Statistical Learning
Y?和X的關系
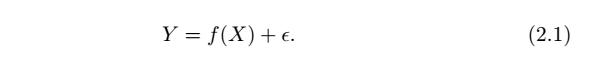
why estimate f
- 用來預測?
預測的時候可以將f^當成一個black box來用,目的主要是預測對應x時候的y而不關系它們之間的關系。 - 用來推斷?
推斷的時候,f^不能是一個black box,因為我們想知道predictor和response之間的關系,用來做特征提取,關系分析等。? ? ?
根據目的是預測還是推斷或者兩者結合選擇不同的模型,需要做一下trade off。
how estimate f
- 參數方法?
它將確定了f的形式,將估計p維的f函數降為了對一些參數的估計?
先構建參數表達式,然后用參數表達式去訓練數據,例如linear regression。?
優點是模型和計算簡單,缺點是預先確定了f的形式,可能會和真實的f相差較大。? ? ? - 非參數方法
對f的形式并未做假設,它要求得到的結果與訓練集越接近越好,但是保證模型不要太過復雜。?
優點是適用于更多的f,能夠得到更高的正確率,缺點是因為是無參數估計,所以需要的數據量是很大的。
The Trade-Off Between Prediction Accuracy and Model?
Interpretability
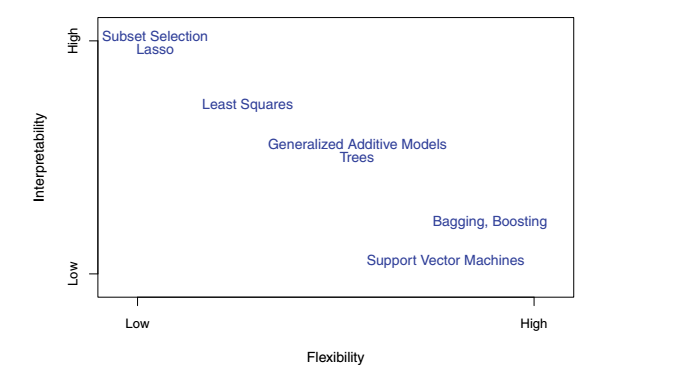
- Subset Selction Lasso(最難理解)
- Least Squares
- Generallized Additive Models Trees
- Bagging,Boosting
- SVM(最靈活)
模型越復雜,對于模型的可解釋度越小。
如果需要對模型進行高精度預測的話,比如股票市場,可以采用更flexible的方法。?
然而,在股票市場,高精度的方法有時候效果更差,原因是對訓練數據產生了過擬合。
?
Supervised Versus Unsupervised Learning
Regression Versus Classification Problems
以上兩部分的內容在Ng的ML課程中有詳細的介紹
?
二??Assessing model Accuracy
1 Measuring quality of fit
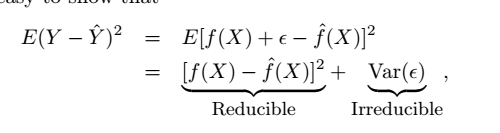
?
均方誤差?MSE
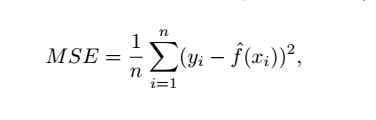
MSE越小越好
The Bias-Variance Trade-Off
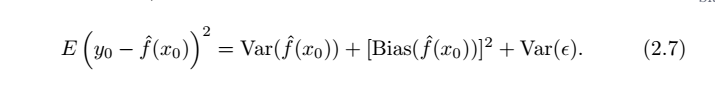
(1)?公式中第一項是預測的方差(variance),表示了如果我們更換一個訓練集,預測函數f(x)的變化程度,一般來說,自由度越高的方法具有越大的方差;
(2)?第二項是預測的偏差(?bias),某種學習算法的平均估計結果所能逼近學習目標的程度一般來講,自由度越高的方法具有越小的偏差;?獨立于訓練樣本的誤差,刻畫了匹配的準確性和質量:一個高的偏差意味著一個壞的匹配
(3)?最后一項是不可消除偏差。
訓練充足后,訓練數據的輕微擾動都會導致學習器發生顯著變化,發生過擬合。?
當方差和偏差加起來最優的點,就是我們最佳的模型復雜度。
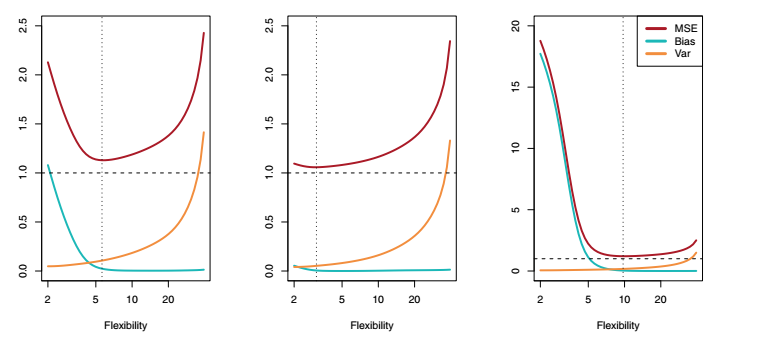
紅色的曲線代表了MSE,橘黃色曲線代表方差,藍色的曲線代表偏差,水平虛線代表了不可消除偏差,豎直虛線代表了模型實際的自由度。
2 classification setting
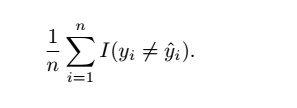
? ? 訓練錯誤率
? ?(1)bayes classifier
條件概率
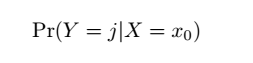
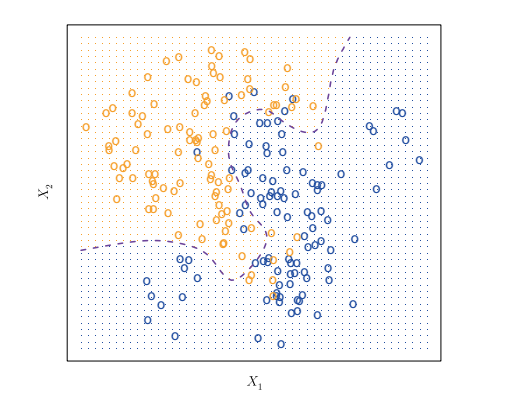
貝葉斯錯誤率
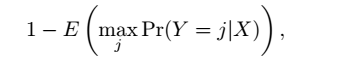
? ?(2)K-Nearest Neighbors(KNN)
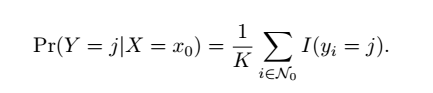
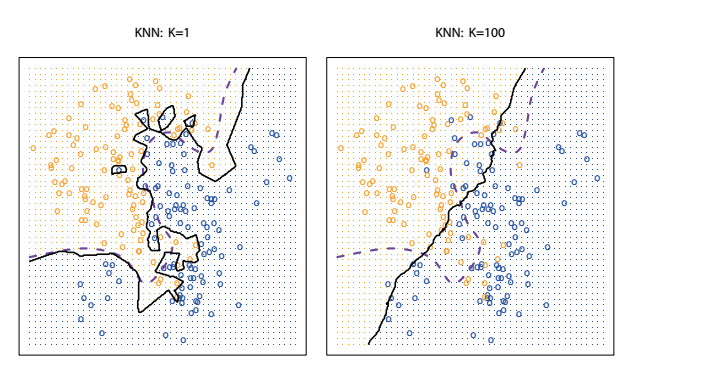
理論上,我們偏愛貝葉斯分類器去得到最優的模型。?
但是實際上,我們并不知道特定點X對應的Y分布,因此不能夠直接使用貝葉斯分類器。?
但是,有很多方法,可以人工地構造條件概率分布,然后接著使用貝葉斯分類器。
KNN雖然很簡單,但是它的錯誤率卻可以很逼近最低的錯誤率
R—exercise



















-可變形卷積)