AlexNet 是 2012年ILSVRC 比賽冠軍,遠超第二名的CNN,比LeNet更深,用多層小卷積疊加來替換單個的大卷積,結構如下圖所示。
??

結構
預處理
-
原始圖片:256?256?3256*256*3256?256?3
-
圖像處理:
- 1.隨機的剪切,將 256?256256*256256?256 的圖片剪切成為 224?224224*224224?224 的圖片
- 2.對 224?224224*224224?224 的圖像做了一些旋轉和位置變換
- 3.對 224?224224*224224?224 的圖像做了一個圖像大小的擴大,變成 227?227227*227227?227 的圖片
-
備注:實際輸入AlexNet網絡的圖片是一個 227?227?3227*227*3227?227?3 的圖片信息
-
激勵函數:論文中是:sigmoid,但是實際比賽的時候,使用的是ReLU
-
總參數量:60956032
L0:輸入層
- input:227?227?3227*227*3227?227?3
- output:227?227?3227*227*3227?227?3
L1 卷積+激勵
- input:227?227?3227*227*3227?227?3
- filter:3?11?113*11*113?11?11
- stripe:444
- padding:000
- filter size/depth:48?248*248?2
- output:55?55?48?255*55*48*255?55?48?2
- 神經元數目:55?55?48?255*55*48*255?55?48?2
- 參數個數:(3?11?11+1)?48?2=34944(3*11*11+1)*48*2=34944(3?11?11+1)?48?2=34944
- 連接方式:
- 使用雙GPU來進行卷積操作,這個卷積操作和普通卷積一樣
- 兩個GPU并行的進行卷積操作,每個GPU只負責其中48個卷積核的計算
- 效果:可以并行的計算模型,模型執行效率可以得到提升,并且將GPU之間的通信放到網絡結構偏后的位置,可以降低信號傳輸的損耗"
L2 最大池化
- input:55?55?48?255*55*48*255?55?48?2
- filter:3?33*33?3
- stripe:222
- padding:000
- output:27?27?48?227*27*48*227?27?48?2
- 參數個數:000
L3 卷積+激勵
- input:27?27?48?227*27*48*227?27?48?2
- filter:5?5?485*5*485?5?48
- stripe:111
- padding:222 上下左右各加2個像素
- filter size/depth:128?2128*2128?2
- output:27?27?128?227*27*128*227?27?128?2
- 神經元數目:27?27?128?227*27*128*227?27?128?2
- 參數個數:(5?5?48+1)?128?2=307456(5*5*48+1)*128*2=307456(5?5?48+1)?128?2=307456
- 連接方式:各個GPU中對應各自的48個feature map進行卷積過程,和普通卷積一樣
L4 最大池化
- input:27?27?128?227*27*128*227?27?128?2
- filter:3?33*33?3
- stripe:222
- padding:000
- output:13?13?128?213*13*128*213?13?128?2
- 參數個數:000
L5 卷積+激勵
- input:13?13?128?213*13*128*213?13?128?2
- filter:3?3?2563*3*2563?3?256
- stripe:111
- padding:222
- filter size/depth:192?2192*2192?2
- output:13?13?192?213*13*192*213?13?192?2
- 神經元數目:13?13?192?213*13*192*213?13?192?2
- 參數個數:(3?3?256+1)?192?2=885120(3*3*256+1)*192*2=885120(3?3?256+1)?192?2=885120
- 連接方式:將兩個GPU中的256個feature map一起做卷積過程
L6 卷積+激勵
- input:13?13?192?213*13*192*213?13?192?2
- filter:3?3?1923*3*1923?3?192
- stripe:111
- padding:222
- filter size/depth:192?2192*2192?2
- output:13?13?192?213*13*192*213?13?192?2
- 神經元數目:13?13?192?213*13*192*213?13?192?2
- 參數個數:(3?3?192+1)?192?2=663936(3*3*192+1)*192*2=663936(3?3?192+1)?192?2=663936
- 連接方式:各個GPU中對應各自的48個feature map進行卷積過程,和普通卷積一樣
L7 卷積+激勵
- input:13?13?192?213*13*192*213?13?192?2
- filter:3?3?1923*3*1923?3?192
- stripe:111
- padding:222
- filter size/depth:128?2128*2128?2
- output:13?13?128?213*13*128*213?13?128?2
- 神經元數目:13?13?128?213*13*128*213?13?128?2
- 參數個數:(3?3?192+1)?128?2=442624(3*3*192+1)*128*2=442624(3?3?192+1)?128?2=442624
- 連接方式:各個GPU中對應各自的48個feature map進行卷積過程,和普通卷積一樣
L8 最大池化
- input:13?13?128?213*13*128*213?13?128?2
- filter:3?33*33?3
- stripe:222
- padding:000
- output:6?6?128?26*6*128*26?6?128?2
- 參數個數:000
L9 全連接+激勵
- input:921692169216
- output:2048?22048*22048?2
- 參數個數:9216?2048?2=377487369216*2048*2=377487369216?2048?2=37748736
L10 全連接+激勵
- input:409640964096
- output:2048?22048*22048?2
- 參數個數:4096?4096=167772164096*4096=167772164096?4096=16777216
L11 全連接+激勵
- input:409640964096
- output:100010001000
- 參數個數:4096?1000=40960004096*1000=40960004096?1000=4096000
AlexNet結構優化
非線性激活函數:ReLU
使用Max Pooling,并且提出池化核和步長,使池化核之間存在重疊,提升了特征的豐富性。
防止過擬合的方法:Dropout,Data augmentation(數據增強)
大數據訓練:百萬級ImageNet圖像數據
GPU實現:在每個GPU中放置一半核(或神經元),還有一個額外的技巧:GPU間的通訊只在某些層進行。
LRN歸一化:對局部神經元的活動創建了競爭機制,使得其中響應比較大的值變得相對更大,并抑制其它反饋較小的神經元,增強了模型的泛化能力。本質上,LRN是仿造生物學上活躍的神經元對于相鄰神經元的抑制現象(側抑制)
??
在AlexNet引入了一種特殊的網絡層次,即:Local Response Normalization(LRN, 局部響應歸一化),主要是對ReLU激活函數的輸出進行局部歸一化操作,公式如下:
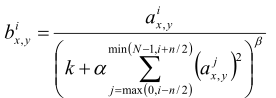
其中a表示第i個卷積核在(x,y)坐標位置經過激活函數的輸出值,這個式子的含義就是輸出一個值和它前后的n個值做標準化。k、n、α、β是超參數,在AlexNet網絡中分別為:2、5、10^-4、0.75,N為卷積核總數。
)


 函數,計算某個字符串,并執行其中的的 JavaScript 代碼。)
![vb整合多個excel表格到一張_[Excel]同一工作簿中多個工作表保存成獨立的表格](http://pic.xiahunao.cn/vb整合多個excel表格到一張_[Excel]同一工作簿中多個工作表保存成獨立的表格)



)








)

)