一張圖像)的神經網絡,循環神經網絡時專門用于處理序列? 的神經網絡。
同一個神經元在不同時刻的狀態構成了RNN神經網絡,簡化版的RNN結構如下:

循環神經網絡的結果相比于卷積神經網絡較簡單,通常循環神經網絡只包含輸入層、隱藏層和輸出層,加上輸入輸出層最多也就5層
以樣本 ‘我是誰’? 為例,體會一下

將一個神經元序列按時間展開就可以得到RNN的結構
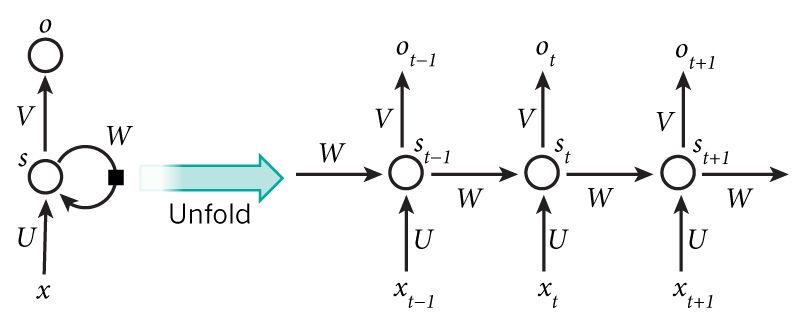
- 網絡某一時刻 t 的輸入
,和之前介紹的 bp 神經網絡的輸入一樣,
,…,
,
,…
?代表時刻 t 隱神經元對于線性轉換值
?是時間 t 處的“記憶”,
,f() 可以是非線性轉換函數,比如 tanh 等, 通常我們把?
?代表時刻t的輸出(神經元激活后的輸出結果),比如是預測下一個詞的話,可能是 sigmoid(softmax) 輸出的屬于每個候選詞的概率,
- 輸入層到隱藏層直接的權重由U表示,它將我們的原始輸入進行抽象作為隱藏層的輸入
- 隱藏層到隱藏層的權重W,它是網絡的記憶控制者,負責調度記憶。
- 隱藏層到輸出層的權重V,從隱藏層學習到的表示將通過它再一次抽象,并作為最終輸出
循環神經網絡RNN-BPTT?
RNN 的訓練和 CNN/ANN 訓練一樣,同樣適用 BP算法誤差反向傳播算法。區別在于:RNN中的參數U\V\W是共享的,并且在隨機梯度下降算法中,每一步的輸出不僅僅依賴當前步的網絡,并且還需要前若干步網絡的狀態,那么這種BP改版的算法叫做Backpropagation Through Time(BPTT);BPTT算法和BP算法一樣,在多層訓練過程中(長時依賴<即當前的輸出和前面很長的一段序列有關,一般超過10步>),可能產生梯度消失和梯度爆炸的問題。
BPTT和BP算法思路一樣,都是求偏導,區別在于需要考慮時間對step的影響。
RNN正向傳播階段
在t=1的時刻,U,V,W都被隨機初始化好,h0通常初始化為0,然后進行如下計算:
時間就向前推進,此時的狀態 h1 作為時刻 t=1?的記憶狀態將參與下一次的預測活動,也就是:
以此類推,可得任意時刻t,神經元的計算過程
其中 f 可以是 tanh,relu,sigmoid?等激活函數, g 通常是 softmax,也可以是其他。 值得注意的是,我們說循環神經網絡擁有記憶能力,而這種能力就是通過 W 將以往的輸入狀態進行總結,而作為下次輸入的輔助,可以這樣理解隱藏狀態:h=f(現有的輸入+過去記憶總結)
RNN反向傳播階段
bp神經網絡用到 誤差反向傳播 方法將輸出層的誤差總和,對各個權重的梯度 ?U,?V,?W,求偏導數,然后利用梯度下降法更新各個權重。
對于每一時刻 t 的 RNN 網絡,網絡的輸出??都會產生一定誤差?
?,誤差的損失函數,可以是交叉熵也可以是平方誤差等等。那么總的誤差為
,我們的目標就是要求取各個權重(U、V、W)對總誤差的偏導
求V的偏導
對于輸出?,任意損失函數,求?V是非常簡單的,我們可以直接求取每個時刻的?
,由于它不存在和之前的狀態依賴,可以直接求導取得,然后簡單地求和即可。對于?W、?U的計算不能直接求導,需要用鏈式求導法則。
求w的偏導



求U的偏導

RNN 缺點
假如?t = 0 時刻的值,到?t = 100? 時,由于前面的?W 次數過大,又可能會使其忘記?t = 0 時刻的信息,我們稱之為?RNN梯度消失,但是不是真正意思上的消失,因為梯度是累加的過程,不可能為0,只是在某個時刻的梯度太小,忘記了前面時刻的內容
為了克服梯度消失的問題,LSTM和GRU模型便后續被推出了,LSTM和GRU都有特殊的方式存儲”記憶”,以前梯度比較大的”記憶”不會像RNN一樣馬上被抹除,因此可以一定程度上克服梯度消失問題。
另一個簡單的技巧 gradient clipping(梯度截取) 可以用來克服梯度爆炸的問題,也就是當你計算的梯度超過閾值c的或者小于閾值?c時候,便把此時的梯度設置成c或?c
下圖所示是RNN的誤差平面,可以看到RNN的誤差平面要么非常陡峭,要么非常平坦,如果不采取任何措施,當你的參數在某一次更新之后,剛好碰到陡峭的地方,此時梯度變得非常大,那么你的參數更新也會非常大,很容易導致震蕩問題。而如果你采取了gradient clipping,那么即使你不幸碰到陡峭的地方,梯度也不會爆炸,因為梯度被限制在某個閾值c

雙向RNN Bidirectional RNN
Bidirectional RNN(雙向RNN)假設當前t的輸出不僅僅和之前的序列有關,并且還與之后的序列有關,例如:預測一個語句中缺失的詞語那么需要根據上下文進行預測;Bidirectional RNN是一個相對簡單的RNNs,由兩個RNNs上下疊加在 一起組成。輸出由這兩個RNNs的隱藏層的狀態決定

或者如下圖

深度雙向 RNN
Deep Bidirectional RNN(深度雙向RNN)類似Bidirectional RNN,區別在于每個每一步的輸入有多層網絡,這樣的話該網絡便具有更加強大的表達能力和學習能力,但是復雜性也提高了,同時需要訓練更多的數據。












...)
)
)


:報表導出,對比poi、jxl和esayExcel的效率...)


