2014年,牛津大學計算機視覺組(Visual Geometry Group)和Google DeepMind公司的研究員一起研發出了新的深度卷積神經網絡:VGGNet,并取得了ILSVRC2014比賽分類項目的第二名(第一名是GoogLeNet,也是同年提出的)和定位項目的第一名。
VGGNet探索了卷積神經網絡的深度與其性能之間的關系,成功地構筑了16~19層深的卷積神經網絡,證明了增加網絡的深度能夠在一定程度上影響網絡最終的性能,使錯誤率大幅下降,同時拓展性又很強,遷移到其它圖片數據上的泛化性也非常好。到目前為止,VGG仍然被用來提取圖像特征。
VGGNet可以看成是加深版本的AlexNet,都是由卷積層、全連接層兩大部分構成。
下圖是來自論文《Very Deep Convolutional Networks for Large-Scale Image Recognition》(基于甚深層卷積網絡的大規模圖像識別)的VGG網絡結構,正是在這篇論文中提出了VGG,如下圖:

在這篇論文中分別使用了A、A-LRN、B、C、D、E這6種網絡結構進行測試,這6種網絡結構相似,都是由5層卷積層、3層全連接層組成,其中區別在于每個卷積層的子層數量不同,從A至E依次增加(子層數量從1到4),總的網絡深度從11層到19層(添加的層以粗體顯示),表格中的卷積層參數表示為“conv?感受野大小?-通道數?”,例如con3-128,表示使用3x3的卷積核,通道數為128。為了簡潔起見,在表格中不顯示ReLU激活功能。
其中,網絡結構D就是著名的VGG16,網絡結構E就是著名的VGG19。
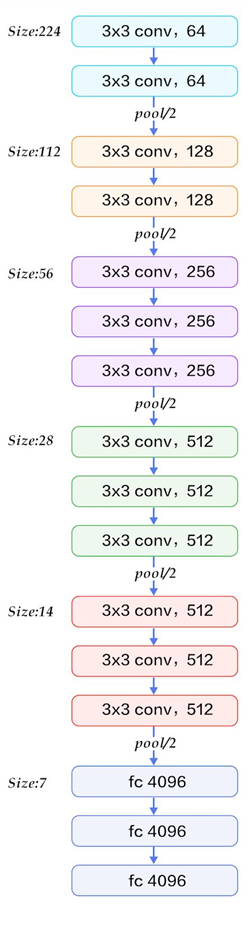
以網絡結構D(VGG16)為例,介紹其處理過程如下,請對比上面的表格和下方這張圖,留意圖中的數字變化,有助于理解VGG16的處理過程:

1、輸入224x224x3的圖片,經64個3x3的卷積核作兩次卷積+ReLU,卷積后的尺寸變為224x224x64
2、作max pooling(最大化池化),池化單元尺寸為2x2(效果為圖像尺寸減半),池化后的尺寸變為112x112x64
3、經128個3x3的卷積核作兩次卷積+ReLU,尺寸變為112x112x128
4、作2x2的max pooling池化,尺寸變為56x56x128
5、經256個3x3的卷積核作三次卷積+ReLU,尺寸變為56x56x256
6、作2x2的max pooling池化,尺寸變為28x28x256
7、經512個3x3的卷積核作三次卷積+ReLU,尺寸變為28x28x512
8、作2x2的max pooling池化,尺寸變為14x14x512
9、經512個3x3的卷積核作三次卷積+ReLU,尺寸變為14x14x512
10、作2x2的max pooling池化,尺寸變為7x7x512
11、與兩層1x1x4096,一層1x1x1000進行全連接+ReLU(共三層)
12、通過softmax輸出1000個預測結果
以上就是VGG16(網絡結構D)各層的處理過程,A、A-LRN、B、C、E其它網絡結構的處理過程也是類似,執行過程如下(以VGG16為例):

從上面的過程可以看出VGG網絡結構還是挺簡潔的,都是由小卷積核、小池化核、ReLU組合而成。其簡化圖如下(以VGG16為例):
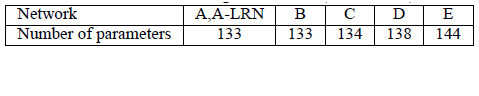
A、A-LRN、B、C、D、E這6種網絡結構的深度雖然從11層增加至19層,但參數量變化不大,這是由于基本上都是采用了小卷積核(3x3,只有9個參數),這6種結構的參數數量(百萬級)并未發生太大變化,這是因為在網絡中,參數主要集中在全連接層。
經作者對A、A-LRN、B、C、D、E這6種網絡結構進行單尺度的評估,錯誤率結果如下:

從上表可以看出:
1、LRN層無性能增益(A-LRN)
VGG作者通過網絡A-LRN發現,AlexNet曾經用到的LRN層(local response normalization,局部響應歸一化)并沒有帶來性能的提升,因此在其它組的網絡中均沒再出現LRN層。
2、隨著深度增加,分類性能逐漸提高(A、B、C、D、E)
從11層的A到19層的E,網絡深度增加對top1和top5的錯誤率下降很明顯。
3、多個小卷積核比單個大卷積核性能好(B)
VGG作者做了實驗用B和自己一個不在實驗組里的較淺網絡比較,較淺網絡用conv5x5來代替B的兩個conv3x3,結果顯示多個小卷積核比單個大卷積核效果要好。
最后進行個小結:
1、通過增加深度能有效地提升性能;
2、最佳模型:VGG16,從頭到尾只有3x3卷積與2x2池化,簡潔優美;
3、卷積可代替全連接,可適應各種尺寸的圖片






)

)

)






- 區域候選網絡)

